 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeA Study on Bias Detection and Classification in Natural Language Processing
Aug 14, 2024
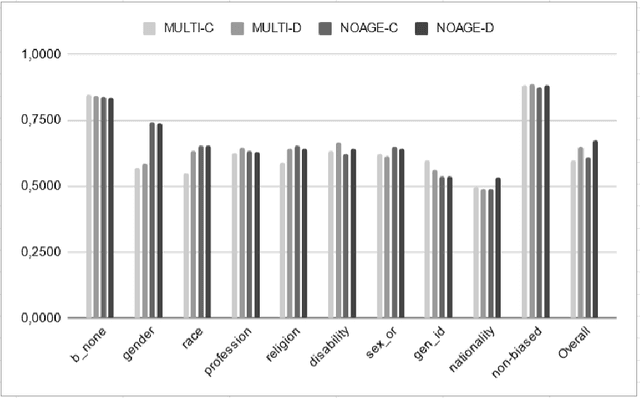
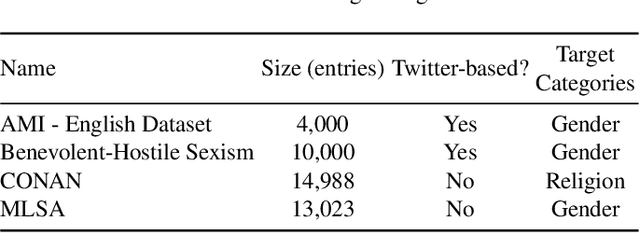
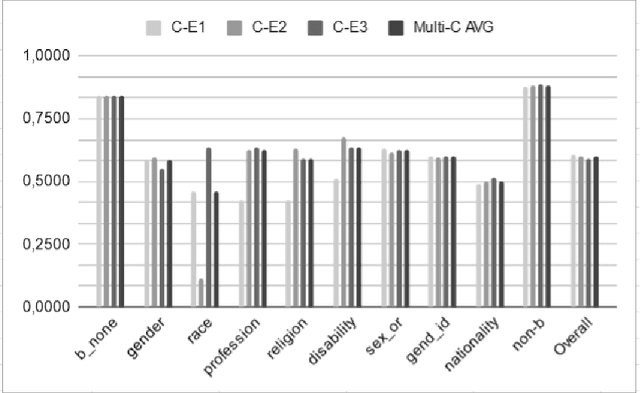
Human biases have been shown to influence the performance of models and algorithms in various fields, including Natural Language Processing. While the study of this phenomenon is garnering focus in recent years, the available resources are still relatively scarce, often focusing on different forms or manifestations of biases. The aim of our work is twofold: 1) gather publicly-available datasets and determine how to better combine them to effectively train models in the task of hate speech detection and classification; 2) analyse the main issues with these datasets, such as scarcity, skewed resources, and reliance on non-persistent data. We discuss these issues in tandem with the development of our experiments, in which we show that the combinations of different datasets greatly impact the models' performance.
ConText at WASSA 2024 Empathy and Personality Shared Task: History-Dependent Embedding Utterance Representations for Empathy and Emotion Prediction in Conversations
Jul 04, 2024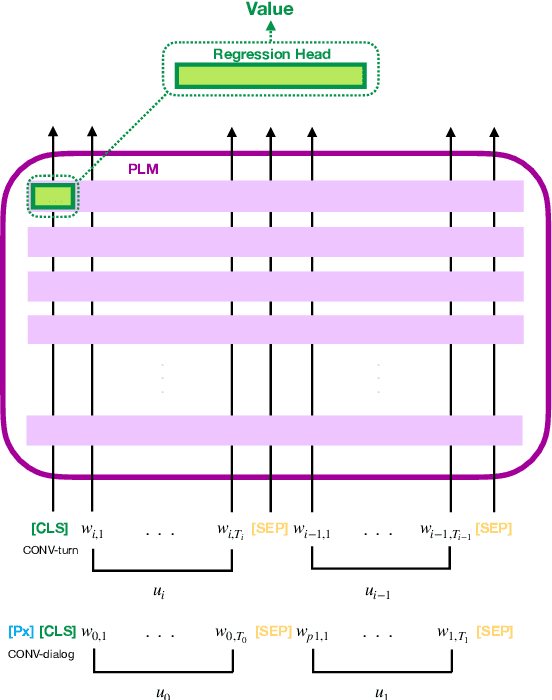

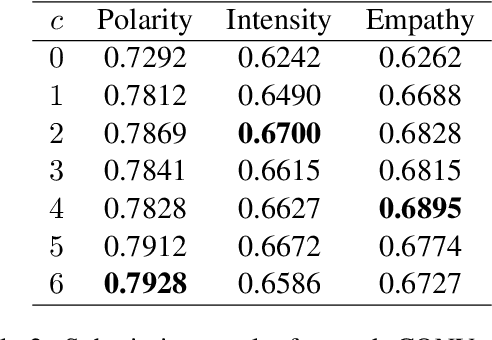
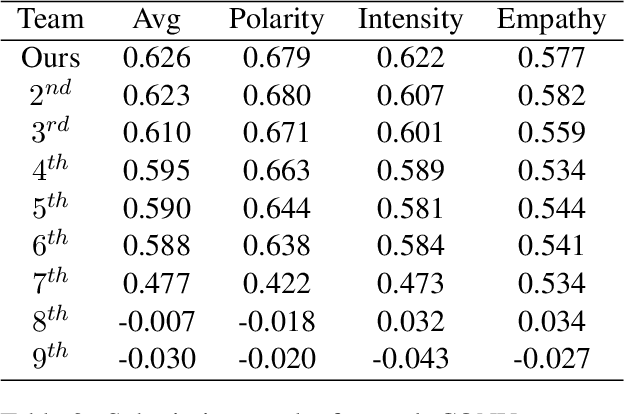
Empathy and emotion prediction are key components in the development of effective and empathetic agents, amongst several other applications. The WASSA shared task on empathy and emotion prediction in interactions presents an opportunity to benchmark approaches to these tasks. Appropriately selecting and representing the historical context is crucial in the modelling of empathy and emotion in conversations. In our submissions, we model empathy, emotion polarity and emotion intensity of each utterance in a conversation by feeding the utterance to be classified together with its conversational context, i.e., a certain number of previous conversational turns, as input to an encoder Pre-trained Language Model, to which we append a regression head for prediction. We also model perceived counterparty empathy of each interlocutor by feeding all utterances from the conversation and a token identifying the interlocutor for which we are predicting the empathy. Our system officially ranked $1^{st}$ at the CONV-turn track and $2^{nd}$ at the CONV-dialog track.
Dialogue Quality and Emotion Annotations for Customer Support Conversations
Nov 23, 2023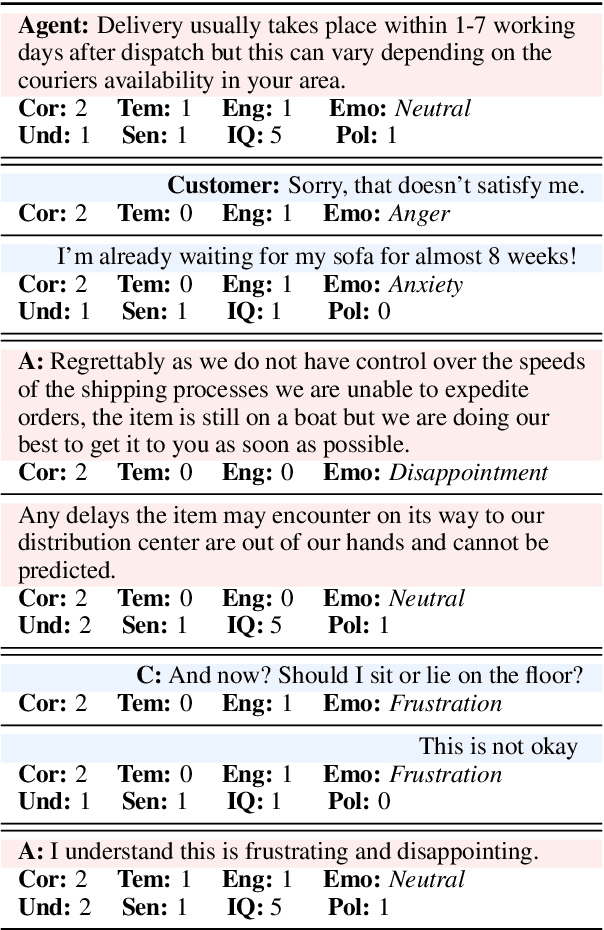
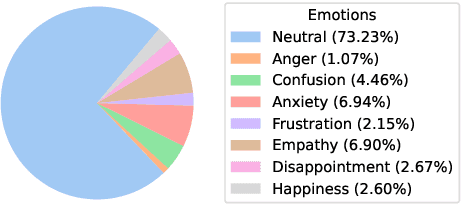

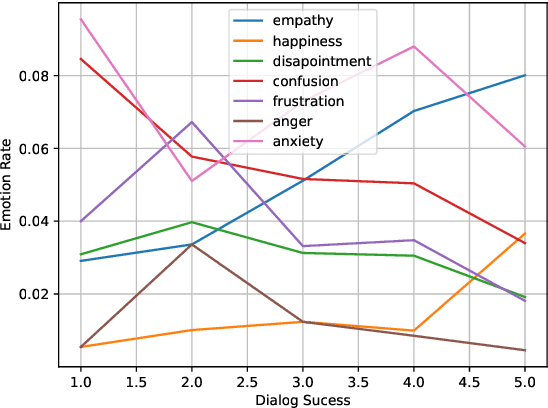
Task-oriented conversational datasets often lack topic variability and linguistic diversity. However, with the advent of Large Language Models (LLMs) pretrained on extensive, multilingual and diverse text data, these limitations seem overcome. Nevertheless, their generalisability to different languages and domains in dialogue applications remains uncertain without benchmarking datasets. This paper presents a holistic annotation approach for emotion and conversational quality in the context of bilingual customer support conversations. By performing annotations that take into consideration the complete instances that compose a conversation, one can form a broader perspective of the dialogue as a whole. Furthermore, it provides a unique and valuable resource for the development of text classification models. To this end, we present benchmarks for Emotion Recognition and Dialogue Quality Estimation and show that further research is needed to leverage these models in a production setting.
Simple LLM Prompting is State-of-the-Art for Robust and Multilingual Dialogue Evaluation
Sep 08, 2023
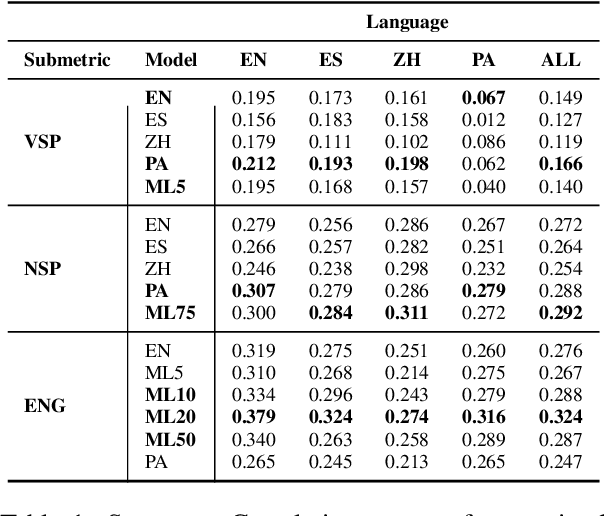


Despite significant research effort in the development of automatic dialogue evaluation metrics, little thought is given to evaluating dialogues other than in English. At the same time, ensuring metrics are invariant to semantically similar responses is also an overlooked topic. In order to achieve the desired properties of robustness and multilinguality for dialogue evaluation metrics, we propose a novel framework that takes advantage of the strengths of current evaluation models with the newly-established paradigm of prompting Large Language Models (LLMs). Empirical results show our framework achieves state of the art results in terms of mean Spearman correlation scores across several benchmarks and ranks first place on both the Robust and Multilingual tasks of the DSTC11 Track 4 "Automatic Evaluation Metrics for Open-Domain Dialogue Systems", proving the evaluation capabilities of prompted LLMs.
Fuzzy Fingerprinting Transformer Language-Models for Emotion Recognition in Conversations
Sep 08, 2023Fuzzy Fingerprints have been successfully used as an interpretable text classification technique, but, like most other techniques, have been largely surpassed in performance by Large Pre-trained Language Models, such as BERT or RoBERTa. These models deliver state-of-the-art results in several Natural Language Processing tasks, namely Emotion Recognition in Conversations (ERC), but suffer from the lack of interpretability and explainability. In this paper, we propose to combine the two approaches to perform ERC, as a means to obtain simpler and more interpretable Large Language Models-based classifiers. We propose to feed the utterances and their previous conversational turns to a pre-trained RoBERTa, obtaining contextual embedding utterance representations, that are then supplied to an adapted Fuzzy Fingerprint classification module. We validate our approach on the widely used DailyDialog ERC benchmark dataset, in which we obtain state-of-the-art level results using a much lighter model.
Context-Dependent Embedding Utterance Representations for Emotion Recognition in Conversations
Apr 17, 2023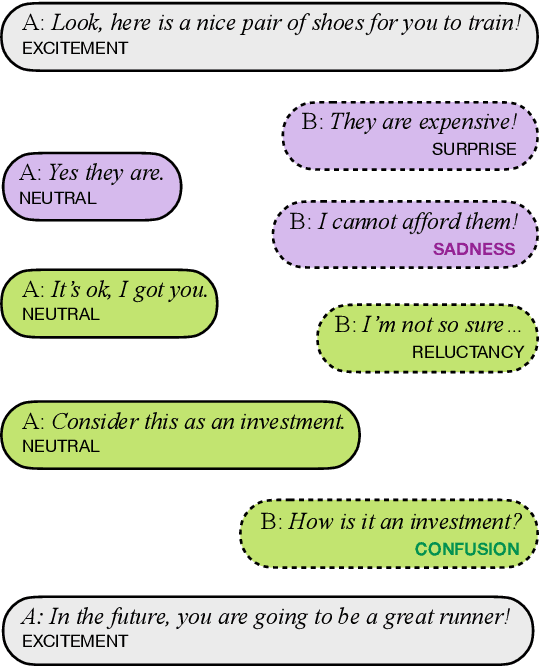

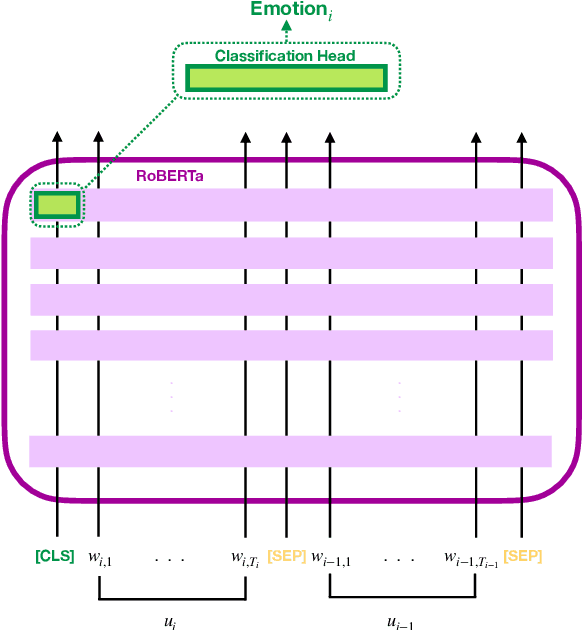
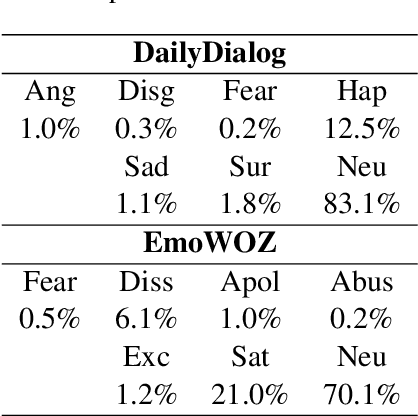
Emotion Recognition in Conversations (ERC) has been gaining increasing importance as conversational agents become more and more common. Recognizing emotions is key for effective communication, being a crucial component in the development of effective and empathetic conversational agents. Knowledge and understanding of the conversational context are extremely valuable for identifying the emotions of the interlocutor. We thus approach Emotion Recognition in Conversations leveraging the conversational context, i.e., taking into attention previous conversational turns. The usual approach to model the conversational context has been to produce context-independent representations of each utterance and subsequently perform contextual modeling of these. Here we propose context-dependent embedding representations of each utterance by leveraging the contextual representational power of pre-trained transformer language models. In our approach, we feed the conversational context appended to the utterance to be classified as input to the RoBERTa encoder, to which we append a simple classification module, thus discarding the need to deal with context after obtaining the embeddings since these constitute already an efficient representation of such context. We also investigate how the number of introduced conversational turns influences our model performance. The effectiveness of our approach is validated on the widely used open-domain DailyDialog dataset and on the task-oriented EmoWOZ dataset, for which we attain state-of-the-art results, surpassing ERC models also resorting to RoBERTa but with more complex classification modules, indicating that our context-dependent embedding utterance representation approach with a simple classification model can be more effective than context-independent utterance representation approaches with more complex classification modules.
A Simple Feature Method for Prosody Rhythm Comparison
Dec 20, 2022

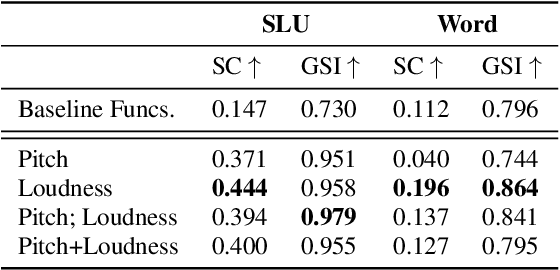

Of all components of Prosody, Rhythm has been regarded as the hardest to address, as it is utterly linked to Pitch and Intensity. Nevertheless, Rhythm is a very good indicator of a speaker's fluency in a foreign language or even of some diseases. Canonical ways to measure Rhythm, such as $\Delta C$ or $\%V$, involve a cumbersome process of segment alignment, often leading to modest and questionable results. Perceptively, however, rhythm does not sound as difficult, as humans can grasp it even when the text is not fully intelligible. In this work, we develop an empirical and unsupervised method of rhythm assessment, which does not rely on the content. We have created a fixed-length representation of each utterance, Peak Embedding (PE), which codifies the proportional distance between peaks of the chosen Low-Level Descriptors. Clustering pairs of small sentence-like units, we have attained averages of 0.444 for Silhouette Coefficient using PE with Loudness, and 0.979 for Global Separability Index with a combination of PE with Pitch and Loudness. Clustering same-structure words, we have attained averages of 0.196 for Silhouette Coefficient and 0.864 for Global Separability Index for PE with Loudness.
Deep Emotion Recognition in Textual Conversations: A Survey
Nov 16, 2022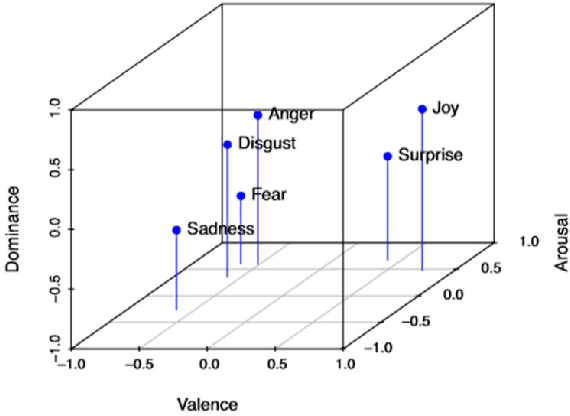
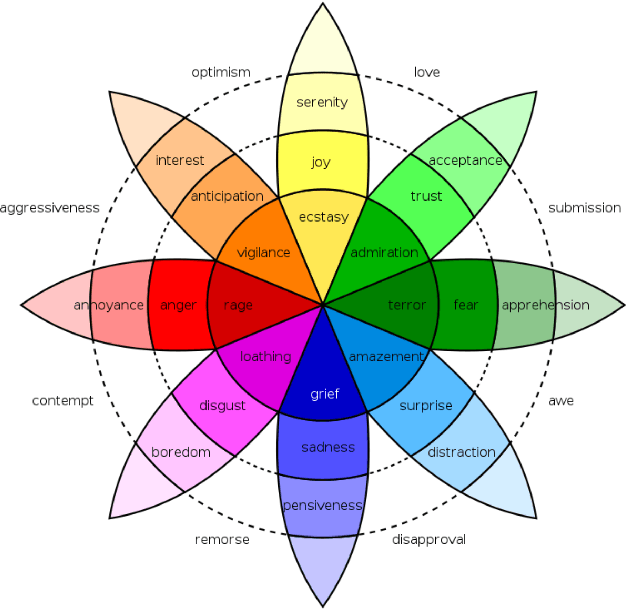
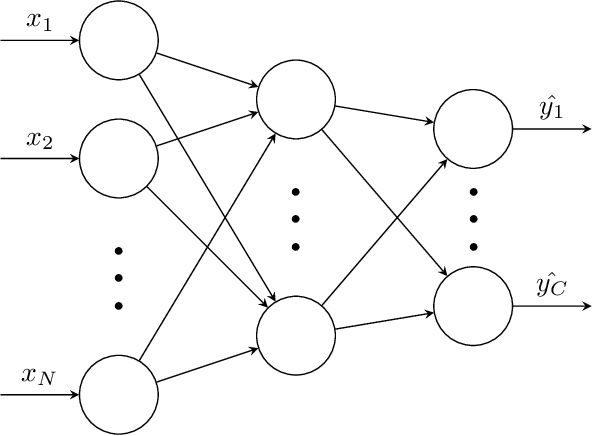
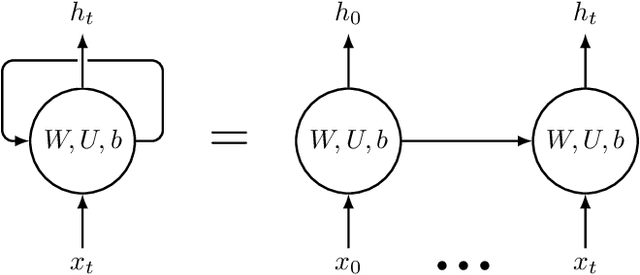
While Emotion Recognition in Conversations (ERC) has seen a tremendous advancement in the last few years, new applications and implementation scenarios present novel challenges and opportunities. These range from leveraging the conversational context, speaker and emotion dynamics modelling, to interpreting common sense expressions, informal language and sarcasm, addressing challenges of real time ERC and recognizing emotion causes. This survey starts by introducing ERC, elaborating on the challenges and opportunities pertaining to this task. It proceeds with a description of the main emotion taxonomies and methods to deal with subjectivity in annotations. It then describes Deep Learning methods relevant for ERC, word embeddings, and elaborates on the use of performance metrics for the task and methods to deal with the typically unbalanced ERC datasets. This is followed by a description and benchmark of key ERC works along with comprehensive tables comparing several works regarding their methods and performance across different datasets. The survey highlights the advantage of leveraging techniques to address unbalanced data, the exploration of mixed emotions and the benefits of incorporating annotation subjectivity in the learning phase.
Retrieval Augmentation to Improve Robustness and Interpretability of Deep Neural Networks
Feb 25, 2021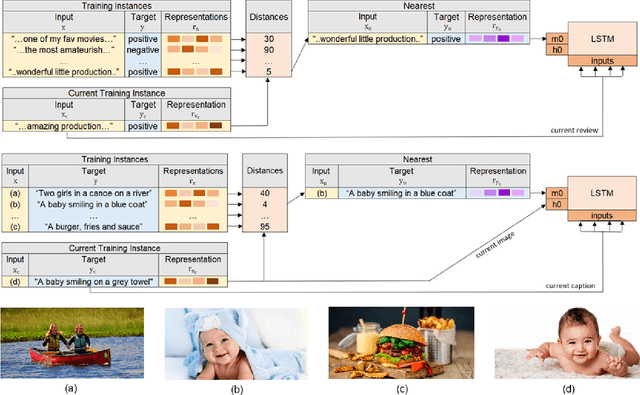
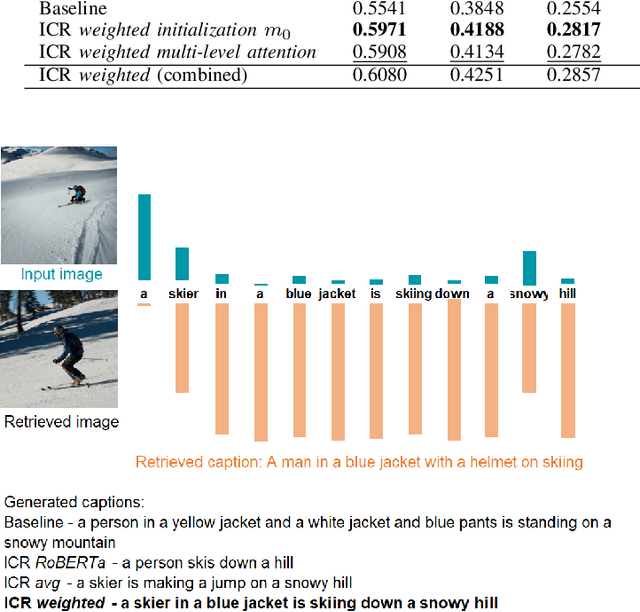


Deep neural network models have achieved state-of-the-art results in various tasks related to vision and/or language. Despite the use of large training data, most models are trained by iterating over single input-output pairs, discarding the remaining examples for the current prediction. In this work, we actively exploit the training data to improve the robustness and interpretability of deep neural networks, using the information from nearest training examples to aid the prediction both during training and testing. Specifically, the proposed approach uses the target of the nearest input example to initialize the memory state of an LSTM model or to guide attention mechanisms. We apply this approach to image captioning and sentiment analysis, conducting experiments with both image and text retrieval. Results show the effectiveness of the proposed models for the two tasks, on the widely used Flickr8 and IMDB datasets, respectively. Our code is publicly available http://github.com/RitaRamo/retrieval-augmentation-nn.
Towards Using Machine Translation Techniques to Induce Multilingual Lexica of Discourse Markers
Mar 31, 2015Discourse markers are universal linguistic events subject to language variation. Although an extensive literature has already reported language specific traits of these events, little has been said on their cross-language behavior and on building an inventory of multilingual lexica of discourse markers. This work describes new methods and approaches for the description, classification, and annotation of discourse markers in the specific domain of the Europarl corpus. The study of discourse markers in the context of translation is crucial due to the idiomatic nature of these structures. Multilingual lexica together with the functional analysis of such structures are useful tools for the hard task of translating discourse markers into possible equivalents from one language to another. Using Daniel Marcu's validated discourse markers for English, extracted from the Brown Corpus, our purpose is to build multilingual lexica of discourse markers for other languages, based on machine translation techniques. The major assumption in this study is that the usage of a discourse marker is independent of the language, i.e., the rhetorical function of a discourse marker in a sentence in one language is equivalent to the rhetorical function of the same discourse marker in another language.