 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeA Study on Bias Detection and Classification in Natural Language Processing
Aug 14, 2024
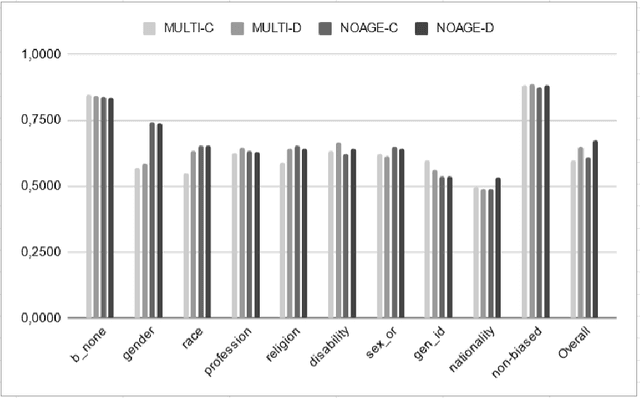
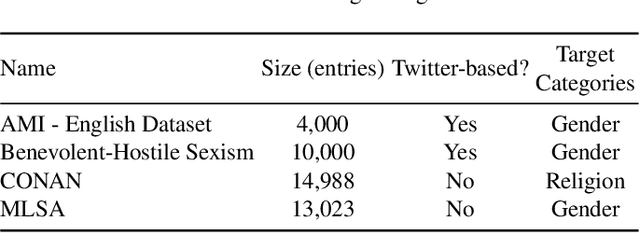
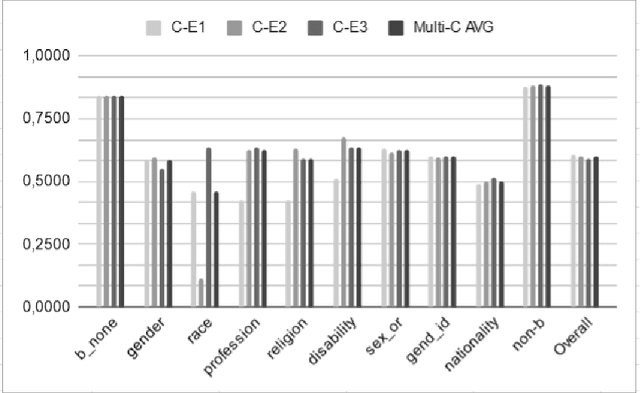
Human biases have been shown to influence the performance of models and algorithms in various fields, including Natural Language Processing. While the study of this phenomenon is garnering focus in recent years, the available resources are still relatively scarce, often focusing on different forms or manifestations of biases. The aim of our work is twofold: 1) gather publicly-available datasets and determine how to better combine them to effectively train models in the task of hate speech detection and classification; 2) analyse the main issues with these datasets, such as scarcity, skewed resources, and reliance on non-persistent data. We discuss these issues in tandem with the development of our experiments, in which we show that the combinations of different datasets greatly impact the models' performance.