 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSpeaker Fuzzy Fingerprints: Benchmarking Text-Based Identification in Multiparty Dialogues
Apr 21, 2025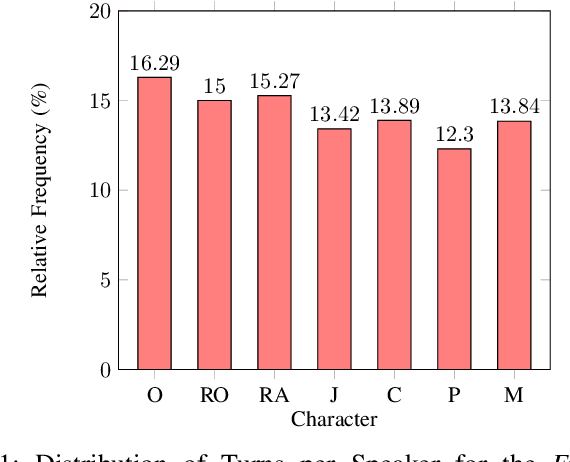
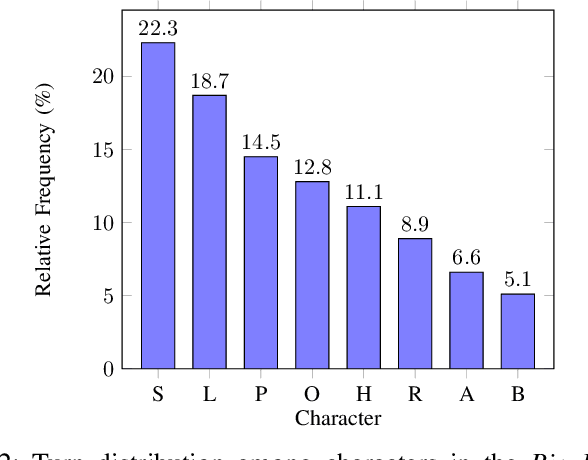
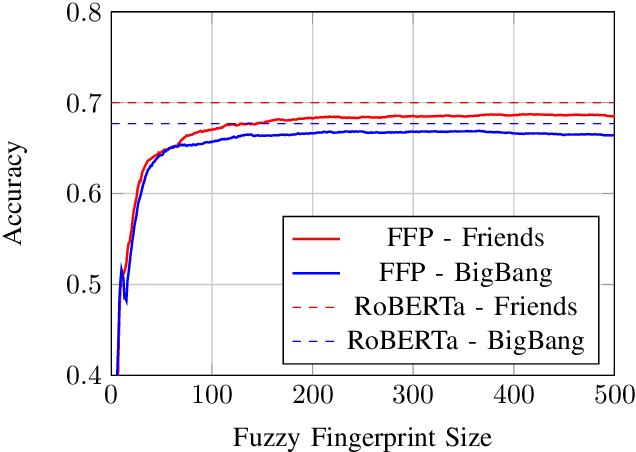
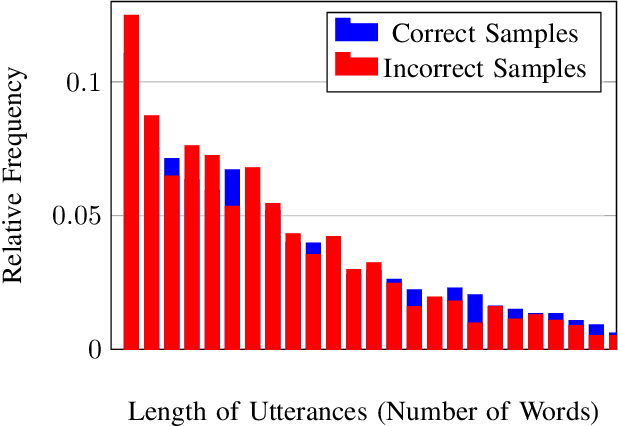
Speaker identification using voice recordings leverages unique acoustic features, but this approach fails when only textual data is available. Few approaches have attempted to tackle the problem of identifying speakers solely from text, and the existing ones have primarily relied on traditional methods. In this work, we explore the use of fuzzy fingerprints from large pre-trained models to improve text-based speaker identification. We integrate speaker-specific tokens and context-aware modeling, demonstrating that conversational context significantly boosts accuracy, reaching 70.6% on the Friends dataset and 67.7% on the Big Bang Theory dataset. Additionally, we show that fuzzy fingerprints can approximate full fine-tuning performance with fewer hidden units, offering improved interpretability. Finally, we analyze ambiguous utterances and propose a mechanism to detect speaker-agnostic lines. Our findings highlight key challenges and provide insights for future improvements in text-based speaker identification.
A Study on Bias Detection and Classification in Natural Language Processing
Aug 14, 2024
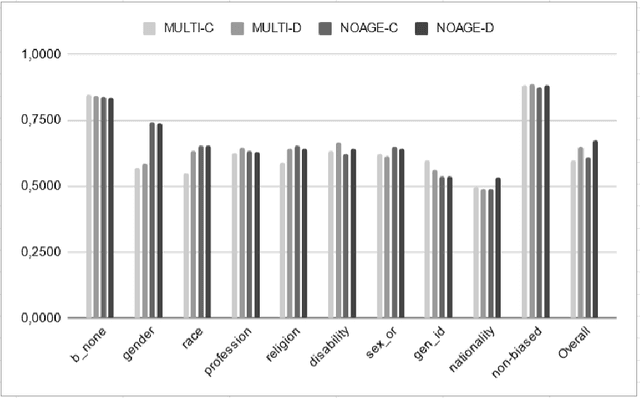
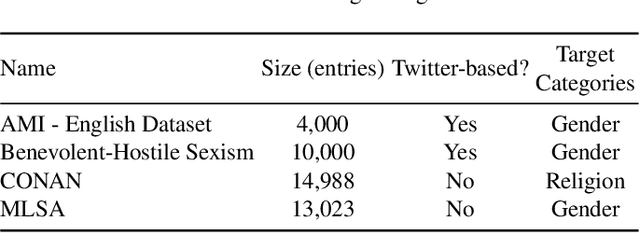
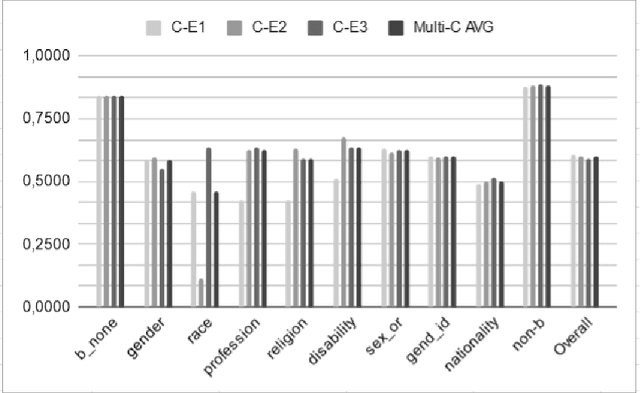
Human biases have been shown to influence the performance of models and algorithms in various fields, including Natural Language Processing. While the study of this phenomenon is garnering focus in recent years, the available resources are still relatively scarce, often focusing on different forms or manifestations of biases. The aim of our work is twofold: 1) gather publicly-available datasets and determine how to better combine them to effectively train models in the task of hate speech detection and classification; 2) analyse the main issues with these datasets, such as scarcity, skewed resources, and reliance on non-persistent data. We discuss these issues in tandem with the development of our experiments, in which we show that the combinations of different datasets greatly impact the models' performance.
From Brazilian Portuguese to European Portuguese
Aug 14, 2024Brazilian Portuguese and European Portuguese are two varieties of the same language and, despite their close similarities, they exhibit several differences. However, there is a significant disproportion in the availability of resources between the two variants, with Brazilian Portuguese having more abundant resources. This inequity can impact the quality of translation services accessible to European Portuguese speakers. To address this issue, we propose the development of a Brazilian Portuguese to European Portuguese translation system, leveraging recent advancements in neural architectures and models. To evaluate the performance of such systems, we manually curated a gold test set comprising 500 sentences across five different topics. Each sentence in the gold test set has two distinct references, facilitating a straightforward evaluation of future translation models. We experimented with various models by fine-tuning existing Large Language Models using parallel data extracted from movie subtitles and TED Talks transcripts in both Brazilian and European Portuguese. Our evaluation involved the use of conventional automatic metrics as well as a human evaluation. In addition, all models were compared against ChatGPT 3.5 Turbo, which currently yields the best results.
PGTask: Introducing the Task of Profile Generation from Dialogues
Apr 13, 2023

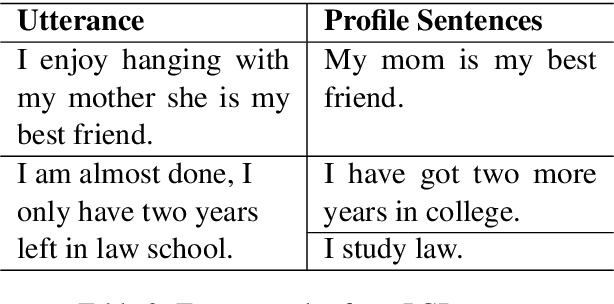
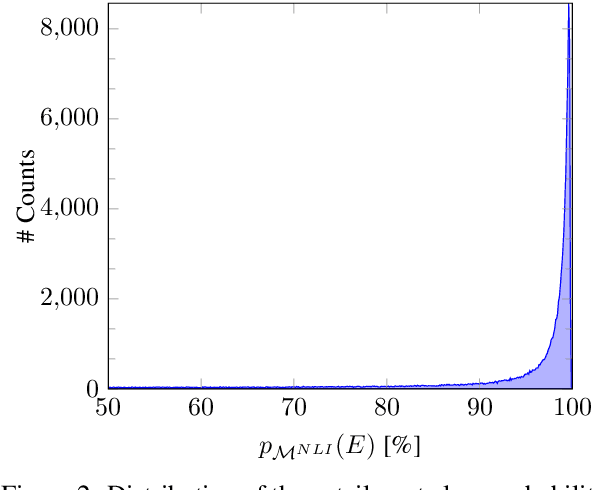
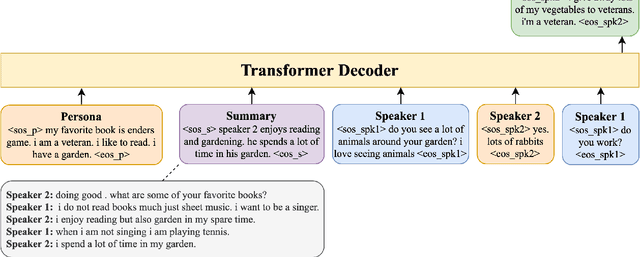
Recent approaches have attempted to personalize dialogue systems by leveraging profile information into models. However, this knowledge is scarce and difficult to obtain, which makes the extraction/generation of profile information from dialogues a fundamental asset. To surpass this limitation, we introduce the Profile Generation Task (PGTask). We contribute with a new dataset for this problem, comprising profile sentences aligned with related utterances, extracted from a corpus of dialogues. Furthermore, using state-of-the-art methods, we provide a benchmark for profile generation on this novel dataset. Our experiments disclose the challenges of profile generation, and we hope that this introduces a new research direction.
SUMBot: Summarizing Context in Open-Domain Dialogue Systems
Oct 12, 2022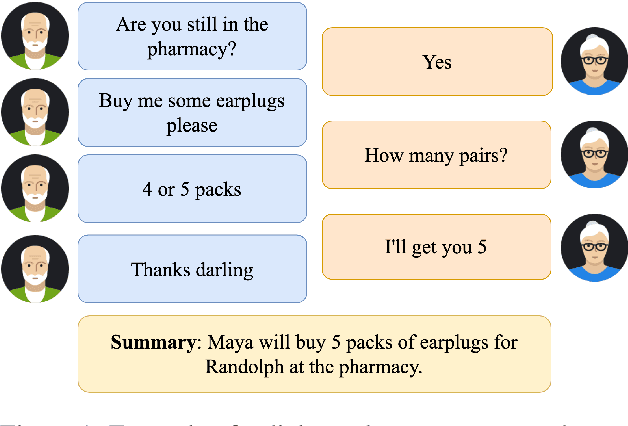
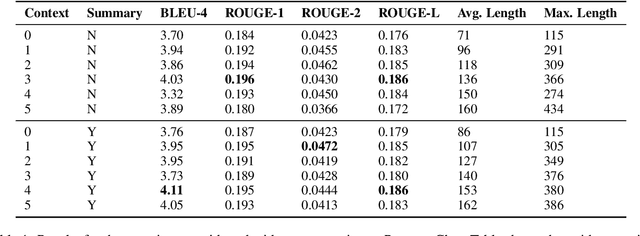
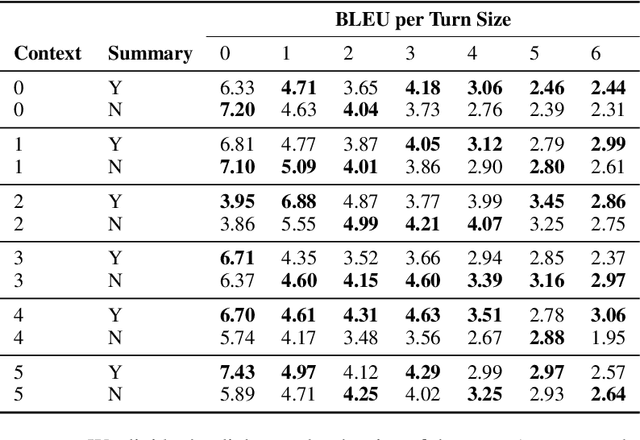
In this paper, we investigate the problem of including relevant information as context in open-domain dialogue systems. Most models struggle to identify and incorporate important knowledge from dialogues and simply use the entire turns as context, which increases the size of the input fed to the model with unnecessary information. Additionally, due to the input size limitation of a few hundred tokens of large pre-trained models, regions of the history are not included and informative parts from the dialogue may be omitted. In order to surpass this problem, we introduce a simple method that substitutes part of the context with a summary instead of the whole history, which increases the ability of models to keep track of all the previous relevant information. We show that the inclusion of a summary may improve the answer generation task and discuss some examples to further understand the system's weaknesses.
Question rewriting? Assessing its importance for conversational question answering
Jan 22, 2022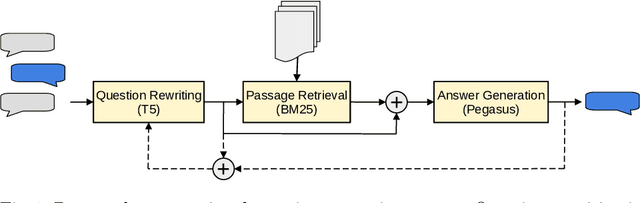
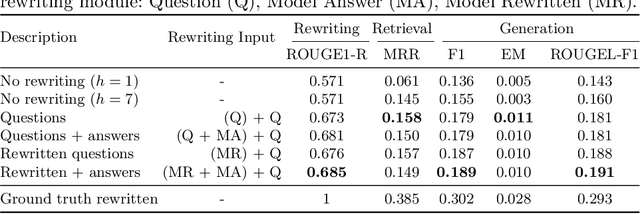
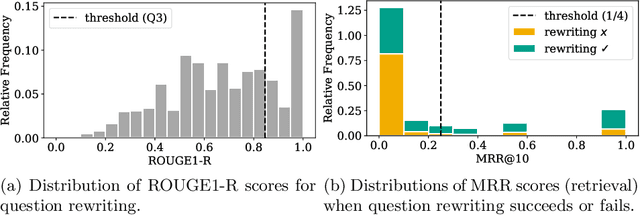
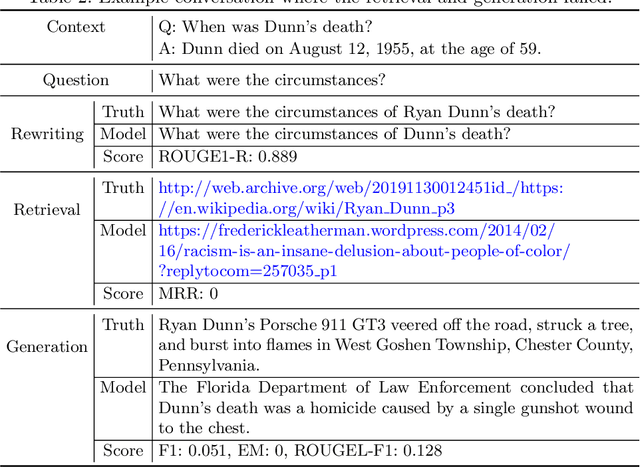
In conversational question answering, systems must correctly interpret the interconnected interactions and generate knowledgeable answers, which may require the retrieval of relevant information from a background repository. Recent approaches to this problem leverage neural language models, although different alternatives can be considered in terms of modules for (a) representing user questions in context, (b) retrieving the relevant background information, and (c) generating the answer. This work presents a conversational question answering system designed specifically for the Search-Oriented Conversational AI (SCAI) shared task, and reports on a detailed analysis of its question rewriting module. In particular, we considered different variations of the question rewriting module to evaluate the influence on the subsequent components, and performed a careful analysis of the results obtained with the best system configuration. Our system achieved the best performance in the shared task and our analysis emphasizes the importance of the conversation context representation for the overall system performance.
Learning to answer questions
Sep 04, 2013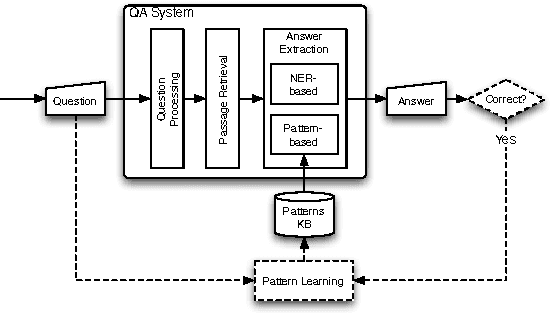
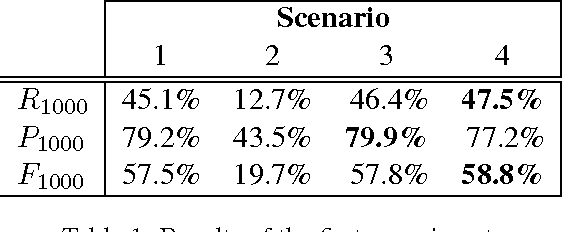
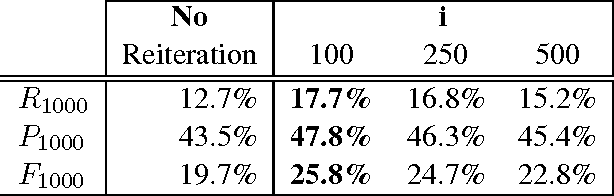
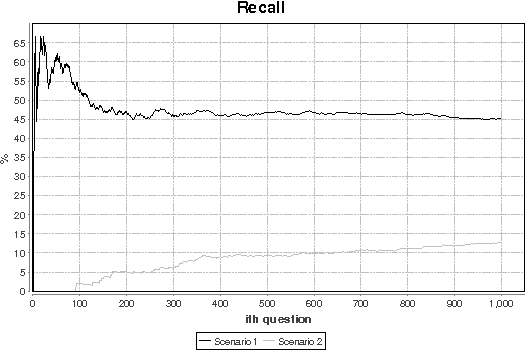
We present an open-domain Question-Answering system that learns to answer questions based on successful past interactions. We follow a pattern-based approach to Answer-Extraction, where (lexico-syntactic) patterns that relate a question to its answer are automatically learned and used to answer future questions. Results show that our approach contributes to the system's best performance when it is conjugated with typical Answer-Extraction strategies. Moreover, it allows the system to learn with the answered questions and to rectify wrong or unsolved past questions.
Towards the Rapid Development of a Natural Language Understanding Module
Feb 06, 2013


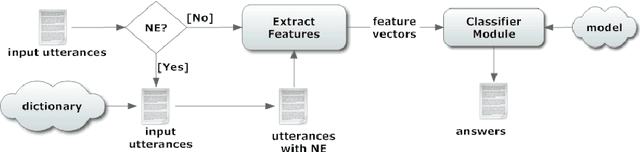
When developing a conversational agent, there is often an urgent need to have a prototype available in order to test the application with real users. A Wizard of Oz is a possibility, but sometimes the agent should be simply deployed in the environment where it will be used. Here, the agent should be able to capture as many interactions as possible and to understand how people react to failure. In this paper, we focus on the rapid development of a natural language understanding module by non experts. Our approach follows the learning paradigm and sees the process of understanding natural language as a classification problem. We test our module with a conversational agent that answers questions in the art domain. Moreover, we show how our approach can be used by a natural language interface to a cinema database.