 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAgentic Search in the Wild: Intents and Trajectory Dynamics from 14M+ Real Search Requests
Jan 24, 2026LLM-powered search agents are increasingly being used for multi-step information seeking tasks, yet the IR community lacks empirical understanding of how agentic search sessions unfold and how retrieved evidence is used. This paper presents a large-scale log analysis of agentic search based on 14.44M search requests (3.97M sessions) collected from DeepResearchGym, i.e. an open-source search API accessed by external agentic clients. We sessionize the logs, assign session-level intents and step-wise query-reformulation labels using LLM-based annotation, and propose Context-driven Term Adoption Rate (CTAR) to quantify whether newly introduced query terms are traceable to previously retrieved evidence. Our analyses reveal distinctive behavioral patterns. First, over 90% of multi-turn sessions contain at most ten steps, and 89% of inter-step intervals fall under one minute. Second, behavior varies by intent. Fact-seeking sessions exhibit high repetition that increases over time, while sessions requiring reasoning sustain broader exploration. Third, agents reuse evidence across steps. On average, 54% of newly introduced query terms appear in the accumulated evidence context, with contributions from earlier steps beyond the most recent retrieval. The findings suggest that agentic search may benefit from repetition-aware early stopping, intent-adaptive retrieval budgets, and explicit cross-step context tracking. We plan to release the anonymized logs to support future research.
An Efficient and Effective Encoder Model for Vision and Language Tasks in the Remote Sensing Domain
Dec 17, 2025The remote sensing community has recently seen the emergence of methods based on Large Vision and Language Models (LVLMs) that can address multiple tasks at the intersection of computer vision and natural language processing. To fully exploit the potential of such models, a significant focus has been given to the collection of large amounts of training data that cover multiple remote sensing-specific tasks, such as image captioning or visual question answering. However, the cost of using and training LVLMs is high, due to the large number of parameters. While multiple parameter-efficient adaptation techniques have been explored, the computational costs of training and inference with these models can remain prohibitive for most institutions. In this work, we explore the use of encoder-only architectures and propose a model that can effectively address multi-task learning while remaining compact in terms of the number of parameters. In particular, our model tackles combinations of tasks that are not typically explored in a unified model: the generation of text from remote sensing images and cross-modal retrieval. The results of our GeoMELT model - named from Multi-task Efficient Learning Transformer - in established benchmarks confirm the efficacy and efficiency of the proposed approach.
Generalized Referring Expression Segmentation on Aerial Photos
Dec 08, 2025Referring expression segmentation is a fundamental task in computer vision that integrates natural language understanding with precise visual localization of target regions. Considering aerial imagery (e.g., modern aerial photos collected through drones, historical photos from aerial archives, high-resolution satellite imagery, etc.) presents unique challenges because spatial resolution varies widely across datasets, the use of color is not consistent, targets often shrink to only a few pixels, and scenes contain very high object densities and objects with partial occlusions. This work presents Aerial-D, a new large-scale referring expression segmentation dataset for aerial imagery, comprising 37,288 images with 1,522,523 referring expressions that cover 259,709 annotated targets, spanning across individual object instances, groups of instances, and semantic regions covering 21 distinct classes that range from vehicles and infrastructure to land coverage types. The dataset was constructed through a fully automatic pipeline that combines systematic rule-based expression generation with a Large Language Model (LLM) enhancement procedure that enriched both the linguistic variety and the focus on visual details within the referring expressions. Filters were additionally used to simulate historic imaging conditions for each scene. We adopted the RSRefSeg architecture, and trained models on Aerial-D together with prior aerial datasets, yielding unified instance and semantic segmentation from text for both modern and historical images. Results show that the combined training achieves competitive performance on contemporary benchmarks, while maintaining strong accuracy under monochrome, sepia, and grainy degradations that appear in archival aerial photography. The dataset, trained models, and complete software pipeline are publicly available at https://luispl77.github.io/aerial-d .
Comprehension of Multilingual Expressions Referring to Target Objects in Visual Inputs
Nov 14, 2025Referring Expression Comprehension (REC) requires models to localize objects in images based on natural language descriptions. Research on the area remains predominantly English-centric, despite increasing global deployment demands. This work addresses multilingual REC through two main contributions. First, we construct a unified multilingual dataset spanning 10 languages, by systematically expanding 12 existing English REC benchmarks through machine translation and context-based translation enhancement. The resulting dataset comprises approximately 8 million multilingual referring expressions across 177,620 images, with 336,882 annotated objects. Second, we introduce an attention-anchored neural architecture that uses multilingual SigLIP2 encoders. Our attention-based approach generates coarse spatial anchors from attention distributions, which are subsequently refined through learned residuals. Experimental evaluation demonstrates competitive performance on standard benchmarks, e.g. achieving 86.9% accuracy at IoU@50 on RefCOCO aggregate multilingual evaluation, compared to an English-only result of 91.3%. Multilingual evaluation shows consistent capabilities across languages, establishing the practical feasibility of multilingual visual grounding systems. The dataset and model are available at $\href{https://multilingual.franreno.com}{multilingual.franreno.com}$.
A Vision for Geo-Temporal Deep Research Systems: Towards Comprehensive, Transparent, and Reproducible Geo-Temporal Information Synthesis
Jun 17, 2025The emergence of Large Language Models (LLMs) has transformed information access, with current LLMs also powering deep research systems that can generate comprehensive report-style answers, through planned iterative search, retrieval, and reasoning. Still, current deep research systems lack the geo-temporal capabilities that are essential for answering context-rich questions involving geographic and/or temporal constraints, frequently occurring in domains like public health, environmental science, or socio-economic analysis. This paper reports our vision towards next generation systems, identifying important technical, infrastructural, and evaluative challenges in integrating geo-temporal reasoning into deep research pipelines. We argue for augmenting retrieval and synthesis processes with the ability to handle geo-temporal constraints, supported by open and reproducible infrastructures and rigorous evaluation protocols. Our vision outlines a path towards more advanced and geo-temporally aware deep research systems, of potential impact to the future of AI-driven information access.
DeepResearchGym: A Free, Transparent, and Reproducible Evaluation Sandbox for Deep Research
May 25, 2025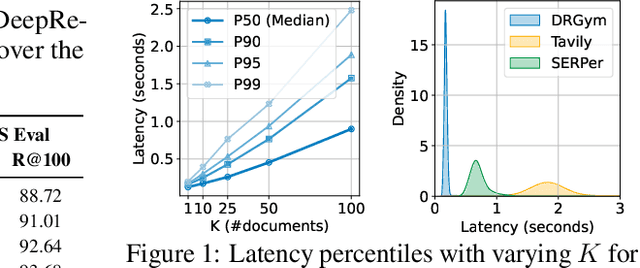
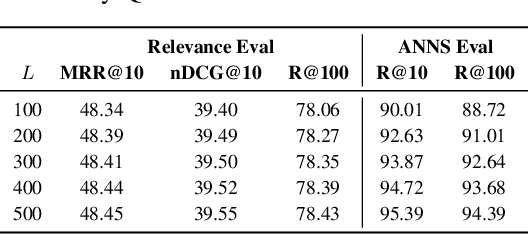
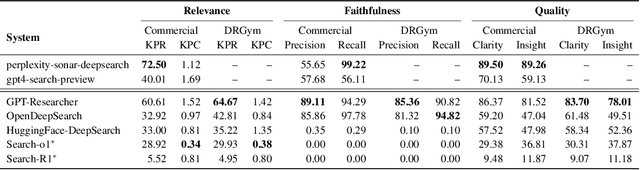
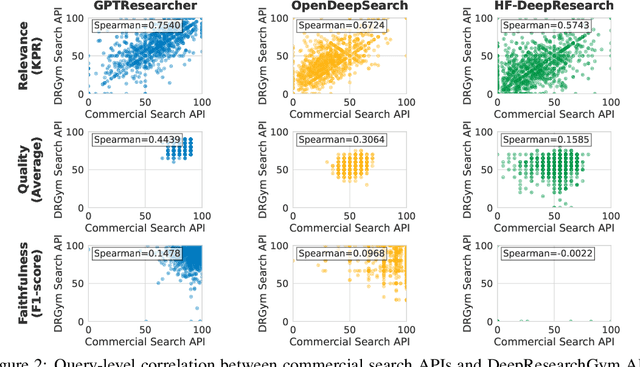
Deep research systems represent an emerging class of agentic information retrieval methods that generate comprehensive and well-supported reports to complex queries. However, most existing frameworks rely on dynamic commercial search APIs, which pose reproducibility and transparency challenges in addition to their cost. To address these limitations, we introduce DeepResearchGym, an open-source sandbox that combines a reproducible search API with a rigorous evaluation protocol for benchmarking deep research systems. The API indexes large-scale public web corpora, namely ClueWeb22 and FineWeb, using a state-of-the-art dense retriever and approximate nearest neighbor search via DiskANN. It achieves lower latency than popular commercial APIs while ensuring stable document rankings across runs, and is freely available for research use. To evaluate deep research systems' outputs, we extend the Researchy Questions benchmark with automatic metrics through LLM-as-a-judge assessments to measure alignment with users' information needs, retrieval faithfulness, and report quality. Experimental results show that systems integrated with DeepResearchGym achieve performance comparable to those using commercial APIs, with performance rankings remaining consistent across evaluation metrics. A human evaluation study further confirms that our automatic protocol aligns with human preferences, validating the framework's ability to help support controlled assessment of deep research systems. Our code and API documentation are available at https://www.deepresearchgym.ai.
Aligning Web Query Generation with Ranking Objectives via Direct Preference Optimization
May 25, 2025Neural retrieval models excel in Web search, but their training requires substantial amounts of labeled query-document pairs, which are costly to obtain. With the widespread availability of Web document collections like ClueWeb22, synthetic queries generated by large language models offer a scalable alternative. Still, synthetic training queries often vary in quality, which leads to suboptimal downstream retrieval performance. Existing methods typically filter out noisy query-document pairs based on signals from an external re-ranker. In contrast, we propose a framework that leverages Direct Preference Optimization (DPO) to integrate ranking signals into the query generation process, aiming to directly optimize the model towards generating high-quality queries that maximize downstream retrieval effectiveness. Experiments show higher ranker-assessed relevance between query-document pairs after DPO, leading to stronger downstream performance on the MS~MARCO benchmark when compared to baseline models trained with synthetic data.
A Conformal Risk Control Framework for Granular Word Assessment and Uncertainty Calibration of CLIPScore Quality Estimates
Apr 01, 2025This study explores current limitations of learned image captioning evaluation metrics, specifically the lack of granular assessment for individual word misalignments within captions, and the reliance on single-point quality estimates without considering uncertainty. To address these limitations, we propose a simple yet effective strategy for generating and calibrating CLIPScore distributions. Leveraging a model-agnostic conformal risk control framework, we calibrate CLIPScore values for task-specific control variables, to tackle the aforementioned two limitations. Experimental results demonstrate that using conformal risk control, over the distributions produced with simple methods such as input masking, can achieve competitive performance compared to more complex approaches. Our method effectively detects misaligned words, while providing formal guarantees aligned with desired risk levels, and improving the correlation between uncertainty estimations and prediction errors, thus enhancing the overall reliability of caption evaluation metrics.
Explainable ICD Coding via Entity Linking
Mar 26, 2025Clinical coding is a critical task in healthcare, although traditional methods for automating clinical coding may not provide sufficient explicit evidence for coders in production environments. This evidence is crucial, as medical coders have to make sure there exists at least one explicit passage in the input health record that justifies the attribution of a code. We therefore propose to reframe the task as an entity linking problem, in which each document is annotated with its set of codes and respective textual evidence, enabling better human-machine collaboration. By leveraging parameter-efficient fine-tuning of Large Language Models (LLMs), together with constrained decoding, we introduce three approaches to solve this problem that prove effective at disambiguating clinical mentions and that perform well in few-shot scenarios.
From TOWER to SPIRE: Adding the Speech Modality to a Text-Only LLM
Mar 13, 2025Large language models (LLMs) have shown remarkable performance and generalization capabilities across multiple languages and tasks, making them very attractive targets for multi-modality integration (e.g., images or speech). In this work, we extend an existing LLM to the speech modality via speech discretization and continued pre-training. In particular, we are interested in multilingual LLMs, such as TOWER, as their pre-training setting allows us to treat discretized speech input as an additional translation language. The resulting open-source model, SPIRE, is able to transcribe and translate English speech input while maintaining TOWER's original performance on translation-related tasks, showcasing that discretized speech input integration as an additional language is feasible during LLM adaptation. We make our code and models available to the community.