 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAn Efficient and Effective Encoder Model for Vision and Language Tasks in the Remote Sensing Domain
Dec 17, 2025The remote sensing community has recently seen the emergence of methods based on Large Vision and Language Models (LVLMs) that can address multiple tasks at the intersection of computer vision and natural language processing. To fully exploit the potential of such models, a significant focus has been given to the collection of large amounts of training data that cover multiple remote sensing-specific tasks, such as image captioning or visual question answering. However, the cost of using and training LVLMs is high, due to the large number of parameters. While multiple parameter-efficient adaptation techniques have been explored, the computational costs of training and inference with these models can remain prohibitive for most institutions. In this work, we explore the use of encoder-only architectures and propose a model that can effectively address multi-task learning while remaining compact in terms of the number of parameters. In particular, our model tackles combinations of tasks that are not typically explored in a unified model: the generation of text from remote sensing images and cross-modal retrieval. The results of our GeoMELT model - named from Multi-task Efficient Learning Transformer - in established benchmarks confirm the efficacy and efficiency of the proposed approach.
Beyond the Noise: Aligning Prompts with Latent Representations in Diffusion Models
Dec 09, 2025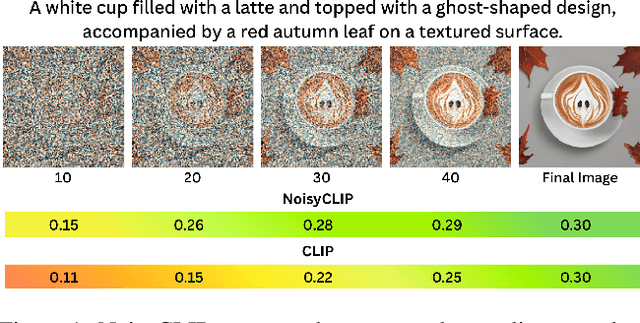
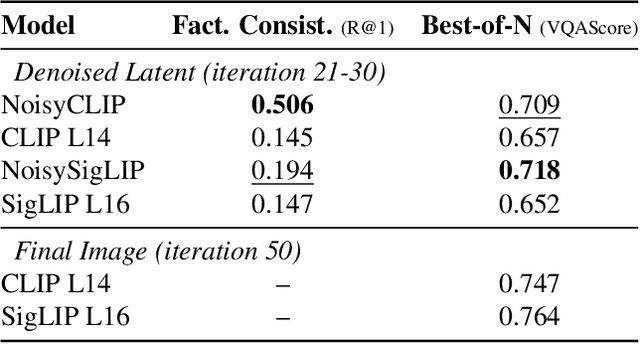
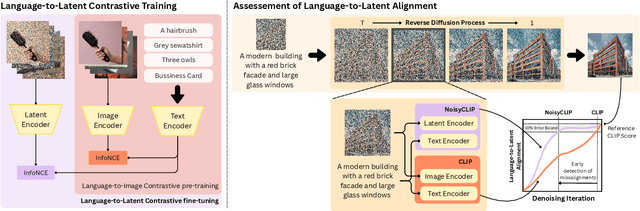
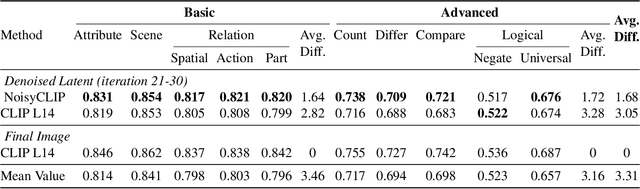
Conditional diffusion models rely on language-to-image alignment methods to steer the generation towards semantically accurate outputs. Despite the success of this architecture, misalignment and hallucinations remain common issues and require automatic misalignment detection tools to improve quality, for example by applying them in a Best-of-N (BoN) post-generation setting. Unfortunately, measuring the alignment after the generation is an expensive step since we need to wait for the overall generation to finish to determine prompt adherence. In contrast, this work hypothesizes that text/image misalignments can be detected early in the denoising process, enabling real-time alignment assessment without waiting for the complete generation. In particular, we propose NoisyCLIP a method that measures semantic alignment in the noisy latent space. This work is the first to explore and benchmark prompt-to-latent misalignment detection during image generation using dual encoders in the reverse diffusion process. We evaluate NoisyCLIP qualitatively and quantitatively and find it reduces computational cost by 50% while achieving 98% of CLIP alignment performance in BoN settings. This approach enables real-time alignment assessment during generation, reducing costs without sacrificing semantic fidelity.
Multilingual Vision-Language Pre-training for the Remote Sensing Domain
Oct 30, 2024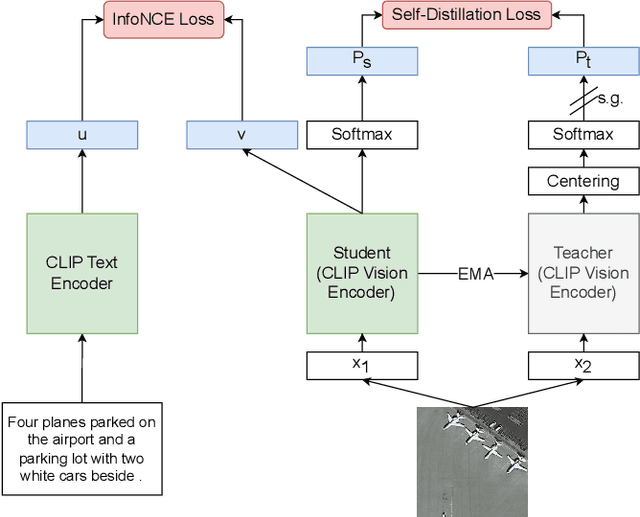
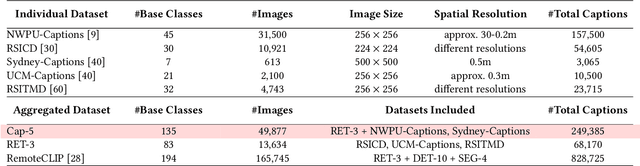

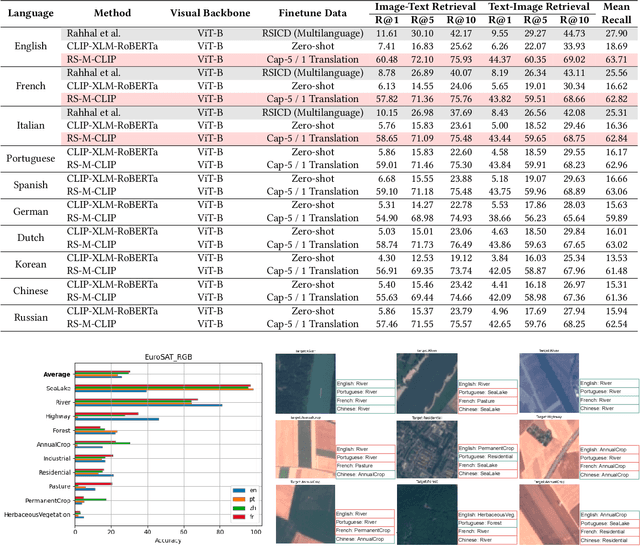
Methods based on Contrastive Language-Image Pre-training (CLIP) are nowadays extensively used in support of vision-and-language tasks involving remote sensing data, such as cross-modal retrieval. The adaptation of CLIP to this specific domain has relied on model fine-tuning with the standard contrastive objective, using existing human-labeled image-caption datasets, or using synthetic data corresponding to image-caption pairs derived from other annotations over remote sensing images (e.g., object classes). The use of different pre-training mechanisms has received less attention, and only a few exceptions have considered multilingual inputs. This work proposes a novel vision-and-language model for the remote sensing domain, exploring the fine-tuning of a multilingual CLIP model and testing the use of a self-supervised method based on aligning local and global representations from individual input images, together with the standard CLIP objective. Model training relied on assembling pre-existing datasets of remote sensing images paired with English captions, followed by the use of automated machine translation into nine additional languages. We show that translated data is indeed helpful, e.g. improving performance also on English. Our resulting model, which we named Remote Sensing Multilingual CLIP (RS-M-CLIP), obtains state-of-the-art results in a variety of vision-and-language tasks, including cross-modal and multilingual image-text retrieval, or zero-shot image classification.
Contrastive Sequential-Diffusion Learning: An approach to Multi-Scene Instructional Video Synthesis
Jul 16, 2024



Action-centric sequence descriptions like recipe instructions and do-it-yourself projects include non-linear patterns in which the next step may require to be visually consistent not on the immediate previous step but on earlier steps. Current video synthesis approaches fail to generate consistent multi-scene videos for such task descriptions. We propose a contrastive sequential video diffusion method that selects the most suitable previously generated scene to guide and condition the denoising process of the next scene. The result is a multi-scene video that is grounded in the scene descriptions and coherent w.r.t the scenes that require consistent visualisation. Our experiments with real-world data demonstrate the practicality and improved consistency of our model compared to prior work.
Generating Coherent Sequences of Visual Illustrations for Real-World Manual Tasks
May 16, 2024



Multistep instructions, such as recipes and how-to guides, greatly benefit from visual aids, such as a series of images that accompany the instruction steps. While Large Language Models (LLMs) have become adept at generating coherent textual steps, Large Vision/Language Models (LVLMs) are less capable of generating accompanying image sequences. The most challenging aspect is that each generated image needs to adhere to the relevant textual step instruction, as well as be visually consistent with earlier images in the sequence. To address this problem, we propose an approach for generating consistent image sequences, which integrates a Latent Diffusion Model (LDM) with an LLM to transform the sequence into a caption to maintain the semantic coherence of the sequence. In addition, to maintain the visual coherence of the image sequence, we introduce a copy mechanism to initialise reverse diffusion processes with a latent vector iteration from a previously generated image from a relevant step. Both strategies will condition the reverse diffusion process on the sequence of instruction steps and tie the contents of the current image to previous instruction steps and corresponding images. Experiments show that the proposed approach is preferred by humans in 46.6% of the cases against 26.6% for the second best method. In addition, automatic metrics showed that the proposed method maintains semantic coherence and visual consistency across steps in both domains.
Transferring Visual Attributes from Natural Language to Verified Image Generation
May 24, 2023Text to image generation methods (T2I) are widely popular in generating art and other creative artifacts. While visual hallucinations can be a positive factor in scenarios where creativity is appreciated, such artifacts are poorly suited for cases where the generated image needs to be grounded in complex natural language without explicit visual elements. In this paper, we propose to strengthen the consistency property of T2I methods in the presence of natural complex language, which often breaks the limits of T2I methods by including non-visual information, and textual elements that require knowledge for accurate generation. To address these phenomena, we propose a Natural Language to Verified Image generation approach (NL2VI) that converts a natural prompt into a visual prompt, which is more suitable for image generation. A T2I model then generates an image for the visual prompt, which is then verified with VQA algorithms. Experimentally, aligning natural prompts with image generation can improve the consistency of the generated images by up to 11% over the state of the art. Moreover, improvements can generalize to challenging domains like cooking and DIY tasks, where the correctness of the generated image is crucial to illustrate actions.
BERT Embeddings Can Track Context in Conversational Search
Apr 13, 2021



The use of conversational assistants to search for information is becoming increasingly more popular among the general public, pushing the research towards more advanced and sophisticated techniques. In the last few years, in particular, the interest in conversational search is increasing, not only because of the generalization of conversational assistants but also because conversational search is a step forward in allowing a more natural interaction with the system. In this work, the focus is on exploring the context present of the conversation via the historical utterances and respective embeddings with the aim of developing a conversational search system that helps people search for information in a natural way. In particular, this system must be able to understand the context where the question is posed, tracking the current state of the conversation and detecting mentions to previous questions and answers. We achieve this by using a context-tracking component based on neural query-rewriting models. Another crucial aspect of the system is to provide the most relevant answers given the question and the conversational history. To achieve this objective, we used a Transformer-based re-ranking method and expanded this architecture to use the conversational context. The results obtained with the system developed showed the advantages of using the context present in the natural language utterances and in the neural embeddings generated throughout the conversation.
Open-Domain Conversational Search Assistant with Transformers
Jan 20, 2021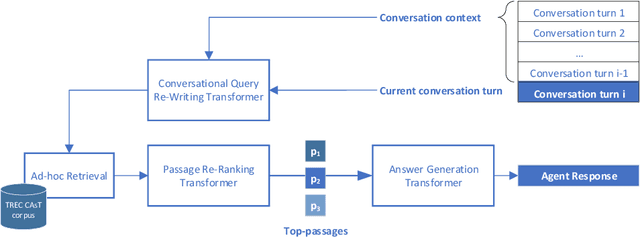

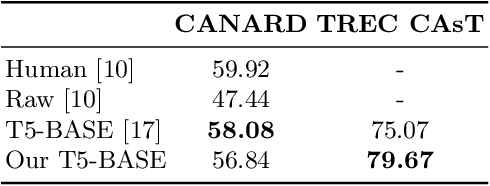
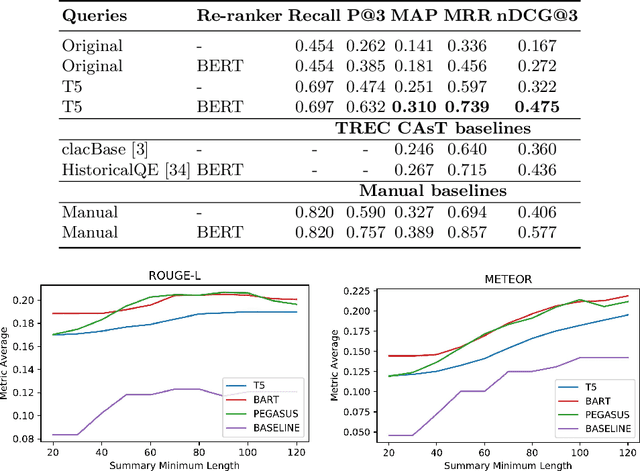
Open-domain conversational search assistants aim at answering user questions about open topics in a conversational manner. In this paper we show how the Transformer architecture achieves state-of-the-art results in key IR tasks, leveraging the creation of conversational assistants that engage in open-domain conversational search with single, yet informative, answers. In particular, we propose an open-domain abstractive conversational search agent pipeline to address two major challenges: first, conversation context-aware search and second, abstractive search-answers generation. To address the first challenge, the conversation context is modeled with a query rewriting method that unfolds the context of the conversation up to a specific moment to search for the correct answers. These answers are then passed to a Transformer-based re-ranker to further improve retrieval performance. The second challenge, is tackled with recent Abstractive Transformer architectures to generate a digest of the top most relevant passages. Experiments show that Transformers deliver a solid performance across all tasks in conversational search, outperforming the best TREC CAsT 2019 baseline.