 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeALBA: A European Portuguese Benchmark for Evaluating Language and Linguistic Dimensions in Generative LLMs
Mar 27, 2026As Large Language Models (LLMs) expand across multilingual domains, evaluating their performance in under-represented languages becomes increasingly important. European Portuguese (pt-PT) is particularly affected, as existing training data and benchmarks are mainly in Brazilian Portuguese (pt-BR). To address this, we introduce ALBA, a linguistically grounded benchmark designed from the ground up to assess LLM proficiency in linguistic-related tasks in pt-PT across eight linguistic dimensions, including Language Variety, Culture-bound Semantics, Discourse Analysis, Word Plays, Syntax, Morphology, Lexicology, and Phonetics and Phonology. ALBA is manually constructed by language experts and paired with an LLM-as-a-judge framework for scalable evaluation of pt-PT generated language. Experiments on a diverse set of models reveal performance variability across linguistic dimensions, highlighting the need for comprehensive, variety-sensitive benchmarks that support further development of tools in pt-PT.
AMALIA Technical Report: A Fully Open Source Large Language Model for European Portuguese
Mar 27, 2026Despite rapid progress in open large language models (LLMs), European Portuguese (pt-PT) remains underrepresented in both training data and native evaluation, with machine-translated benchmarks likely missing the variant's linguistic and cultural nuances. We introduce AMALIA, a fully open LLM that prioritizes pt-PT by using more high-quality pt-PT data during both the mid- and post-training stages. To evaluate pt-PT more faithfully, we release a suite of pt-PT benchmarks that includes translated standard tasks and four new datasets targeting pt-PT generation, linguistic competence, and pt-PT/pt-BR bias. Experiments show that AMALIA matches strong baselines on translated benchmarks while substantially improving performance on pt-PT-specific evaluations, supporting the case for targeted training and native benchmarking for European Portuguese.
VIGiA: Instructional Video Guidance via Dialogue Reasoning and Retrieval
Feb 22, 2026We introduce VIGiA, a novel multimodal dialogue model designed to understand and reason over complex, multi-step instructional video action plans. Unlike prior work which focuses mainly on text-only guidance, or treats vision and language in isolation, VIGiA supports grounded, plan-aware dialogue that requires reasoning over visual inputs, instructional plans, and interleaved user interactions. To this end, VIGiA incorporates two key capabilities: (1) multimodal plan reasoning, enabling the model to align uni- and multimodal queries with the current task plan and respond accurately; and (2) plan-based retrieval, allowing it to retrieve relevant plan steps in either textual or visual representations. Experiments were done on a novel dataset with rich Instructional Video Dialogues aligned with Cooking and DIY plans. Our evaluation shows that VIGiA outperforms existing state-of-the-art models on all tasks in a conversational plan guidance setting, reaching over 90\% accuracy on plan-aware VQA.
FineVAU: A Novel Human-Aligned Benchmark for Fine-Grained Video Anomaly Understanding
Jan 24, 2026Video Anomaly Understanding (VAU) is a novel task focused on describing unusual occurrences in videos. Despite growing interest, the evaluation of VAU remains an open challenge. Existing benchmarks rely on n-gram-based metrics (e.g., BLEU, ROUGE-L) or LLM-based evaluation. The first fails to capture the rich, free-form, and visually grounded nature of LVLM responses, while the latter focuses on assessing language quality over factual relevance, often resulting in subjective judgments that are misaligned with human perception. In this work, we address this issue by proposing FineVAU, a new benchmark for VAU that shifts the focus towards rich, fine-grained and domain-specific understanding of anomalous videos. We formulate VAU as a three-fold problem, with the goal of comprehensively understanding key descriptive elements of anomalies in video: events (What), participating entities (Who) and location (Where). Our benchmark introduces a) FVScore, a novel, human-aligned evaluation metric that assesses the presence of critical visual elements in LVLM answers, providing interpretable, fine-grained feedback; and b) FineW3, a novel, comprehensive dataset curated through a structured and fully automatic procedure that augments existing human annotations with high quality, fine-grained visual information. Human evaluation reveals that our proposed metric has a superior alignment with human perception of anomalies in comparison to current approaches. Detailed experiments on FineVAU unveil critical limitations in LVLM's ability to perceive anomalous events that require spatial and fine-grained temporal understanding, despite strong performance on coarse grain, static information, and events with strong visual cues.
Chain-of-Anomaly Thoughts with Large Vision-Language Models
Dec 23, 2025Automated video surveillance with Large Vision-Language Models is limited by their inherent bias towards normality, often failing to detect crimes. While Chain-of-Thought reasoning strategies show significant potential for improving performance in language tasks, the lack of inductive anomaly biases in their reasoning further steers the models towards normal interpretations. To address this, we propose Chain-of-Anomaly-Thoughts (CoAT), a multi-agent reasoning framework that introduces inductive criminal bias in the reasoning process through a final, anomaly-focused classification layer. Our method significantly improves Anomaly Detection, boosting F1-score by 11.8 p.p. on challenging low-resolution footage and Anomaly Classification by 3.78 p.p. in high-resolution videos.
RedTWIZ: Diverse LLM Red Teaming via Adaptive Attack Planning
Oct 08, 2025This paper presents the vision, scientific contributions, and technical details of RedTWIZ: an adaptive and diverse multi-turn red teaming framework, to audit the robustness of Large Language Models (LLMs) in AI-assisted software development. Our work is driven by three major research streams: (1) robust and systematic assessment of LLM conversational jailbreaks; (2) a diverse generative multi-turn attack suite, supporting compositional, realistic and goal-oriented jailbreak conversational strategies; and (3) a hierarchical attack planner, which adaptively plans, serializes, and triggers attacks tailored to specific LLM's vulnerabilities. Together, these contributions form a unified framework -- combining assessment, attack generation, and strategic planning -- to comprehensively evaluate and expose weaknesses in LLMs' robustness. Extensive evaluation is conducted to systematically assess and analyze the performance of the overall system and each component. Experimental results demonstrate that our multi-turn adversarial attack strategies can successfully lead state-of-the-art LLMs to produce unsafe generations, highlighting the pressing need for more research into enhancing LLM's robustness.
Self-ReS: Self-Reflection in Large Vision-Language Models for Long Video Understanding
Mar 26, 2025Large Vision-Language Models (LVLMs) demonstrate remarkable performance in short-video tasks such as video question answering, but struggle in long-video understanding. The linear frame sampling strategy, conventionally used by LVLMs, fails to account for the non-linear distribution of key events in video data, often introducing redundant or irrelevant information in longer contexts while risking the omission of critical events in shorter ones. To address this, we propose SelfReS, a non-linear spatiotemporal self-reflective sampling method that dynamically selects key video fragments based on user prompts. Unlike prior approaches, SelfReS leverages the inherently sparse attention maps of LVLMs to define reflection tokens, enabling relevance-aware token selection without requiring additional training or external modules. Experiments demonstrate that SelfReS can be seamlessly integrated into strong base LVLMs, improving long-video task accuracy and achieving up to 46% faster inference speed within the same GPU memory budget.
Zero-Shot Action Recognition in Surveillance Videos
Oct 28, 2024



The growing demand for surveillance in public spaces presents significant challenges due to the shortage of human resources. Current AI-based video surveillance systems heavily rely on core computer vision models that require extensive finetuning, which is particularly difficult in surveillance settings due to limited datasets and difficult setting (viewpoint, low quality, etc.). In this work, we propose leveraging Large Vision-Language Models (LVLMs), known for their strong zero and few-shot generalization, to tackle video understanding tasks in surveillance. Specifically, we explore VideoLLaMA2, a state-of-the-art LVLM, and an improved token-level sampling method, Self-Reflective Sampling (Self-ReS). Our experiments on the UCF-Crime dataset show that VideoLLaMA2 represents a significant leap in zero-shot performance, with 20% boost over the baseline. Self-ReS additionally increases zero-shot action recognition performance to 44.6%. These results highlight the potential of LVLMs, paired with improved sampling techniques, for advancing surveillance video analysis in diverse scenarios.
Multi-trait User Simulation with Adaptive Decoding for Conversational Task Assistants
Oct 16, 2024


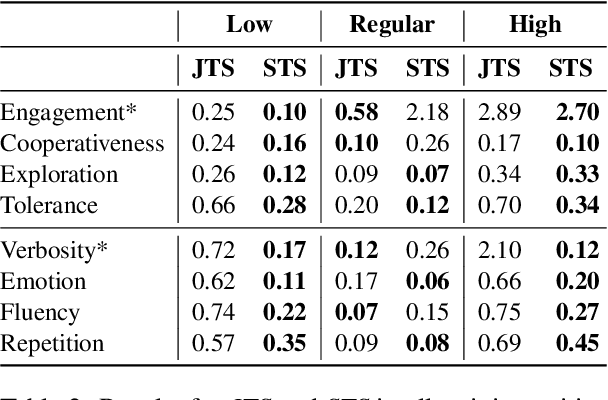
Conversational systems must be robust to user interactions that naturally exhibit diverse conversational traits. Capturing and simulating these diverse traits coherently and efficiently presents a complex challenge. This paper introduces Multi-Trait Adaptive Decoding (mTAD), a method that generates diverse user profiles at decoding-time by sampling from various trait-specific Language Models (LMs). mTAD provides an adaptive and scalable approach to user simulation, enabling the creation of multiple user profiles without the need for additional fine-tuning. By analyzing real-world dialogues from the Conversational Task Assistant (CTA) domain, we identify key conversational traits and developed a framework to generate profile-aware dialogues that enhance conversational diversity. Experimental results validate the effectiveness of our approach in modeling single-traits using specialized LMs, which can capture less common patterns, even in out-of-domain tasks. Furthermore, the results demonstrate that mTAD is a robust and flexible framework for combining diverse user simulators.
Show and Guide: Instructional-Plan Grounded Vision and Language Model
Sep 27, 2024



Guiding users through complex procedural plans is an inherently multimodal task in which having visually illustrated plan steps is crucial to deliver an effective plan guidance. However, existing works on plan-following language models (LMs) often are not capable of multimodal input and output. In this work, we present MM-PlanLLM, the first multimodal LLM designed to assist users in executing instructional tasks by leveraging both textual plans and visual information. Specifically, we bring cross-modality through two key tasks: Conversational Video Moment Retrieval, where the model retrieves relevant step-video segments based on user queries, and Visually-Informed Step Generation, where the model generates the next step in a plan, conditioned on an image of the user's current progress. MM-PlanLLM is trained using a novel multitask-multistage approach, designed to gradually expose the model to multimodal instructional-plans semantic layers, achieving strong performance on both multimodal and textual dialogue in a plan-grounded setting. Furthermore, we show that the model delivers cross-modal temporal and plan-structure representations aligned between textual plan steps and instructional video moments.