 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFineVAU: A Novel Human-Aligned Benchmark for Fine-Grained Video Anomaly Understanding
Jan 24, 2026Video Anomaly Understanding (VAU) is a novel task focused on describing unusual occurrences in videos. Despite growing interest, the evaluation of VAU remains an open challenge. Existing benchmarks rely on n-gram-based metrics (e.g., BLEU, ROUGE-L) or LLM-based evaluation. The first fails to capture the rich, free-form, and visually grounded nature of LVLM responses, while the latter focuses on assessing language quality over factual relevance, often resulting in subjective judgments that are misaligned with human perception. In this work, we address this issue by proposing FineVAU, a new benchmark for VAU that shifts the focus towards rich, fine-grained and domain-specific understanding of anomalous videos. We formulate VAU as a three-fold problem, with the goal of comprehensively understanding key descriptive elements of anomalies in video: events (What), participating entities (Who) and location (Where). Our benchmark introduces a) FVScore, a novel, human-aligned evaluation metric that assesses the presence of critical visual elements in LVLM answers, providing interpretable, fine-grained feedback; and b) FineW3, a novel, comprehensive dataset curated through a structured and fully automatic procedure that augments existing human annotations with high quality, fine-grained visual information. Human evaluation reveals that our proposed metric has a superior alignment with human perception of anomalies in comparison to current approaches. Detailed experiments on FineVAU unveil critical limitations in LVLM's ability to perceive anomalous events that require spatial and fine-grained temporal understanding, despite strong performance on coarse grain, static information, and events with strong visual cues.
Chain-of-Anomaly Thoughts with Large Vision-Language Models
Dec 23, 2025Automated video surveillance with Large Vision-Language Models is limited by their inherent bias towards normality, often failing to detect crimes. While Chain-of-Thought reasoning strategies show significant potential for improving performance in language tasks, the lack of inductive anomaly biases in their reasoning further steers the models towards normal interpretations. To address this, we propose Chain-of-Anomaly-Thoughts (CoAT), a multi-agent reasoning framework that introduces inductive criminal bias in the reasoning process through a final, anomaly-focused classification layer. Our method significantly improves Anomaly Detection, boosting F1-score by 11.8 p.p. on challenging low-resolution footage and Anomaly Classification by 3.78 p.p. in high-resolution videos.
Self-ReS: Self-Reflection in Large Vision-Language Models for Long Video Understanding
Mar 26, 2025Large Vision-Language Models (LVLMs) demonstrate remarkable performance in short-video tasks such as video question answering, but struggle in long-video understanding. The linear frame sampling strategy, conventionally used by LVLMs, fails to account for the non-linear distribution of key events in video data, often introducing redundant or irrelevant information in longer contexts while risking the omission of critical events in shorter ones. To address this, we propose SelfReS, a non-linear spatiotemporal self-reflective sampling method that dynamically selects key video fragments based on user prompts. Unlike prior approaches, SelfReS leverages the inherently sparse attention maps of LVLMs to define reflection tokens, enabling relevance-aware token selection without requiring additional training or external modules. Experiments demonstrate that SelfReS can be seamlessly integrated into strong base LVLMs, improving long-video task accuracy and achieving up to 46% faster inference speed within the same GPU memory budget.
Zero-Shot Action Recognition in Surveillance Videos
Oct 28, 2024



The growing demand for surveillance in public spaces presents significant challenges due to the shortage of human resources. Current AI-based video surveillance systems heavily rely on core computer vision models that require extensive finetuning, which is particularly difficult in surveillance settings due to limited datasets and difficult setting (viewpoint, low quality, etc.). In this work, we propose leveraging Large Vision-Language Models (LVLMs), known for their strong zero and few-shot generalization, to tackle video understanding tasks in surveillance. Specifically, we explore VideoLLaMA2, a state-of-the-art LVLM, and an improved token-level sampling method, Self-Reflective Sampling (Self-ReS). Our experiments on the UCF-Crime dataset show that VideoLLaMA2 represents a significant leap in zero-shot performance, with 20% boost over the baseline. Self-ReS additionally increases zero-shot action recognition performance to 44.6%. These results highlight the potential of LVLMs, paired with improved sampling techniques, for advancing surveillance video analysis in diverse scenarios.
Are Neural Architecture Search Benchmarks Well Designed? A Deeper Look Into Operation Importance
Mar 29, 2023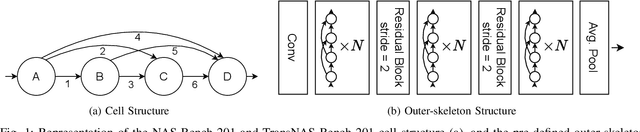

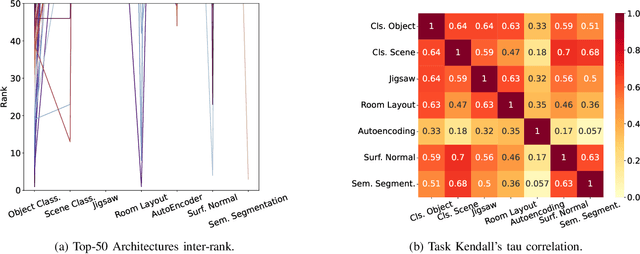
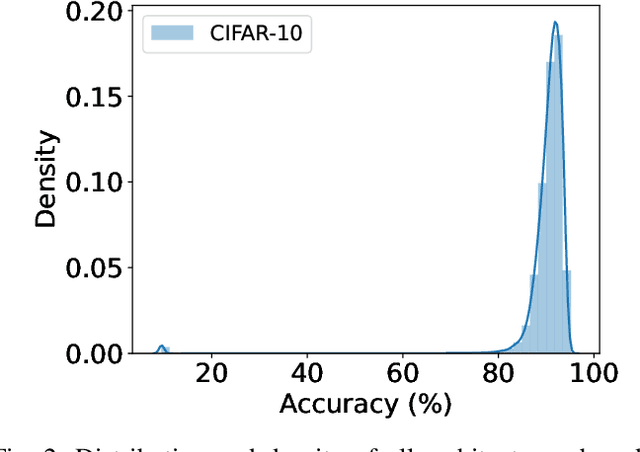
Neural Architecture Search (NAS) benchmarks significantly improved the capability of developing and comparing NAS methods while at the same time drastically reduced the computational overhead by providing meta-information about thousands of trained neural networks. However, tabular benchmarks have several drawbacks that can hinder fair comparisons and provide unreliable results. These usually focus on providing a small pool of operations in heavily constrained search spaces -- usually cell-based neural networks with pre-defined outer-skeletons. In this work, we conducted an empirical analysis of the widely used NAS-Bench-101, NAS-Bench-201 and TransNAS-Bench-101 benchmarks in terms of their generability and how different operations influence the performance of the generated architectures. We found that only a subset of the operation pool is required to generate architectures close to the upper-bound of the performance range. Also, the performance distribution is negatively skewed, having a higher density of architectures in the upper-bound range. We consistently found convolution layers to have the highest impact on the architecture's performance, and that specific combination of operations favors top-scoring architectures. These findings shed insights on the correct evaluation and comparison of NAS methods using NAS benchmarks, showing that directly searching on NAS-Bench-201, ImageNet16-120 and TransNAS-Bench-101 produces more reliable results than searching only on CIFAR-10. Furthermore, with this work we provide suggestions for future benchmark evaluations and design. The code used to conduct the evaluations is available at https://github.com/VascoLopes/NAS-Benchmark-Evaluation.
Towards Less Constrained Macro-Neural Architecture Search
Mar 10, 2022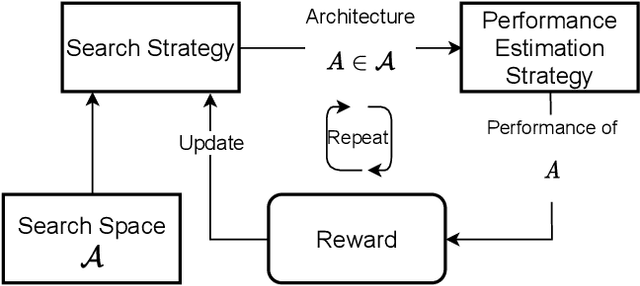



Networks found with Neural Architecture Search (NAS) achieve state-of-the-art performance in a variety of tasks, out-performing human-designed networks. However, most NAS methods heavily rely on human-defined assumptions that constrain the search: architecture's outer-skeletons, number of layers, parameter heuristics and search spaces. Additionally, common search spaces consist of repeatable modules (cells) instead of fully exploring the architecture's search space by designing entire architectures (macro-search). Imposing such constraints requires deep human expertise and restricts the search to pre-defined settings. In this paper, we propose LCMNAS, a method that pushes NAS to less constrained search spaces by performing macro-search without relying on pre-defined heuristics or bounded search spaces. LCMNAS introduces three components for the NAS pipeline: i) a method that leverages information about well-known architectures to autonomously generate complex search spaces based on Weighted Directed Graphs with hidden properties, ii) a evolutionary search strategy that generates complete architectures from scratch, and iii) a mixed-performance estimation approach that combines information about architectures at initialization stage and lower fidelity estimates to infer their trainability and capacity to model complex functions. We present experiments showing that LCMNAS generates state-of-the-art architectures from scratch with minimal GPU computation. We study the importance of different NAS components on a macro-search setting. Code for reproducibility is public at \url{https://github.com/VascoLopes/LCMNAS}.
Guided Evolution for Neural Architecture Search
Oct 28, 2021
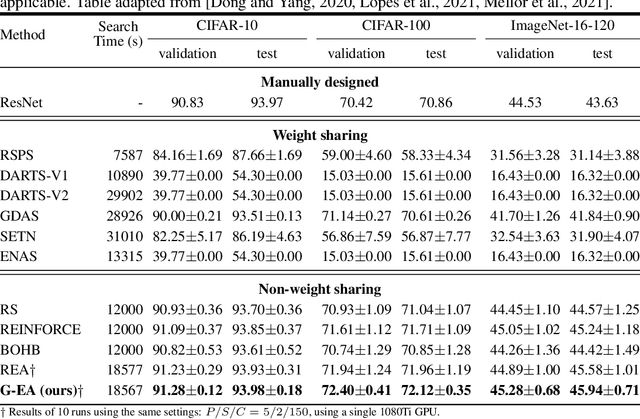

Neural Architecture Search (NAS) methods have been successfully applied to image tasks with excellent results. However, NAS methods are often complex and tend to converge to local minima as soon as generated architectures seem to yield good results. In this paper, we propose G-EA, a novel approach for guided evolutionary NAS. The rationale behind G-EA, is to explore the search space by generating and evaluating several architectures in each generation at initialization stage using a zero-proxy estimator, where only the highest-scoring network is trained and kept for the next generation. This evaluation at initialization stage allows continuous extraction of knowledge from the search space without increasing computation, thus allowing the search to be efficiently guided. Moreover, G-EA forces exploitation of the most performant networks by descendant generation while at the same time forcing exploration by parent mutation and by favouring younger architectures to the detriment of older ones. Experimental results demonstrate the effectiveness of the proposed method, showing that G-EA achieves state-of-the-art results in NAS-Bench-201 search space in CIFAR-10, CIFAR-100 and ImageNet16-120, with mean accuracies of 93.98%, 72.12% and 45.94% respectively.
Generative Adversarial Graph Convolutional Networks for Human Action Synthesis
Oct 25, 2021
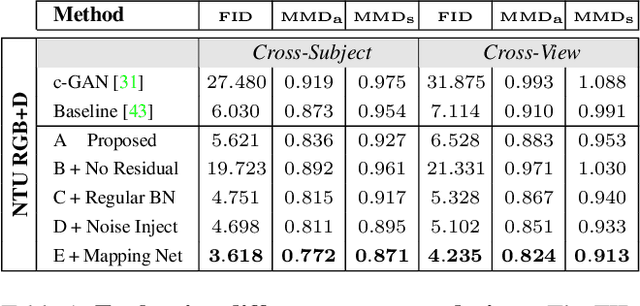


Synthesising the spatial and temporal dynamics of the human body skeleton remains a challenging task, not only in terms of the quality of the generated shapes, but also of their diversity, particularly to synthesise realistic body movements of a specific action (action conditioning). In this paper, we propose Kinetic-GAN, a novel architecture that leverages the benefits of Generative Adversarial Networks and Graph Convolutional Networks to synthesise the kinetics of the human body. The proposed adversarial architecture can condition up to 120 different actions over local and global body movements while improving sample quality and diversity through latent space disentanglement and stochastic variations. Our experiments were carried out in three well-known datasets, where Kinetic-GAN notably surpasses the state-of-the-art methods in terms of distribution quality metrics while having the ability to synthesise more than one order of magnitude regarding the number of different actions. Our code and models are publicly available at https://github.com/DegardinBruno/Kinetic-GAN.
REGINA - Reasoning Graph Convolutional Networks in Human Action Recognition
May 14, 2021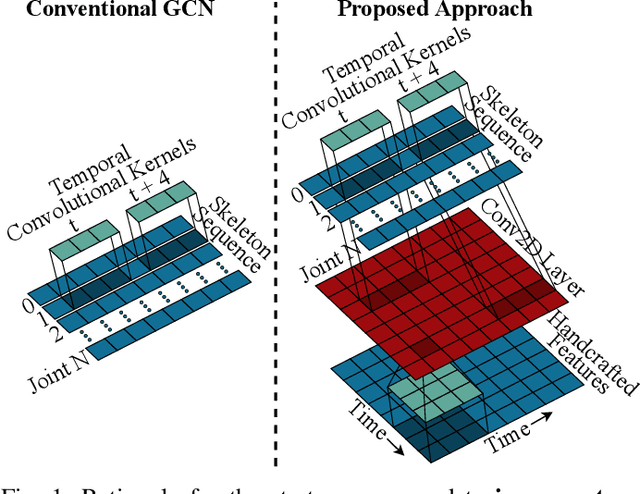

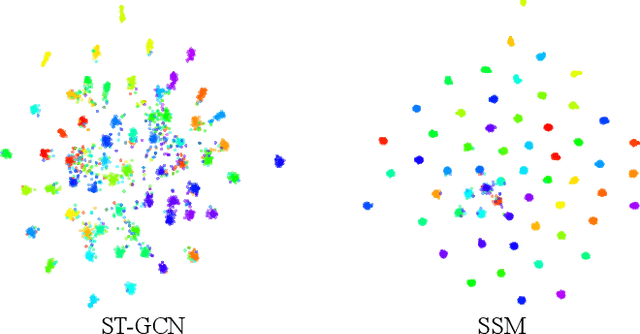
It is known that the kinematics of the human body skeleton reveals valuable information in action recognition. Recently, modeling skeletons as spatio-temporal graphs with Graph Convolutional Networks (GCNs) has been reported to solidly advance the state-of-the-art performance. However, GCN-based approaches exclusively learn from raw skeleton data, and are expected to extract the inherent structural information on their own. This paper describes REGINA, introducing a novel way to REasoning Graph convolutional networks IN Human Action recognition. The rationale is to provide to the GCNs additional knowledge about the skeleton data, obtained by handcrafted features, in order to facilitate the learning process, while guaranteeing that it remains fully trainable in an end-to-end manner. The challenge is to capture complementary information over the dynamics between consecutive frames, which is the key information extracted by state-of-the-art GCN techniques. Moreover, the proposed strategy can be easily integrated in the existing GCN-based methods, which we also regard positively. Our experiments were carried out in well known action recognition datasets and enabled to conclude that REGINA contributes for solid improvements in performance when incorporated to other GCN-based approaches, without any other adjustment regarding the original method. For reproducibility, the REGINA code and all the experiments carried out will be publicly available at https://github.com/DegardinBruno.
EPE-NAS: Efficient Performance Estimation Without Training for Neural Architecture Search
Feb 16, 2021

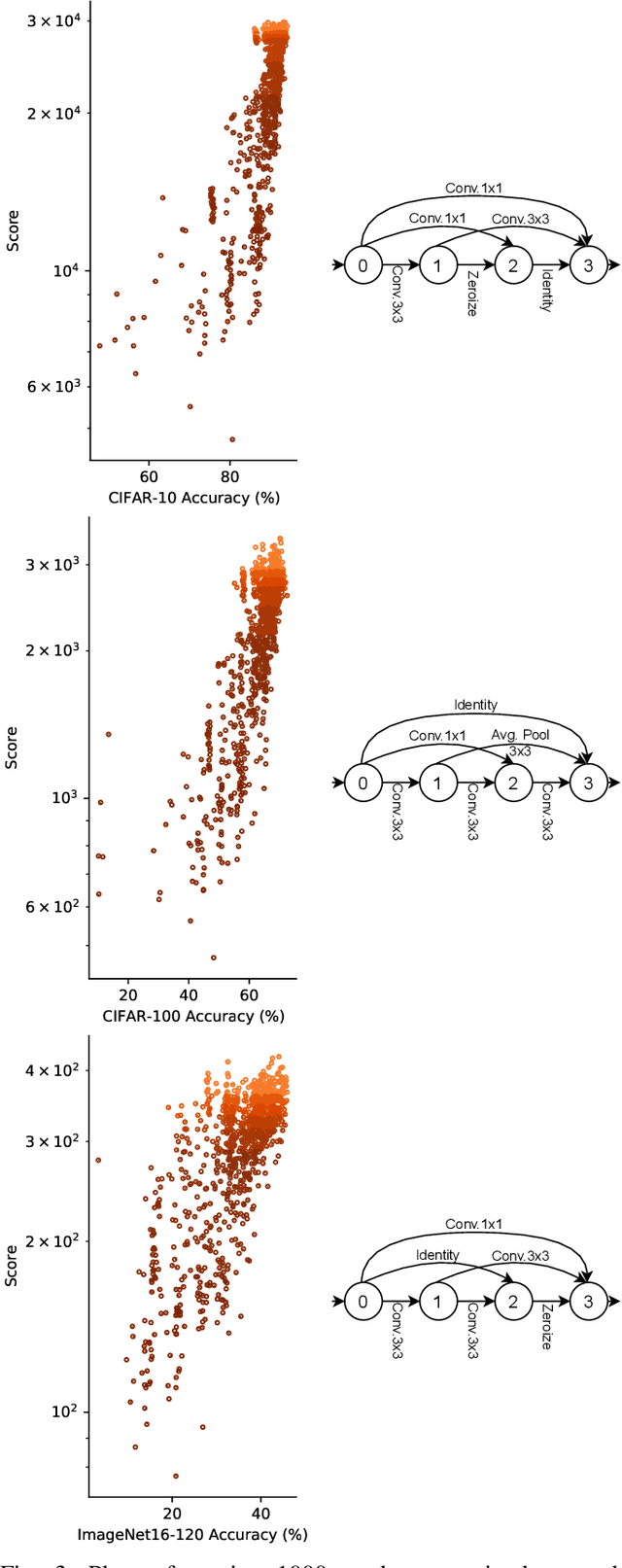
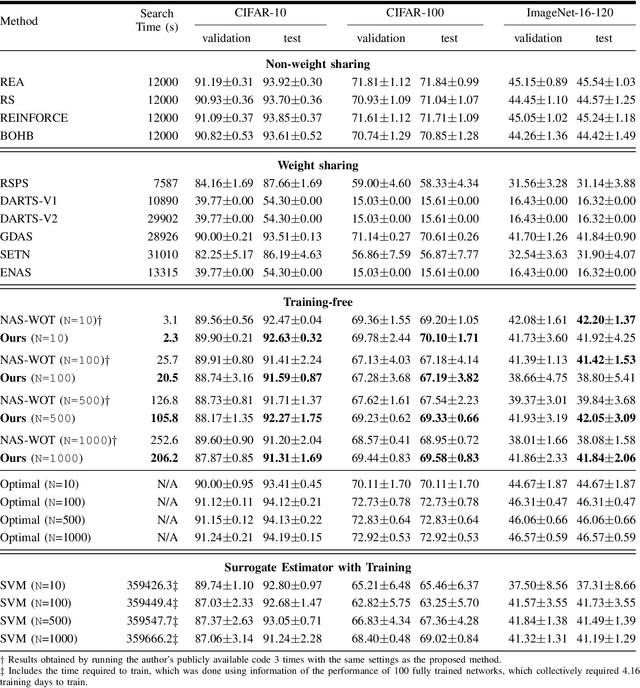
Neural Architecture Search (NAS) has shown excellent results in designing architectures for computer vision problems. NAS alleviates the need for human-defined settings by automating architecture design and engineering. However, NAS methods tend to be slow, as they require large amounts of GPU computation. This bottleneck is mainly due to the performance estimation strategy, which requires the evaluation of the generated architectures, mainly by training them, to update the sampler method. In this paper, we propose EPE-NAS, an efficient performance estimation strategy, that mitigates the problem of evaluating networks, by scoring untrained networks and creating a correlation with their trained performance. We perform this process by looking at intra and inter-class correlations of an untrained network. We show that EPE-NAS can produce a robust correlation and that by incorporating it into a simple random sampling strategy, we are able to search for competitive networks, without requiring any training, in a matter of seconds using a single GPU. Moreover, EPE-NAS is agnostic to the search method, since it focuses on the evaluation of untrained networks, making it easy to integrate into almost any NAS method.