 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeHierarchical Decision Mamba
May 13, 2024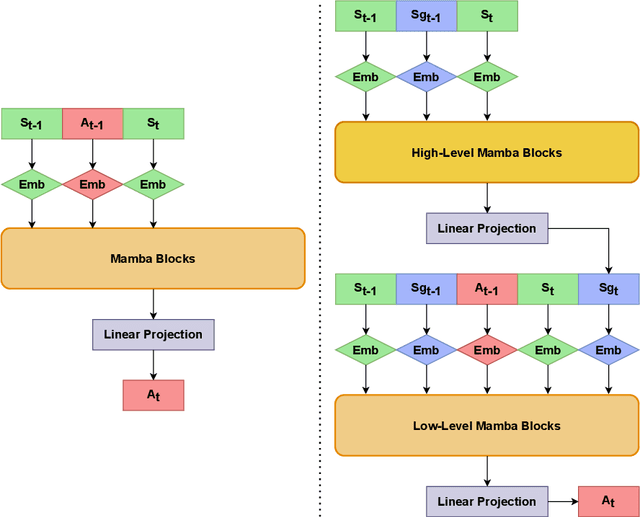



Recent advancements in imitation learning have been largely fueled by the integration of sequence models, which provide a structured flow of information to effectively mimic task behaviours. Currently, Decision Transformer (DT) and subsequently, the Hierarchical Decision Transformer (HDT), presented Transformer-based approaches to learn task policies. Recently, the Mamba architecture has shown to outperform Transformers across various task domains. In this work, we introduce two novel methods, Decision Mamba (DM) and Hierarchical Decision Mamba (HDM), aimed at enhancing the performance of the Transformer models. Through extensive experimentation across diverse environments such as OpenAI Gym and D4RL, leveraging varying demonstration data sets, we demonstrate the superiority of Mamba models over their Transformer counterparts in a majority of tasks. Results show that HDM outperforms other methods in most settings. The code can be found at https://github.com/meowatthemoon/HierarchicalDecisionMamba.
Music to Dance as Language Translation using Sequence Models
Mar 22, 2024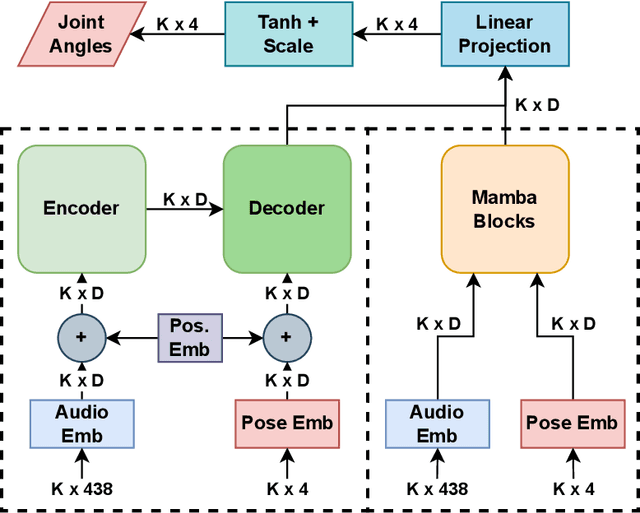
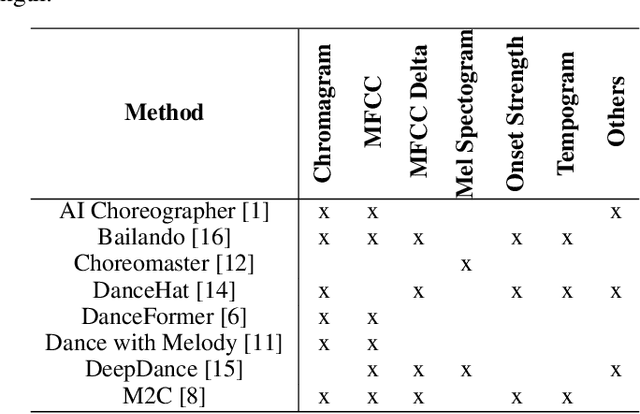
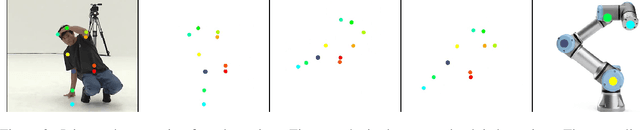
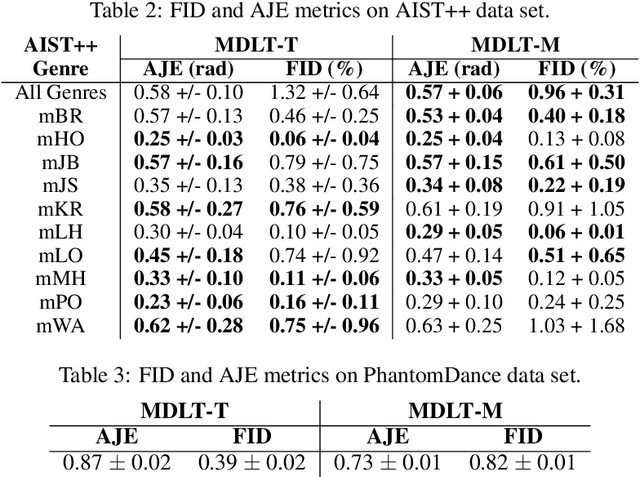
Synthesising appropriate choreographies from music remains an open problem. We introduce MDLT, a novel approach that frames the choreography generation problem as a translation task. Our method leverages an existing data set to learn to translate sequences of audio into corresponding dance poses. We present two variants of MDLT: one utilising the Transformer architecture and the other employing the Mamba architecture. We train our method on AIST++ and PhantomDance data sets to teach a robotic arm to dance, but our method can be applied to a full humanoid robot. Evaluation metrics, including Average Joint Error and Frechet Inception Distance, consistently demonstrate that, when given a piece of music, MDLT excels at producing realistic and high-quality choreography. The code can be found at github.com/meowatthemoon/MDLT.
Robust Energy Consumption Prediction with a Missing Value-Resilient Metaheuristic-based Neural Network in Mobile App Development
Sep 21, 2023



Energy consumption is a fundamental concern in mobile application development, bearing substantial significance for both developers and end-users. Moreover, it is a critical determinant in the consumer's decision-making process when considering a smartphone purchase. From the sustainability perspective, it becomes imperative to explore approaches aimed at mitigating the energy consumption of mobile devices, given the significant global consequences arising from the extensive utilisation of billions of smartphones, which imparts a profound environmental impact. Despite the existence of various energy-efficient programming practices within the Android platform, the dominant mobile ecosystem, there remains a need for documented machine learning-based energy prediction algorithms tailored explicitly for mobile app development. Hence, the main objective of this research is to propose a novel neural network-based framework, enhanced by a metaheuristic approach, to achieve robust energy prediction in the context of mobile app development. The metaheuristic approach here plays a crucial role in not only identifying suitable learning algorithms and their corresponding parameters but also determining the optimal number of layers and neurons within each layer. To the best of our knowledge, prior studies have yet to employ any metaheuristic algorithm to address all these hyperparameters simultaneously. Moreover, due to limitations in accessing certain aspects of a mobile phone, there might be missing data in the data set, and the proposed framework can handle this. In addition, we conducted an optimal algorithm selection strategy, employing 13 metaheuristic algorithms, to identify the best algorithm based on accuracy and resistance to missing values. The comprehensive experiments demonstrate that our proposed approach yields significant outcomes for energy consumption prediction.
A Metaheuristic-based Machine Learning Approach for Energy Prediction in Mobile App Development
Jun 16, 2023Energy consumption plays a vital role in mobile App development for developers and end-users, and it is considered one of the most crucial factors for purchasing a smartphone. In addition, in terms of sustainability, it is essential to find methods to reduce the energy consumption of mobile devices since the extensive use of billions of smartphones worldwide significantly impacts the environment. Despite the existence of several energy-efficient programming practices in Android, the leading mobile ecosystem, machine learning-based energy prediction algorithms for mobile App development have yet to be reported. Therefore, this paper proposes a histogram-based gradient boosting classification machine (HGBC), boosted by a metaheuristic approach, for energy prediction in mobile App development. Our metaheuristic approach is responsible for two issues. First, it finds redundant and irrelevant features without any noticeable change in performance. Second, it performs a hyper-parameter tuning for the HGBC algorithm. Since our proposed metaheuristic approach is algorithm-independent, we selected 12 algorithms for the search strategy to find the optimal search algorithm. Our finding shows that a success-history-based parameter adaption for differential evolution with linear population size (L-SHADE) offers the best performance. It can improve performance and decrease the number of features effectively. Our extensive set of experiments clearly shows that our proposed approach can provide significant results for energy consumption prediction.
Are Neural Architecture Search Benchmarks Well Designed? A Deeper Look Into Operation Importance
Mar 29, 2023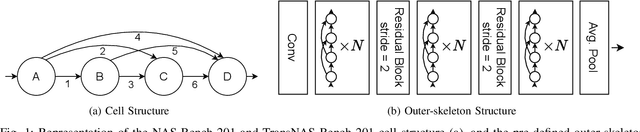

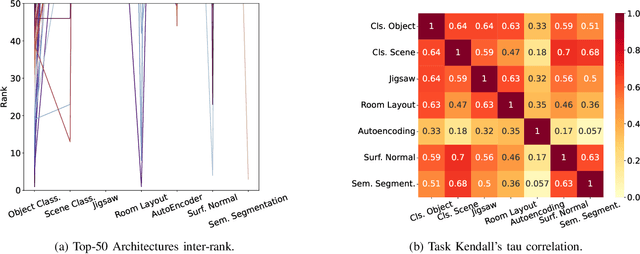
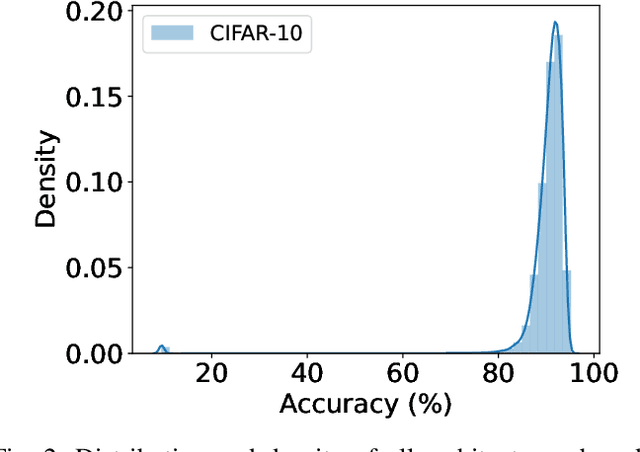
Neural Architecture Search (NAS) benchmarks significantly improved the capability of developing and comparing NAS methods while at the same time drastically reduced the computational overhead by providing meta-information about thousands of trained neural networks. However, tabular benchmarks have several drawbacks that can hinder fair comparisons and provide unreliable results. These usually focus on providing a small pool of operations in heavily constrained search spaces -- usually cell-based neural networks with pre-defined outer-skeletons. In this work, we conducted an empirical analysis of the widely used NAS-Bench-101, NAS-Bench-201 and TransNAS-Bench-101 benchmarks in terms of their generability and how different operations influence the performance of the generated architectures. We found that only a subset of the operation pool is required to generate architectures close to the upper-bound of the performance range. Also, the performance distribution is negatively skewed, having a higher density of architectures in the upper-bound range. We consistently found convolution layers to have the highest impact on the architecture's performance, and that specific combination of operations favors top-scoring architectures. These findings shed insights on the correct evaluation and comparison of NAS methods using NAS benchmarks, showing that directly searching on NAS-Bench-201, ImageNet16-120 and TransNAS-Bench-101 produces more reliable results than searching only on CIFAR-10. Furthermore, with this work we provide suggestions for future benchmark evaluations and design. The code used to conduct the evaluations is available at https://github.com/VascoLopes/NAS-Benchmark-Evaluation.
A Survey on Task Allocation and Scheduling in Robotic Network Systems
Mar 22, 2023
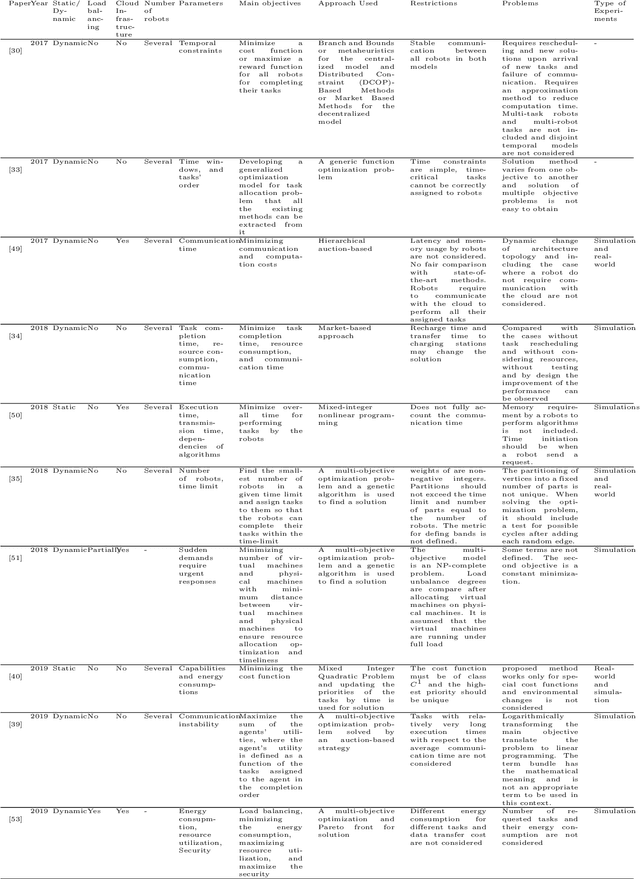

Cloud Robotics is helping to create a new generation of robots that leverage the nearly unlimited resources of large data centers (i.e., the cloud), overcoming the limitations imposed by on-board resources. Different processing power, capabilities, resource sizes, energy consumption, and so forth, make scheduling and task allocation critical components. The basic idea of task allocation and scheduling is to optimize performance by minimizing completion time, energy consumption, delays between two consecutive tasks, along with others, and maximizing resource utilization, number of completed tasks in a given time interval, and suchlike. In the past, several works have addressed various aspects of task allocation and scheduling. In this paper, we provide a comprehensive overview of task allocation and scheduling strategies and related metrics suitable for robotic network cloud systems. We discuss the issues related to allocation and scheduling methods and the limitations that need to be overcome. The literature review is organized according to three different viewpoints: Architectures and Applications, Methods and Parameters. In addition, the limitations of each method are highlighted for future research.
A Survey of Demonstration Learning
Mar 20, 2023
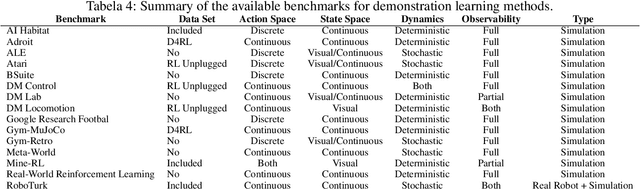

With the fast improvement of machine learning, reinforcement learning (RL) has been used to automate human tasks in different areas. However, training such agents is difficult and restricted to expert users. Moreover, it is mostly limited to simulation environments due to the high cost and safety concerns of interactions in the real world. Demonstration Learning is a paradigm in which an agent learns to perform a task by imitating the behavior of an expert shown in demonstrations. It is a relatively recent area in machine learning, but it is gaining significant traction due to having tremendous potential for learning complex behaviors from demonstrations. Learning from demonstration accelerates the learning process by improving sample efficiency, while also reducing the effort of the programmer. Due to learning without interacting with the environment, demonstration learning would allow the automation of a wide range of real world applications such as robotics and healthcare. This paper provides a survey of demonstration learning, where we formally introduce the demonstration problem along with its main challenges and provide a comprehensive overview of the process of learning from demonstrations from the creation of the demonstration data set, to learning methods from demonstrations, and optimization by combining demonstration learning with different machine learning methods. We also review the existing benchmarks and identify their strengths and limitations. Additionally, we discuss the advantages and disadvantages of the paradigm as well as its main applications. Lastly, we discuss our perspective on open problems and research directions for this rapidly growing field.
Hierarchical Decision Transformer
Sep 21, 2022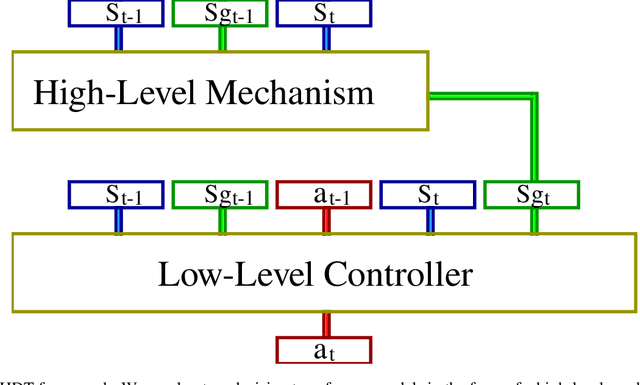
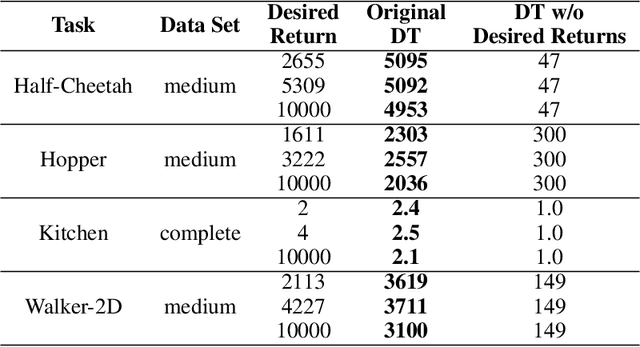
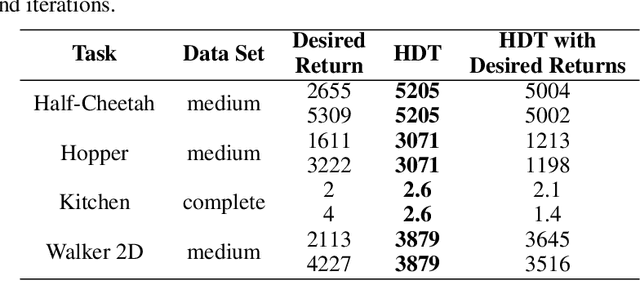
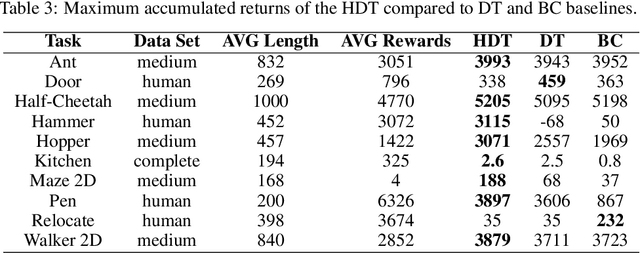
Sequence models in reinforcement learning require task knowledge to estimate the task policy. This paper presents a hierarchical algorithm for learning a sequence model from demonstrations. The high-level mechanism guides the low-level controller through the task by selecting sub-goals for the latter to reach. This sequence replaces the returns-to-go of previous methods, improving its performance overall, especially in tasks with longer episodes and scarcer rewards. We validate our method in multiple tasks of OpenAIGym, D4RL and RoboMimic benchmarks. Our method outperforms the baselines in eight out of ten tasks of varied horizons and reward frequencies without prior task knowledge, showing the advantages of the hierarchical model approach for learning from demonstrations using a sequence model.
Energy-Aware JPEG Image Compression: A Multi-Objective Approach
Sep 09, 2022
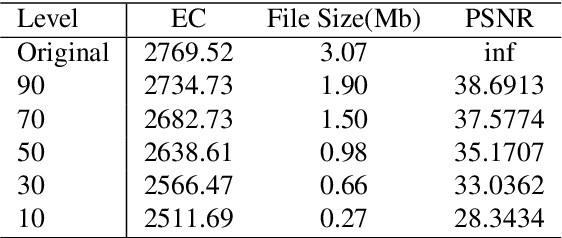
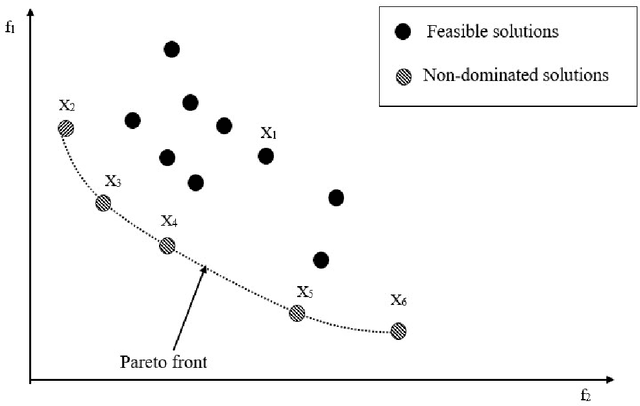
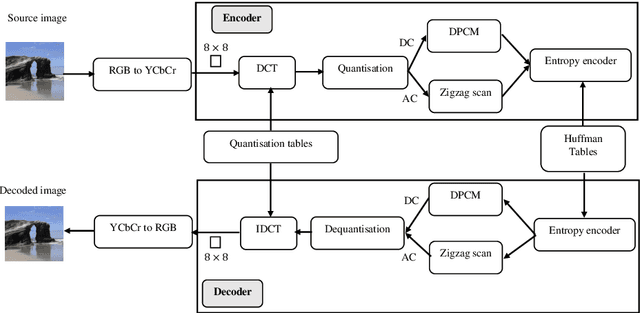
Customer satisfaction is crucially affected by energy consumption in mobile devices. One of the most energy-consuming parts of an application is images. While different images with different quality consume different amounts of energy, there are no straightforward methods to calculate the energy consumption of an operation in a typical image. This paper, first, investigates that there is a correlation between energy consumption and image quality as well as image file size. Therefore, these two can be considered as a proxy for energy consumption. Then, we propose a multi-objective strategy to enhance image quality and reduce image file size based on the quantisation tables in JPEG image compression. To this end, we have used two general multi-objective metaheuristic approaches: scalarisation and Pareto-based. Scalarisation methods find a single optimal solution based on combining different objectives, while Pareto-based techniques aim to achieve a set of solutions. In this paper, we embed our strategy into five scalarisation algorithms, including energy-aware multi-objective genetic algorithm (EnMOGA), energy-aware multi-objective particle swarm optimisation (EnMOPSO), energy-aware multi-objective differential evolution (EnMODE), energy-aware multi-objective evolutionary strategy (EnMOES), and energy-aware multi-objective pattern search (EnMOPS). Also, two Pareto-based methods, including a non-dominated sorting genetic algorithm (NSGA-II) and a reference-point-based NSGA-II (NSGA-III) are used for the embedding scheme, and two Pareto-based algorithms, EnNSGAII and EnNSGAIII, are presented. Experimental studies show that the performance of the baseline algorithm is improved by embedding the proposed strategy into metaheuristic algorithms.
Exploration, Path Planning with Obstacle and Collision Avoidance in a Dynamic Environment
Aug 19, 2022
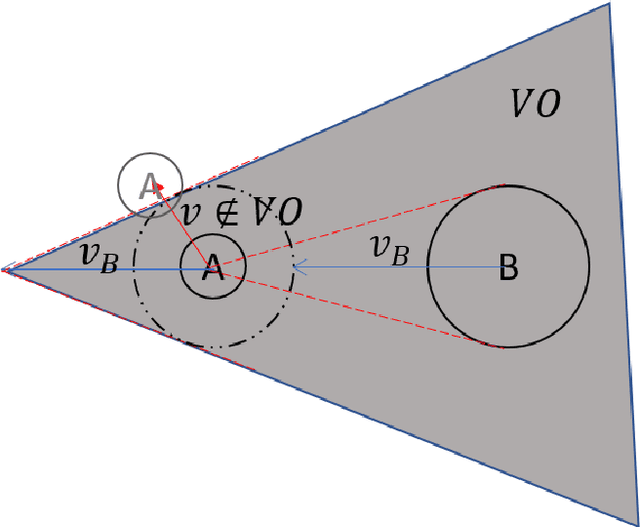

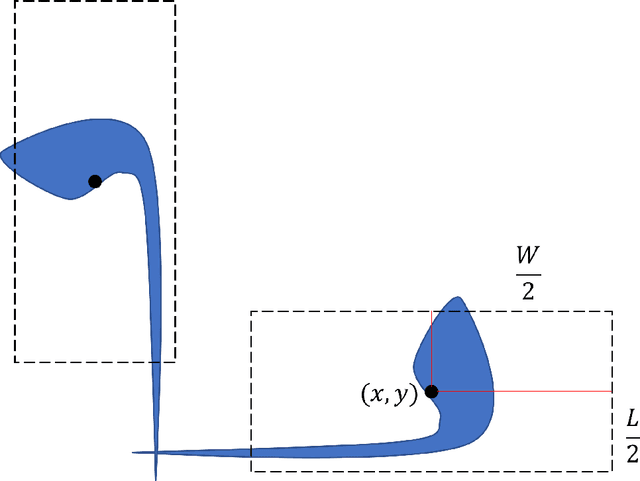
If we give a robot the task of moving an object from its current position to another location in an unknown environment, the robot must explore the map, identify all types of obstacles, and then determine the best route to complete the task. We proposed a mathematical model to find an optimal path planning that avoids collisions with all static and moving obstacles and has the minimum completion time and the minimum distance traveled. In this model, the bounding box around obstacles and robots is not considered, so the robot can move very close to the obstacles without colliding with them. We considered two types of obstacles: deterministic, which include all static obstacles such as walls that do not move and all moving obstacles whose movements have a fixed pattern, and non-deterministic, which include all obstacles whose movements can occur in any direction with some probability distribution at any time. We also consider the acceleration and deceleration of the robot to improve collision avoidance.