 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMusic to Dance as Language Translation using Sequence Models
Paper and Code
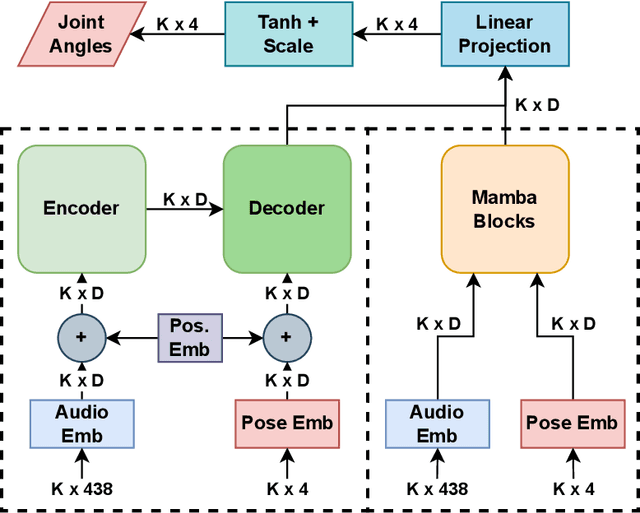
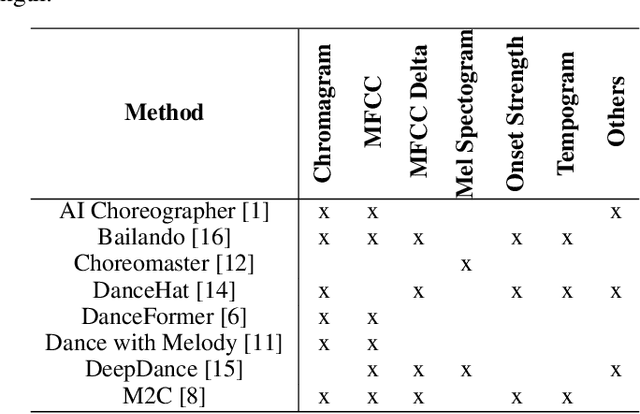
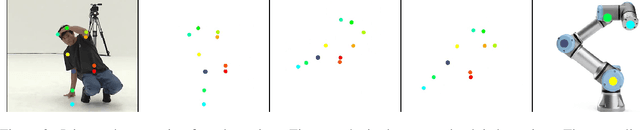
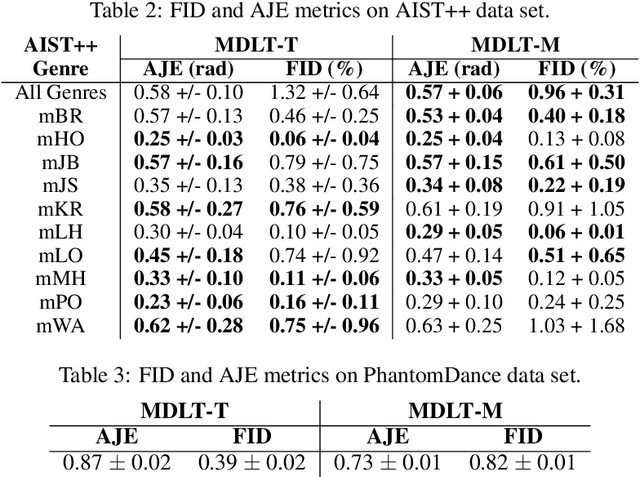
Synthesising appropriate choreographies from music remains an open problem. We introduce MDLT, a novel approach that frames the choreography generation problem as a translation task. Our method leverages an existing data set to learn to translate sequences of audio into corresponding dance poses. We present two variants of MDLT: one utilising the Transformer architecture and the other employing the Mamba architecture. We train our method on AIST++ and PhantomDance data sets to teach a robotic arm to dance, but our method can be applied to a full humanoid robot. Evaluation metrics, including Average Joint Error and Frechet Inception Distance, consistently demonstrate that, when given a piece of music, MDLT excels at producing realistic and high-quality choreography. The code can be found at github.com/meowatthemoon/MDLT.