 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeHierarchical Decision Mamba
May 13, 2024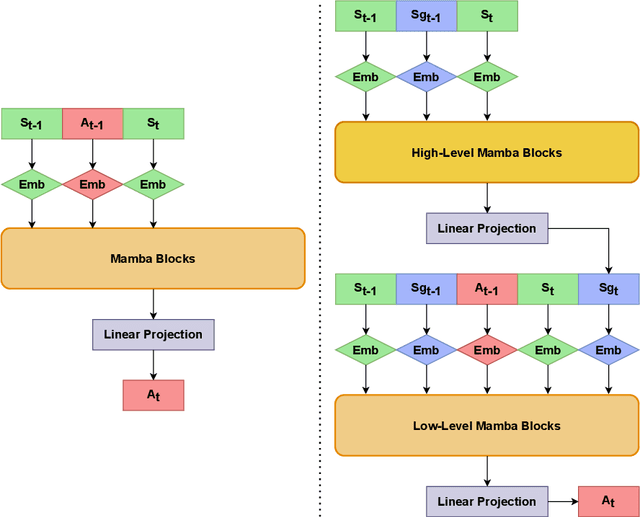



Recent advancements in imitation learning have been largely fueled by the integration of sequence models, which provide a structured flow of information to effectively mimic task behaviours. Currently, Decision Transformer (DT) and subsequently, the Hierarchical Decision Transformer (HDT), presented Transformer-based approaches to learn task policies. Recently, the Mamba architecture has shown to outperform Transformers across various task domains. In this work, we introduce two novel methods, Decision Mamba (DM) and Hierarchical Decision Mamba (HDM), aimed at enhancing the performance of the Transformer models. Through extensive experimentation across diverse environments such as OpenAI Gym and D4RL, leveraging varying demonstration data sets, we demonstrate the superiority of Mamba models over their Transformer counterparts in a majority of tasks. Results show that HDM outperforms other methods in most settings. The code can be found at https://github.com/meowatthemoon/HierarchicalDecisionMamba.
Music to Dance as Language Translation using Sequence Models
Mar 22, 2024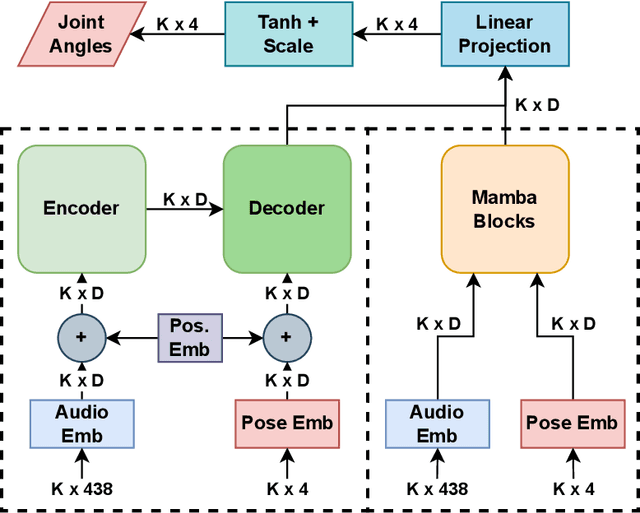
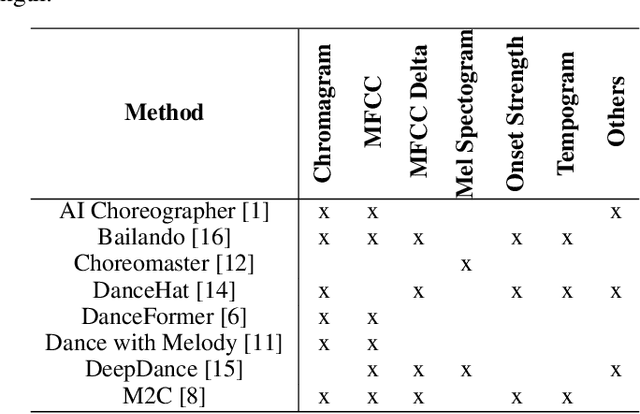
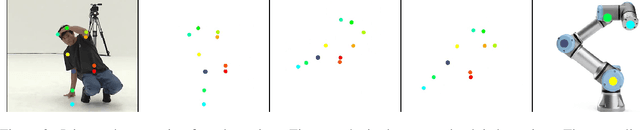
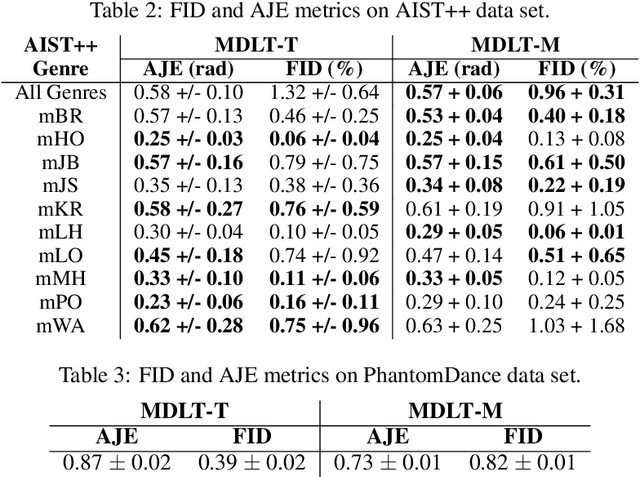
Synthesising appropriate choreographies from music remains an open problem. We introduce MDLT, a novel approach that frames the choreography generation problem as a translation task. Our method leverages an existing data set to learn to translate sequences of audio into corresponding dance poses. We present two variants of MDLT: one utilising the Transformer architecture and the other employing the Mamba architecture. We train our method on AIST++ and PhantomDance data sets to teach a robotic arm to dance, but our method can be applied to a full humanoid robot. Evaluation metrics, including Average Joint Error and Frechet Inception Distance, consistently demonstrate that, when given a piece of music, MDLT excels at producing realistic and high-quality choreography. The code can be found at github.com/meowatthemoon/MDLT.
DEFENDER: DTW-Based Episode Filtering Using Demonstrations for Enhancing RL Safety
May 08, 2023


Deploying reinforcement learning agents in the real world can be challenging due to the risks associated with learning through trial and error. We propose a task-agnostic method that leverages small sets of safe and unsafe demonstrations to improve the safety of RL agents during learning. The method compares the current trajectory of the agent with both sets of demonstrations at every step, and filters the trajectory if it resembles the unsafe demonstrations. We perform ablation studies on different filtering strategies and investigate the impact of the number of demonstrations on performance. Our method is compatible with any stand-alone RL algorithm and can be applied to any task. We evaluate our method on three tasks from OpenAI Gym's Mujoco benchmark and two state-of-the-art RL algorithms. The results demonstrate that our method significantly reduces the crash rate of the agent while converging to, and in most cases even improving, the performance of the stand-alone agent.
A Survey of Demonstration Learning
Mar 20, 2023
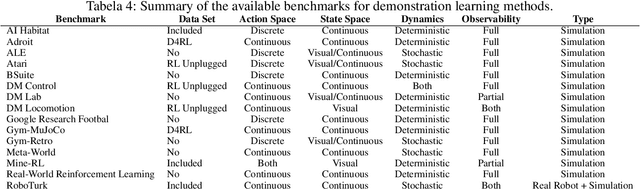

With the fast improvement of machine learning, reinforcement learning (RL) has been used to automate human tasks in different areas. However, training such agents is difficult and restricted to expert users. Moreover, it is mostly limited to simulation environments due to the high cost and safety concerns of interactions in the real world. Demonstration Learning is a paradigm in which an agent learns to perform a task by imitating the behavior of an expert shown in demonstrations. It is a relatively recent area in machine learning, but it is gaining significant traction due to having tremendous potential for learning complex behaviors from demonstrations. Learning from demonstration accelerates the learning process by improving sample efficiency, while also reducing the effort of the programmer. Due to learning without interacting with the environment, demonstration learning would allow the automation of a wide range of real world applications such as robotics and healthcare. This paper provides a survey of demonstration learning, where we formally introduce the demonstration problem along with its main challenges and provide a comprehensive overview of the process of learning from demonstrations from the creation of the demonstration data set, to learning methods from demonstrations, and optimization by combining demonstration learning with different machine learning methods. We also review the existing benchmarks and identify their strengths and limitations. Additionally, we discuss the advantages and disadvantages of the paradigm as well as its main applications. Lastly, we discuss our perspective on open problems and research directions for this rapidly growing field.
Hierarchical Decision Transformer
Sep 21, 2022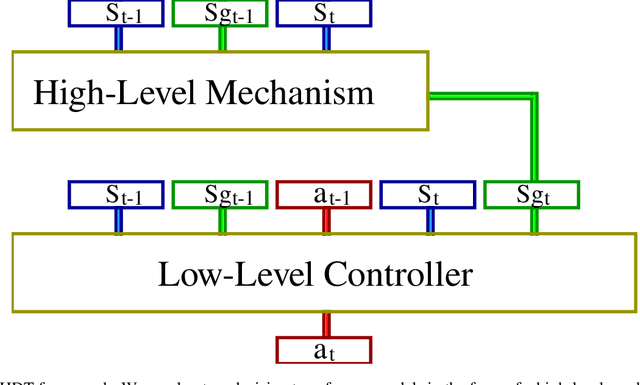
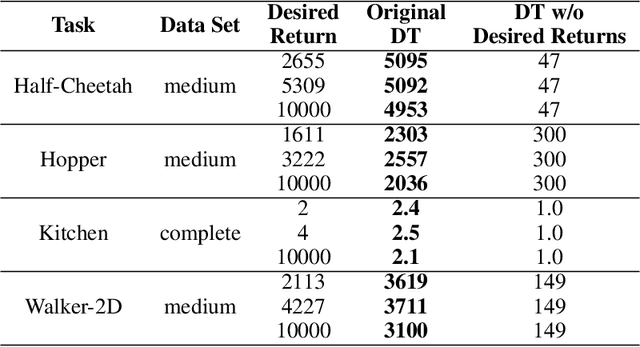
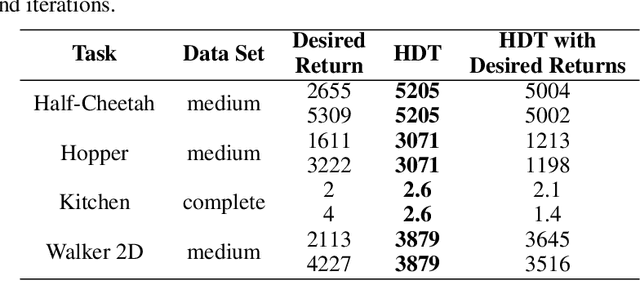
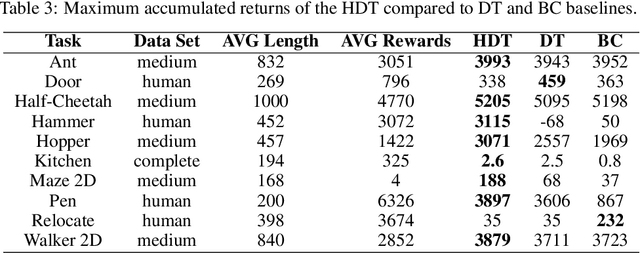
Sequence models in reinforcement learning require task knowledge to estimate the task policy. This paper presents a hierarchical algorithm for learning a sequence model from demonstrations. The high-level mechanism guides the low-level controller through the task by selecting sub-goals for the latter to reach. This sequence replaces the returns-to-go of previous methods, improving its performance overall, especially in tasks with longer episodes and scarcer rewards. We validate our method in multiple tasks of OpenAIGym, D4RL and RoboMimic benchmarks. Our method outperforms the baselines in eight out of ten tasks of varied horizons and reward frequencies without prior task knowledge, showing the advantages of the hierarchical model approach for learning from demonstrations using a sequence model.
Contrastive Learning from Demonstrations
Jan 30, 2022



This paper presents a framework for learning visual representations from unlabeled video demonstrations captured from multiple viewpoints. We show that these representations are applicable for imitating several robotic tasks, including pick and place. We optimize a recently proposed self-supervised learning algorithm by applying contrastive learning to enhance task-relevant information while suppressing irrelevant information in the feature embeddings. We validate the proposed method on the publicly available Multi-View Pouring and a custom Pick and Place data sets and compare it with the TCN triplet baseline. We evaluate the learned representations using three metrics: viewpoint alignment, stage classification and reinforcement learning, and in all cases the results improve when compared to state-of-the-art approaches, with the added benefit of reduced number of training iterations.
Optimal Algorithm Allocation for Robotic Network Cloud Systems
Apr 26, 2021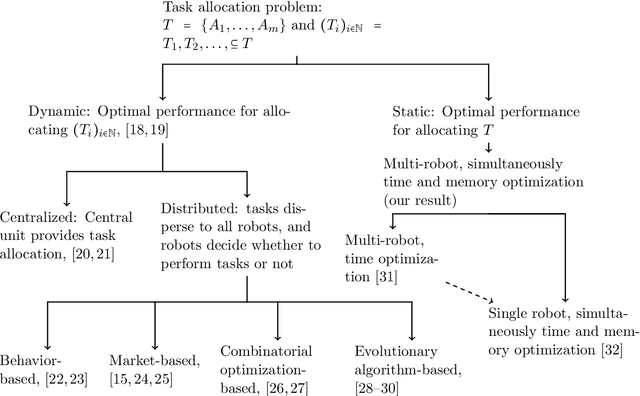

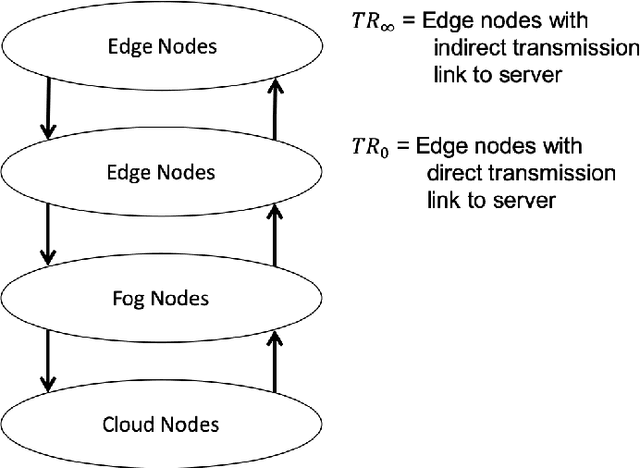

Cloud robotics enables robots to benefit from the massive storage and computational power of the cloud, overcoming the capacity limitations of cooperative robots. When the decision is made to use a robotic network cloud system to execute a task or a set of tasks, the main goal will be to use the cheapest, in terms of smallest memory, and fastest, in terms of shortest execution time, robots. Previous studies have mainly focused on minimizing the cost of the robots in retrieving resources by knowing the resource allocation in advance. When a task arrives in the system, it can be assigned to any processing unit, one of the robots, an eventual fog node or the cloud, and the question is where a task should be processed to optimize performance. Here, we develop a method for a robotic network cloud system to determine where each algorithm should be allocated for the system to achieve optimal performance, regardless of which robot initiates the request. We can find the minimum required memory for the robots and the optimal way to allocate the algorithms with the shortest time to complete each task. We show how our proposed method works, and we experimentally compare its performance with a state-of-the-art method, using real-world data, showing the improvements that can be obtained.