 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAre Neural Architecture Search Benchmarks Well Designed? A Deeper Look Into Operation Importance
Mar 29, 2023Neural Architecture Search (NAS) benchmarks significantly improved the capability of developing and comparing NAS methods while at the same time drastically reduced the computational overhead by providing meta-information about thousands of trained neural networks. However, tabular benchmarks have several drawbacks that can hinder fair comparisons and provide unreliable results. These usually focus on providing a small pool of operations in heavily constrained search spaces -- usually cell-based neural networks with pre-defined outer-skeletons. In this work, we conducted an empirical analysis of the widely used NAS-Bench-101, NAS-Bench-201 and TransNAS-Bench-101 benchmarks in terms of their generability and how different operations influence the performance of the generated architectures. We found that only a subset of the operation pool is required to generate architectures close to the upper-bound of the performance range. Also, the performance distribution is negatively skewed, having a higher density of architectures in the upper-bound range. We consistently found convolution layers to have the highest impact on the architecture's performance, and that specific combination of operations favors top-scoring architectures. These findings shed insights on the correct evaluation and comparison of NAS methods using NAS benchmarks, showing that directly searching on NAS-Bench-201, ImageNet16-120 and TransNAS-Bench-101 produces more reliable results than searching only on CIFAR-10. Furthermore, with this work we provide suggestions for future benchmark evaluations and design. The code used to conduct the evaluations is available at https://github.com/VascoLopes/NAS-Benchmark-Evaluation.
Guided Evolution for Neural Architecture Search
Oct 28, 2021
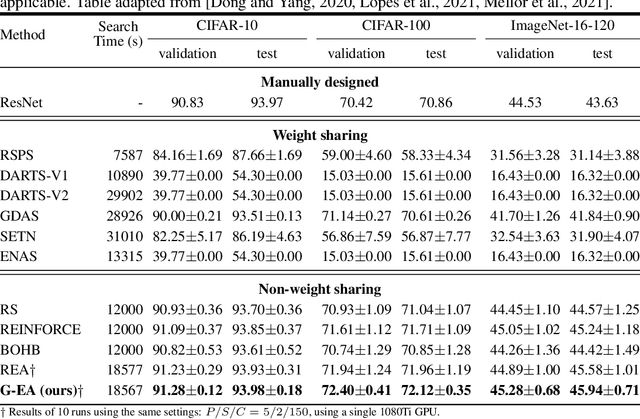

Neural Architecture Search (NAS) methods have been successfully applied to image tasks with excellent results. However, NAS methods are often complex and tend to converge to local minima as soon as generated architectures seem to yield good results. In this paper, we propose G-EA, a novel approach for guided evolutionary NAS. The rationale behind G-EA, is to explore the search space by generating and evaluating several architectures in each generation at initialization stage using a zero-proxy estimator, where only the highest-scoring network is trained and kept for the next generation. This evaluation at initialization stage allows continuous extraction of knowledge from the search space without increasing computation, thus allowing the search to be efficiently guided. Moreover, G-EA forces exploitation of the most performant networks by descendant generation while at the same time forcing exploration by parent mutation and by favouring younger architectures to the detriment of older ones. Experimental results demonstrate the effectiveness of the proposed method, showing that G-EA achieves state-of-the-art results in NAS-Bench-201 search space in CIFAR-10, CIFAR-100 and ImageNet16-120, with mean accuracies of 93.98%, 72.12% and 45.94% respectively.
Generative Adversarial Graph Convolutional Networks for Human Action Synthesis
Oct 25, 2021
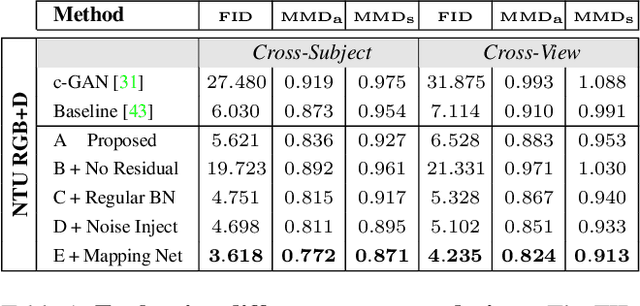


Synthesising the spatial and temporal dynamics of the human body skeleton remains a challenging task, not only in terms of the quality of the generated shapes, but also of their diversity, particularly to synthesise realistic body movements of a specific action (action conditioning). In this paper, we propose Kinetic-GAN, a novel architecture that leverages the benefits of Generative Adversarial Networks and Graph Convolutional Networks to synthesise the kinetics of the human body. The proposed adversarial architecture can condition up to 120 different actions over local and global body movements while improving sample quality and diversity through latent space disentanglement and stochastic variations. Our experiments were carried out in three well-known datasets, where Kinetic-GAN notably surpasses the state-of-the-art methods in terms of distribution quality metrics while having the ability to synthesise more than one order of magnitude regarding the number of different actions. Our code and models are publicly available at https://github.com/DegardinBruno/Kinetic-GAN.
REGINA - Reasoning Graph Convolutional Networks in Human Action Recognition
May 14, 2021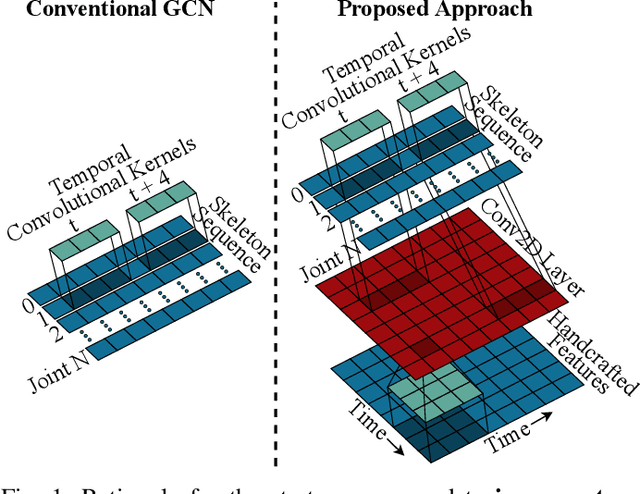

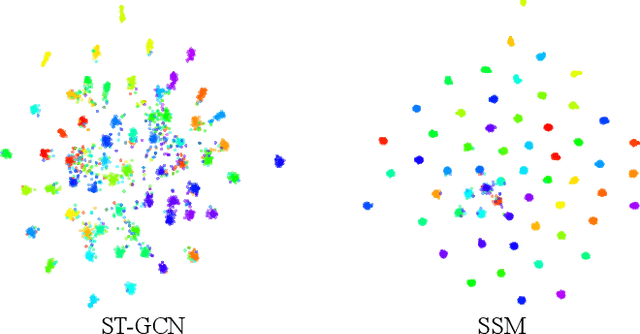
It is known that the kinematics of the human body skeleton reveals valuable information in action recognition. Recently, modeling skeletons as spatio-temporal graphs with Graph Convolutional Networks (GCNs) has been reported to solidly advance the state-of-the-art performance. However, GCN-based approaches exclusively learn from raw skeleton data, and are expected to extract the inherent structural information on their own. This paper describes REGINA, introducing a novel way to REasoning Graph convolutional networks IN Human Action recognition. The rationale is to provide to the GCNs additional knowledge about the skeleton data, obtained by handcrafted features, in order to facilitate the learning process, while guaranteeing that it remains fully trainable in an end-to-end manner. The challenge is to capture complementary information over the dynamics between consecutive frames, which is the key information extracted by state-of-the-art GCN techniques. Moreover, the proposed strategy can be easily integrated in the existing GCN-based methods, which we also regard positively. Our experiments were carried out in well known action recognition datasets and enabled to conclude that REGINA contributes for solid improvements in performance when incorporated to other GCN-based approaches, without any other adjustment regarding the original method. For reproducibility, the REGINA code and all the experiments carried out will be publicly available at https://github.com/DegardinBruno.