 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSelect High-Level Features: Efficient Experts from a Hierarchical Classification Network
Mar 08, 2024

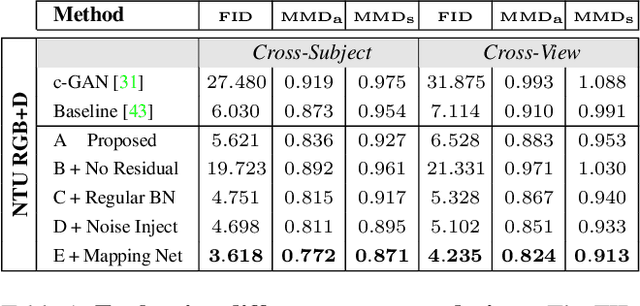
This study introduces a novel expert generation method that dynamically reduces task and computational complexity without compromising predictive performance. It is based on a new hierarchical classification network topology that combines sequential processing of generic low-level features with parallelism and nesting of high-level features. This structure allows for the innovative extraction technique: the ability to select only high-level features of task-relevant categories. In certain cases, it is possible to skip almost all unneeded high-level features, which can significantly reduce the inference cost and is highly beneficial in resource-constrained conditions. We believe this method paves the way for future network designs that are lightweight and adaptable, making them suitable for a wide range of applications, from compact edge devices to large-scale clouds. In terms of dynamic inference our methodology can achieve an exclusion of up to 88.7\,\% of parameters and 73.4\,\% fewer giga-multiply accumulate (GMAC) operations, analysis against comparative baselines showing an average reduction of 47.6\,\% in parameters and 5.8\,\% in GMACs across the cases we evaluated.
High-Level Features Parallelization for Inference Cost Reduction Through Selective Attention
Aug 09, 2023



In this work, we parallelize high-level features in deep networks to selectively skip or select class-specific features to reduce inference costs. This challenges most deep learning methods due to their limited ability to efficiently and effectively focus on selected class-specific features without retraining. We propose a serial-parallel hybrid architecture with serial generic low-level features and parallel high-level features. This accounts for the fact that many high-level features are class-specific rather than generic, and has connections to recent neuroscientific findings that observe spatially and contextually separated neural activations in the human brain. Our approach provides the unique functionality of cutouts: selecting parts of the network to focus on only relevant subsets of classes without requiring retraining. High performance is maintained, but the cost of inference can be significantly reduced. In some of our examples, up to $75\,\%$ of parameters are skipped and $35\,\%$ fewer GMACs (Giga multiply-accumulate) operations are used as the approach adapts to a change in task complexity. This is important for mobile, industrial, and robotic applications where reducing the number of parameters, the computational complexity, and thus the power consumption can be paramount. Another unique functionality is that it allows processing to be directly influenced by enhancing or inhibiting high-level class-specific features, similar to the mechanism of selective attention in the human brain. This can be relevant for cross-modal applications, the use of semantic prior knowledge, and/or context-aware processing.
Generative Adversarial Graph Convolutional Networks for Human Action Synthesis
Oct 25, 2021


Synthesising the spatial and temporal dynamics of the human body skeleton remains a challenging task, not only in terms of the quality of the generated shapes, but also of their diversity, particularly to synthesise realistic body movements of a specific action (action conditioning). In this paper, we propose Kinetic-GAN, a novel architecture that leverages the benefits of Generative Adversarial Networks and Graph Convolutional Networks to synthesise the kinetics of the human body. The proposed adversarial architecture can condition up to 120 different actions over local and global body movements while improving sample quality and diversity through latent space disentanglement and stochastic variations. Our experiments were carried out in three well-known datasets, where Kinetic-GAN notably surpasses the state-of-the-art methods in terms of distribution quality metrics while having the ability to synthesise more than one order of magnitude regarding the number of different actions. Our code and models are publicly available at https://github.com/DegardinBruno/Kinetic-GAN.
A Symbolic Temporal Pooling method for Video-based Person Re-Identification
Jun 19, 2020



In video-based person re-identification, both the spatial and temporal features are known to provide orthogonal cues to effective representations. Such representations are currently typically obtained by aggregating the frame-level features using max/avg pooling, at different points of the models. However, such operations also decrease the amount of discriminating information available, which is particularly hazardous in case of poor separability between the different classes. To alleviate this problem, this paper introduces a symbolic temporal pooling method, where frame-level features are represented in the distribution valued symbolic form, yielding from fitting an Empirical Cumulative Distribution Function (ECDF) to each feature. Also, considering that the original triplet loss formulation cannot be applied directly to this kind of representations, we introduce a symbolic triplet loss function that infers the similarity between two symbolic objects. Having carried out an extensive empirical evaluation of the proposed solution against the state-of-the-art, in four well known data sets (MARS, iLIDS-VID, PRID2011 and P-DESTRE), the observed results point for consistent improvements in performance over the previous best performing techniques.
The P-DESTRE: A Fully Annotated Dataset for Pedestrian Detection, Tracking, Re-Identification and Search from Aerial Devices
Apr 06, 2020
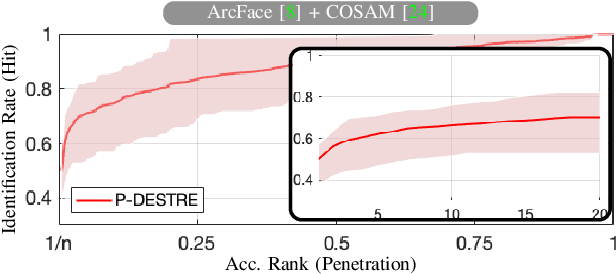

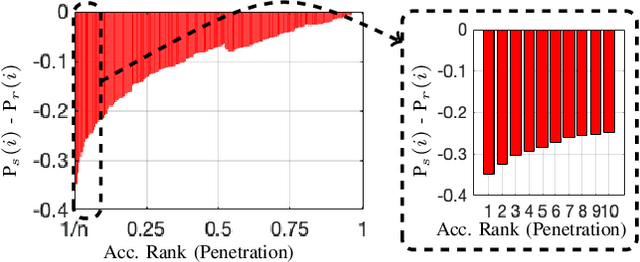
Over the last decades, the world has been witnessing growing threats to the security in urban spaces, which has augmented the relevance given to visual surveillance solutions able to detect, track and identify persons of interest in crowds. In particular, unmanned aerial vehicles (UAVs) are a potential tool for this kind of analysis, as they provide a cheap way for data collection, cover large and difficult-to-reach areas, while reducing human staff demands. In this context, all the available datasets are exclusively suitable for the pedestrian re-identification problem, in which the multi-camera views per ID are taken on a single day, and allows the use of clothing appearance features for identification purposes. Accordingly, the main contributions of this paper are two-fold: 1) we announce the UAV-based P-DESTRE dataset, which is the first of its kind to provide consistent ID annotations across multiple days, making it suitable for the extremely challenging problem of person search, i.e., where no clothing information can be reliably used. Apart this feature, the P-DESTRE annotations enable the research on UAV-based pedestrian detection, tracking, re-identification and soft biometric solutions; and 2) we compare the results attained by state-of-the-art pedestrian detection, tracking, reidentification and search techniques in well-known surveillance datasets, to the effectiveness obtained by the same techniques in the P-DESTRE data. Such comparison enables to identify the most problematic data degradation factors of UAV-based data for each task, and can be used as baselines for subsequent advances in this kind of technology. The dataset and the full details of the empirical evaluation carried out are freely available at http://p-destre.di.ubi.pt/.
An Attention-Based Deep Learning Model for Multiple Pedestrian Attributes Recognition
Apr 02, 2020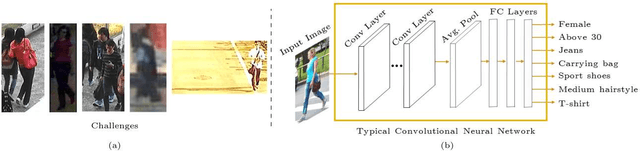

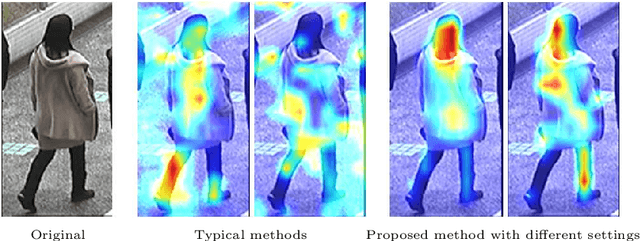
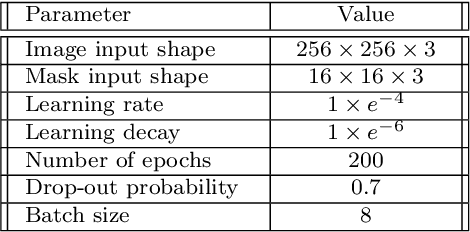
The automatic characterization of pedestrians in surveillance footage is a tough challenge, particularly when the data is extremely diverse with cluttered backgrounds, and subjects are captured from varying distances, under multiple poses, with partial occlusion. Having observed that the state-of-the-art performance is still unsatisfactory, this paper provides a novel solution to the problem, with two-fold contributions: 1) considering the strong semantic correlation between the different full-body attributes, we propose a multi-task deep model that uses an element-wise multiplication layer to extract more comprehensive feature representations. In practice, this layer serves as a filter to remove irrelevant background features, and is particularly important to handle complex, cluttered data; and 2) we introduce a weighted-sum term to the loss function that not only relativizes the contribution of each task (kind of attributed) but also is crucial for performance improvement in multiple-attribute inference settings. Our experiments were performed on two well-known datasets (RAP and PETA) and point for the superiority of the proposed method with respect to the state-of-the-art. The code is available at https://github.com/Ehsan-Yaghoubi/MAN-PAR-.
A Quadruplet Loss for Enforcing Semantically Coherent Embeddings in Multi-output Classification Problems
Mar 20, 2020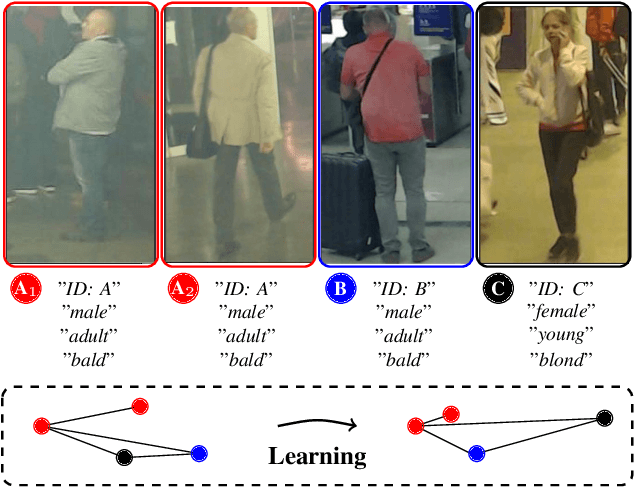
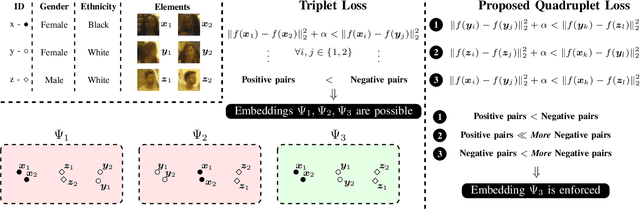
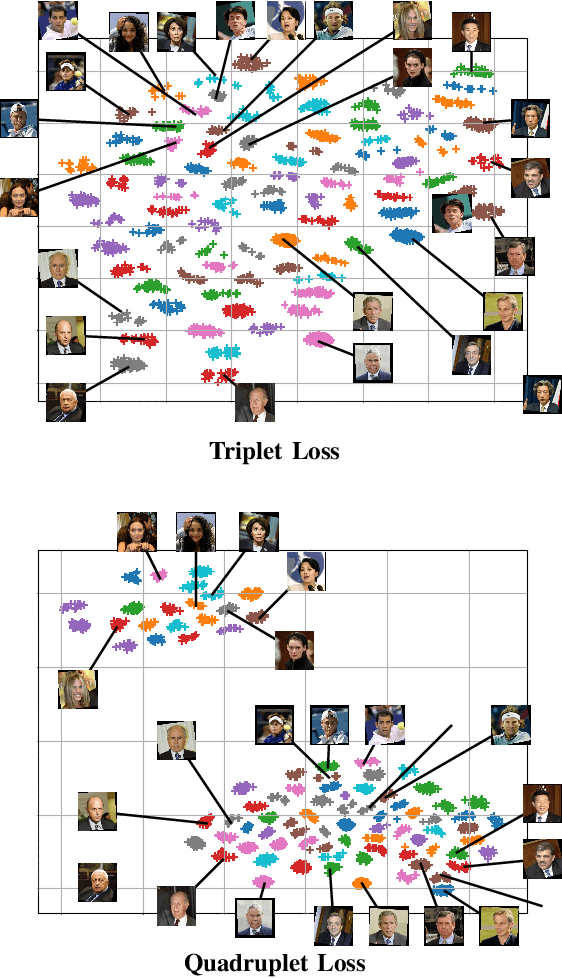
This paper describes one objective function for learning semantically coherent feature embeddings in multi-output classification problems, i.e., when the response variables have dimension higher than one. In particular, we consider the problems of identity retrieval and soft biometrics labelling in visual surveillance environments, which have been attracting growing interests. Inspired by the triplet loss [34] function, we propose a generalization that: 1) defines a metric that considers the number of agreeing labels between pairs of elements; and 2) disregards the notion of anchor, replacing d(A1, A2) < d(A1, B) by d(A, B) < d(C, D), for A, B, C, D distance constraints, according to the number of agreeing labels between pairs. As the triplet loss formulation, our proposal also privileges small distances between positive pairs, but at the same time explicitly enforces that the distance between other pairs corresponds directly to their similarity in terms of agreeing labels. This yields feature embeddings with a strong correspondence between the classes centroids and their semantic descriptions, i.e., where elements are closer to others that share some of their labels than to elements with fully disjoint labels membership. As practical effect, the proposed loss can be seen as particularly suitable for performing joint coarse (soft label) + fine (ID) inference, based on simple rules as k-neighbours, which is a novelty with respect to previous related loss functions. Also, in opposition to its triplet counterpart, the proposed loss is agnostic with regard to any demanding criteria for mining learning instances (such as the semi-hard pairs). Our experiments were carried out in five different datasets (BIODI, LFW, IJB-A, Megaface and PETA) and validate our assumptions, showing highly promising results.
An Implicit Attention Mechanism for Deep Learning Pedestrian Re-identification Frameworks
Jan 31, 2020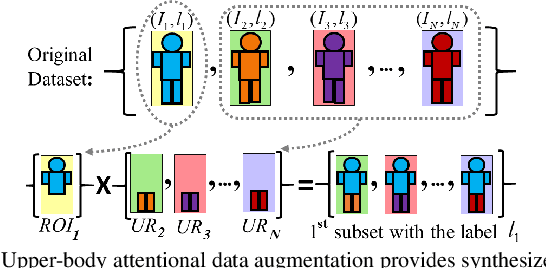
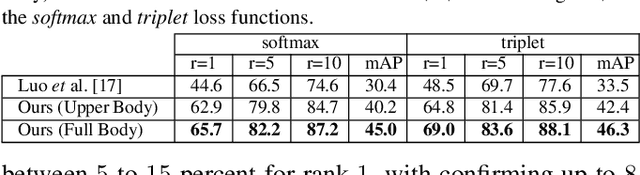

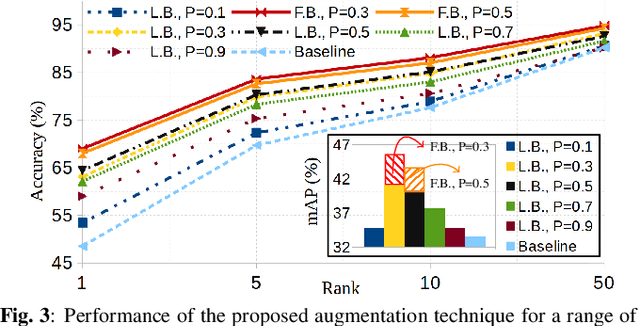
Attention is defined as the preparedness for the mental selection of certain aspects in a physical environment. In the computer vision domain, this mechanism is of most interest, as it helps to define the segments of an image/video that are critical for obtaining a specific decision. This paper introduces one 'implicit' attentional mechanism for deep learning frameworks, that provides simultaneously: 1) masks-free; and 2) foreground-focused samples for the inference phase. The main idea is to generate synthetic data composed of interleaved segments from the original learning set, while using class information only from specific segments. During the learning phase, the newly generated samples feed the network, keeping their label exclusively consistent with the identity from where the region-of-interest was cropped. Hence, as the model receives images of each identity with inconsistent unwanted areas, it naturally pays the most attention to the label consistent consistent regions, which we observed to be equivalent to learn an effective receptive field. During the test phase, samples are provided without any mask, and the network naturally disregards the detrimental information, which is the insight for the observed improvements in performance. As a proof-of-concept, we consider the challenging problem of pedestrian re-identification and compare the effectiveness of our solution to the state-of-the-art techniques in the well known Richly Annotated Pedestrian (RAP) dataset. The code is available at https://github.com/Ehsan-Yaghoubi/reid-strong-baseline.