 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAn Attention-Based Deep Learning Model for Multiple Pedestrian Attributes Recognition
Apr 02, 2020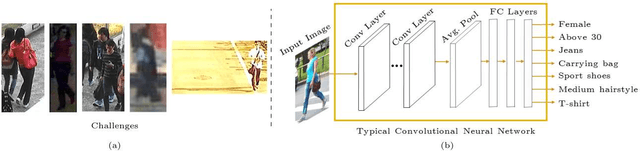

The automatic characterization of pedestrians in surveillance footage is a tough challenge, particularly when the data is extremely diverse with cluttered backgrounds, and subjects are captured from varying distances, under multiple poses, with partial occlusion. Having observed that the state-of-the-art performance is still unsatisfactory, this paper provides a novel solution to the problem, with two-fold contributions: 1) considering the strong semantic correlation between the different full-body attributes, we propose a multi-task deep model that uses an element-wise multiplication layer to extract more comprehensive feature representations. In practice, this layer serves as a filter to remove irrelevant background features, and is particularly important to handle complex, cluttered data; and 2) we introduce a weighted-sum term to the loss function that not only relativizes the contribution of each task (kind of attributed) but also is crucial for performance improvement in multiple-attribute inference settings. Our experiments were performed on two well-known datasets (RAP and PETA) and point for the superiority of the proposed method with respect to the state-of-the-art. The code is available at https://github.com/Ehsan-Yaghoubi/MAN-PAR-.
An Implicit Attention Mechanism for Deep Learning Pedestrian Re-identification Frameworks
Jan 31, 2020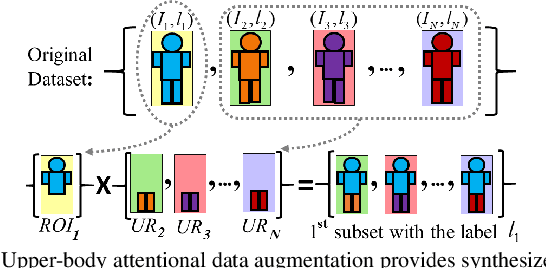
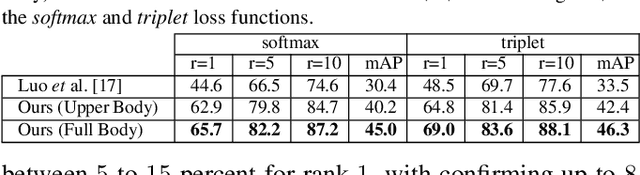

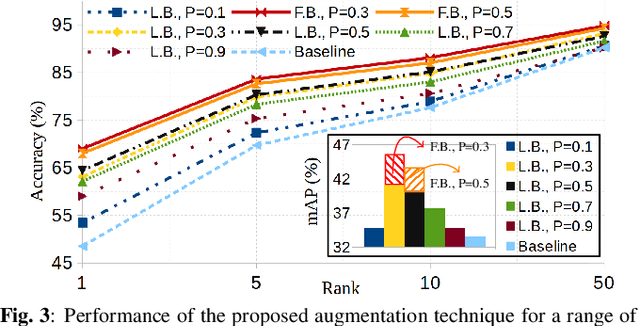
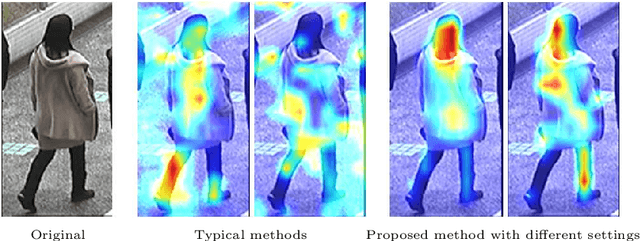
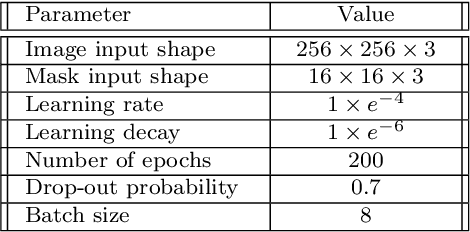
Attention is defined as the preparedness for the mental selection of certain aspects in a physical environment. In the computer vision domain, this mechanism is of most interest, as it helps to define the segments of an image/video that are critical for obtaining a specific decision. This paper introduces one 'implicit' attentional mechanism for deep learning frameworks, that provides simultaneously: 1) masks-free; and 2) foreground-focused samples for the inference phase. The main idea is to generate synthetic data composed of interleaved segments from the original learning set, while using class information only from specific segments. During the learning phase, the newly generated samples feed the network, keeping their label exclusively consistent with the identity from where the region-of-interest was cropped. Hence, as the model receives images of each identity with inconsistent unwanted areas, it naturally pays the most attention to the label consistent consistent regions, which we observed to be equivalent to learn an effective receptive field. During the test phase, samples are provided without any mask, and the network naturally disregards the detrimental information, which is the insight for the observed improvements in performance. As a proof-of-concept, we consider the challenging problem of pedestrian re-identification and compare the effectiveness of our solution to the state-of-the-art techniques in the well known Richly Annotated Pedestrian (RAP) dataset. The code is available at https://github.com/Ehsan-Yaghoubi/reid-strong-baseline.