 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeGeneralization Under Scrutiny: Cross-Domain Detection Progresses, Pitfalls, and Persistent Challenges
Apr 09, 2026Object detection models trained on a source domain often exhibit significant performance degradation when deployed in unseen target domains, due to various kinds of variations, such as sensing conditions, environments and data distributions. Hence, regardless the recent breakthrough advances in deep learning-based detection technology, cross-domain object detection (CDOD) remains a critical research area. Moreover, the existing literature remains fragmented, lacking a unified perspective on the structural challenges underlying domain shift and the effectiveness of adaptation strategies. This survey provides a comprehensive and systematic analysis of CDOD. We start upon a problem formulation that highlights the multi-stage nature of object detection under domain shift. Then, we organize the existing methods through a conceptual taxonomy that categorizes approaches based on adaptation paradigms, modeling assumptions, and pipeline components. Furthermore, we analyze how domain shift propagates across detection stages and discuss why adaptation in object detection is inherently more complex than in classification. In addition, we review commonly used datasets, evaluation protocols, and benchmarking practices. Finally, we identify the key challenges and outline promising future research directions. Cohesively, this survey aims to provide a unified framework for understanding CDOD and to guide the development of more robust detection systems.
SRL-MAD: Structured Residual Latents for One-Class Morphing Attack Detection
Mar 16, 2026Face morphing attacks represent a significant threat to biometric systems as they allow multiple identities to be combined into a single face. While supervised morphing attack detection (MAD) methods have shown promising performance, their reliance on attack-labeled data limits generalization to unseen morphing attacks. This has motivated increasing interest in one-class MAD, where models are trained exclusively on bona fide samples and are expected to detect unseen attacks as deviations from the normal facial structure. In this context, we introduce SRL-MAD, a one-class single-image MAD that uses structured residual Fourier representations for open-set morphing attack detection. Starting from a residual frequency map that suppresses image-specific spectral trends, we preserve the two-dimensional organization of the Fourier domain through a ring-based representation and replace azimuthal averaging with a learnable ring-wise spectral projection. To further encode domain knowledge about where morphing artifacts arise, we impose a frequency-informed inductive bias by organizing spectral evidence into low, mid, and high-frequency bands and learning cross-band interactions. These structured spectral features are mapped into a latent space designed for direct scoring, avoiding the reliance on reconstruction errors. Extensive evaluation on FERET-Morph, FRLL-Morph, and MorDIFF demonstrates that SRL-MAD consistently outperforms recent one-class and supervised MAD models. Overall, our results show that learning frequency-aware projections provides a more discriminative alternative to azimuthal spectral summarization for one-class morphing attack detection.
The Good, the Better, and the Best: Improving the Discriminability of Face Embeddings through Attribute-aware Learning
Mar 16, 2026Despite recent advances in face recognition, robust performance remains challenging under large variations in age, pose, and occlusion. A common strategy to address these issues is to guide representation learning with auxiliary supervision from facial attributes, encouraging the visual encoder to focus on identity-relevant regions. However, existing approaches typically rely on heterogeneous and fixed sets of attributes, implicitly assuming equal relevance across attributes. This assumption is suboptimal, as different attributes exhibit varying discriminative power for identity recognition, and some may even introduce harmful biases. In this paper, we propose an attribute-aware face recognition architecture that supervises the learning of facial embeddings using identity class labels, identity-relevant facial attributes, and non-identity-related attributes. Facial attributes are organized into interpretable groups, making it possible to decompose and analyze their individual contributions in a human-understandable manner. Experiments on standard face verification benchmarks demonstrate that joint learning of identity and facial attributes improves the discriminability of face embeddings with two major conclusions: (i) using identity-relevant subsets of facial attributes consistently outperforms supervision with a broader attribute set, and (ii) explicitly forcing embeddings to unlearn non-identity-related attributes yields further performance gains compared to leaving such attributes unsupervised. Additionally, our method serves as a diagnostic tool for assessing the trustworthiness of face recognition encoders by allowing for the measurement of accuracy gains with suppression of non-identity-relevant attributes, with such gains suggesting shortcut learning from redundant attributes associated with each identity.
Rectifying Geometry-Induced Similarity Distortions for Real-World Aerial-Ground Person Re-Identification
Jan 29, 2026Aerial-ground person re-identification (AG-ReID) is fundamentally challenged by extreme viewpoint and distance discrepancies between aerial and ground cameras, which induce severe geometric distortions and invalidate the assumption of a shared similarity space across views. Existing methods primarily rely on geometry-aware feature learning or appearance-conditioned prompting, while implicitly assuming that the geometry-invariant dot-product similarity used in attention mechanisms remains reliable under large viewpoint and scale variations. We argue that this assumption does not hold. Extreme camera geometry systematically distorts the query-key similarity space and degrades attention-based matching, even when feature representations are partially aligned. To address this issue, we introduce Geometry-Induced Query-Key Transformation (GIQT), a lightweight low-rank module that explicitly rectifies the similarity space by conditioning query-key interactions on camera geometry. Rather than modifying feature representations or the attention formulation itself, GIQT adapts the similarity computation to compensate for dominant geometry-induced anisotropic distortions. Building on this local similarity rectification, we further incorporate a geometry-conditioned prompt generation mechanism that provides global, view-adaptive representation priors derived directly from camera geometry. Experiments on four aerial-ground person re-identification benchmarks demonstrate that the proposed framework consistently improves robustness under extreme and previously unseen geometric conditions, while introducing minimal computational overhead compared to state-of-the-art methods.
FD-MAD: Frequency-Domain Residual Analysis for Face Morphing Attack Detection
Jan 28, 2026Face morphing attacks present a significant threat to face recognition systems used in electronic identity enrolment and border control, particularly in single-image morphing attack detection (S-MAD) scenarios where no trusted reference is available. In spite of the vast amount of research on this problem, morph detection systems struggle in cross-dataset scenarios. To address this problem, we introduce a region-aware frequency-based morph detection strategy that drastically improves over strong baseline methods in challenging cross-dataset and cross-morph settings using a lightweight approach. Having observed the separability of bona fide and morph samples in the frequency domain of different facial parts, our approach 1) introduces the concept of residual frequency domain, where the frequency of the signal is decoupled from the natural spectral decay to easily discriminate between morph and bona fide data; 2) additionally, we reason in a global and local manner by combining the evidence from different facial regions in a Markov Random Field, which infers a globally consistent decision. The proposed method, trained exclusively on the synthetic morphing attack detection development dataset (SMDD), is evaluated in challenging cross-dataset and cross-morph settings on FRLL-Morph and MAD22 sets. Our approach achieves an average equal error rate (EER) of 1.85\% on FRLL-Morph and ranks second on MAD22 with an average EER of 6.12\%, while also obtaining a good bona fide presentation classification error rate (BPCER) at a low attack presentation classification error rate (APCER) using only spectral features. These findings indicate that Fourier-domain residual modeling with structured regional fusion offers a competitive alternative to deep S-MAD architectures.
SortWaste: A Densely Annotated Dataset for Object Detection in Industrial Waste Sorting
Jan 07, 2026The increasing production of waste, driven by population growth, has created challenges in managing and recycling materials effectively. Manual waste sorting is a common practice; however, it remains inefficient for handling large-scale waste streams and presents health risks for workers. On the other hand, existing automated sorting approaches still struggle with the high variability, clutter, and visual complexity of real-world waste streams. The lack of real-world datasets for waste sorting is a major reason automated systems for this problem are underdeveloped. Accordingly, we introduce SortWaste, a densely annotated object detection dataset collected from a Material Recovery Facility. Additionally, we contribute to standardizing waste detection in sorting lines by proposing ClutterScore, an objective metric that gauges the scene's hardness level using a set of proxies that affect visual complexity (e.g., object count, class and size entropy, and spatial overlap). In addition to these contributions, we provide an extensive benchmark of state-of-the-art object detection models, detailing their results with respect to the hardness level assessed by the proposed metric. Despite achieving promising results (mAP of 59.7% in the plastic-only detection task), performance significantly decreases in highly cluttered scenes. This highlights the need for novel and more challenging datasets on the topic.
VReID-XFD: Video-based Person Re-identification at Extreme Far Distance Challenge Results
Jan 04, 2026Person re-identification (ReID) across aerial and ground views at extreme far distances introduces a distinct operating regime where severe resolution degradation, extreme viewpoint changes, unstable motion cues, and clothing variation jointly undermine the appearance-based assumptions of existing ReID systems. To study this regime, we introduce VReID-XFD, a video-based benchmark and community challenge for extreme far-distance (XFD) aerial-to-ground person re-identification. VReID-XFD is derived from the DetReIDX dataset and comprises 371 identities, 11,288 tracklets, and 11.75 million frames, captured across altitudes from 5.8 m to 120 m, viewing angles from oblique (30 degrees) to nadir (90 degrees), and horizontal distances up to 120 m. The benchmark supports aerial-to-aerial, aerial-to-ground, and ground-to-aerial evaluation under strict identity-disjoint splits, with rich physical metadata. The VReID-XFD-25 Challenge attracted 10 teams with hundreds of submissions. Systematic analysis reveals monotonic performance degradation with altitude and distance, a universal disadvantage of nadir views, and a trade-off between peak performance and robustness. Even the best-performing SAS-PReID method achieves only 43.93 percent mAP in the aerial-to-ground setting. The dataset, annotations, and official evaluation protocols are publicly available at https://www.it.ubi.pt/DetReIDX/ .
ZQBA: Zero Query Black-box Adversarial Attack
Oct 01, 2025Current black-box adversarial attacks either require multiple queries or diffusion models to produce adversarial samples that can impair the target model performance. However, these methods require training a surrogate loss or diffusion models to produce adversarial samples, which limits their applicability in real-world settings. Thus, we propose a Zero Query Black-box Adversarial (ZQBA) attack that exploits the representations of Deep Neural Networks (DNNs) to fool other networks. Instead of requiring thousands of queries to produce deceiving adversarial samples, we use the feature maps obtained from a DNN and add them to clean images to impair the classification of a target model. The results suggest that ZQBA can transfer the adversarial samples to different models and across various datasets, namely CIFAR and Tiny ImageNet. The experiments also show that ZQBA is more effective than state-of-the-art black-box attacks with a single query, while maintaining the imperceptibility of perturbations, evaluated both quantitatively (SSIM) and qualitatively, emphasizing the vulnerabilities of employing DNNs in real-world contexts. All the source code is available at https://github.com/Joana-Cabral/ZQBA.
Causality and "In-the-Wild" Video-Based Person Re-ID: A Survey
May 28, 2025
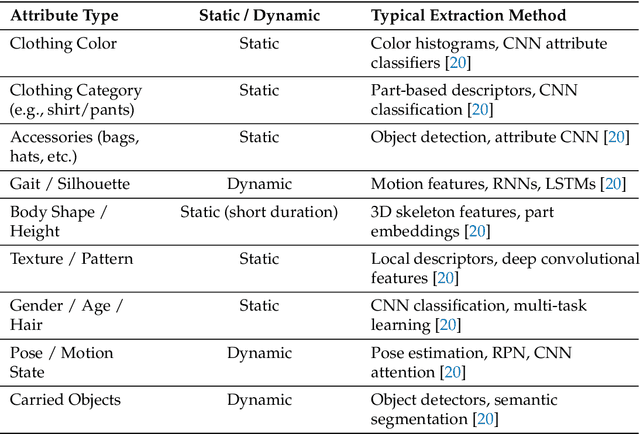
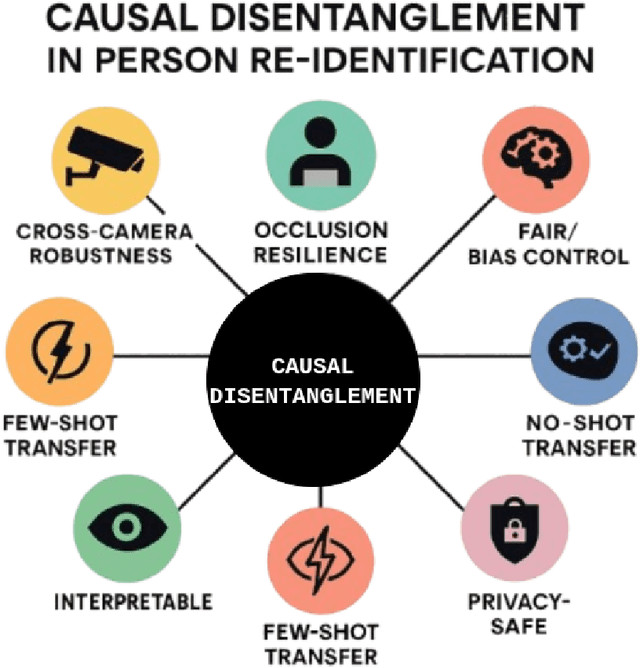
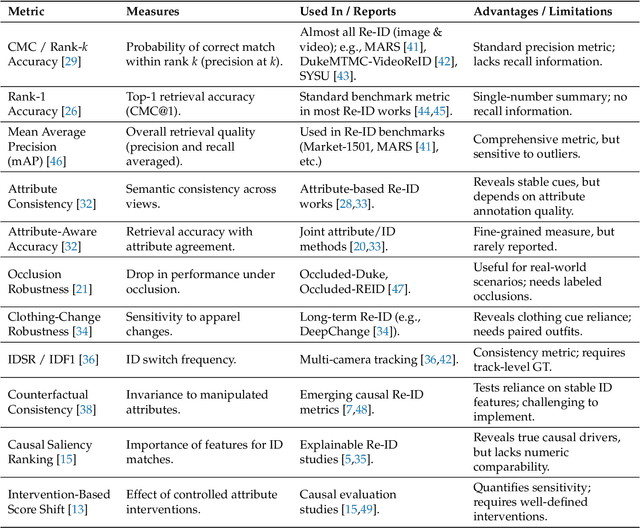
Video-based person re-identification (Re-ID) remains brittle in real-world deployments despite impressive benchmark performance. Most existing models rely on superficial correlations such as clothing, background, or lighting that fail to generalize across domains, viewpoints, and temporal variations. This survey examines the emerging role of causal reasoning as a principled alternative to traditional correlation-based approaches in video-based Re-ID. We provide a structured and critical analysis of methods that leverage structural causal models, interventions, and counterfactual reasoning to isolate identity-specific features from confounding factors. The survey is organized around a novel taxonomy of causal Re-ID methods that spans generative disentanglement, domain-invariant modeling, and causal transformers. We review current evaluation metrics and introduce causal-specific robustness measures. In addition, we assess practical challenges of scalability, fairness, interpretability, and privacy that must be addressed for real-world adoption. Finally, we identify open problems and outline future research directions that integrate causal modeling with efficient architectures and self-supervised learning. This survey aims to establish a coherent foundation for causal video-based person Re-ID and to catalyze the next phase of research in this rapidly evolving domain.
DetReIDX: A Stress-Test Dataset for Real-World UAV-Based Person Recognition
May 07, 2025Person reidentification (ReID) technology has been considered to perform relatively well under controlled, ground-level conditions, but it breaks down when deployed in challenging real-world settings. Evidently, this is due to extreme data variability factors such as resolution, viewpoint changes, scale variations, occlusions, and appearance shifts from clothing or session drifts. Moreover, the publicly available data sets do not realistically incorporate such kinds and magnitudes of variability, which limits the progress of this technology. This paper introduces DetReIDX, a large-scale aerial-ground person dataset, that was explicitly designed as a stress test to ReID under real-world conditions. DetReIDX is a multi-session set that includes over 13 million bounding boxes from 509 identities, collected in seven university campuses from three continents, with drone altitudes between 5.8 and 120 meters. More important, as a key novelty, DetReIDX subjects were recorded in (at least) two sessions on different days, with changes in clothing, daylight and location, making it suitable to actually evaluate long-term person ReID. Plus, data were annotated from 16 soft biometric attributes and multitask labels for detection, tracking, ReID, and action recognition. In order to provide empirical evidence of DetReIDX usefulness, we considered the specific tasks of human detection and ReID, where SOTA methods catastrophically degrade performance (up to 80% in detection accuracy and over 70% in Rank-1 ReID) when exposed to DetReIDXs conditions. The dataset, annotations, and official evaluation protocols are publicly available at https://www.it.ubi.pt/DetReIDX/