 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCausality and "In-the-Wild" Video-Based Person Re-ID: A Survey
May 28, 2025
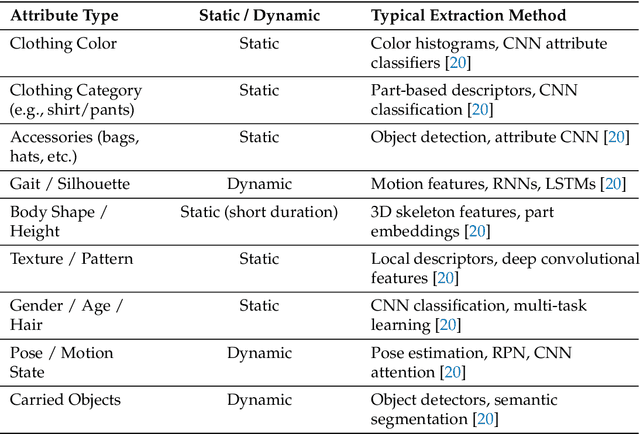
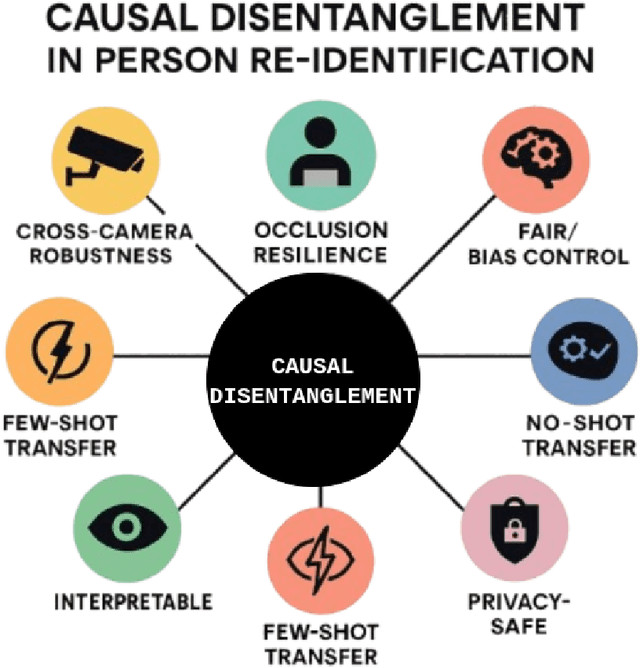
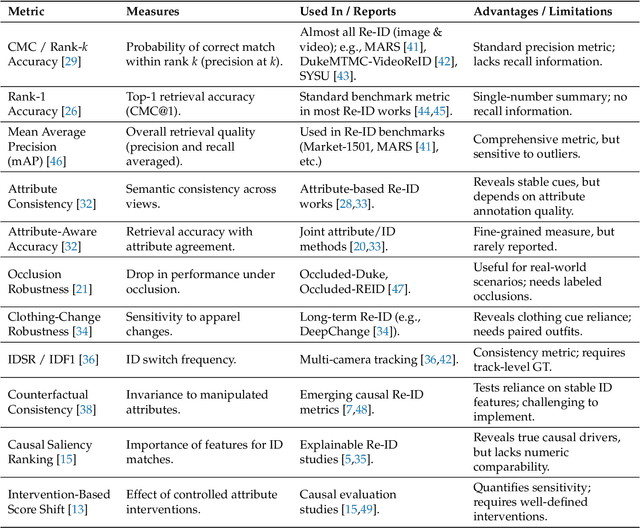
Video-based person re-identification (Re-ID) remains brittle in real-world deployments despite impressive benchmark performance. Most existing models rely on superficial correlations such as clothing, background, or lighting that fail to generalize across domains, viewpoints, and temporal variations. This survey examines the emerging role of causal reasoning as a principled alternative to traditional correlation-based approaches in video-based Re-ID. We provide a structured and critical analysis of methods that leverage structural causal models, interventions, and counterfactual reasoning to isolate identity-specific features from confounding factors. The survey is organized around a novel taxonomy of causal Re-ID methods that spans generative disentanglement, domain-invariant modeling, and causal transformers. We review current evaluation metrics and introduce causal-specific robustness measures. In addition, we assess practical challenges of scalability, fairness, interpretability, and privacy that must be addressed for real-world adoption. Finally, we identify open problems and outline future research directions that integrate causal modeling with efficient architectures and self-supervised learning. This survey aims to establish a coherent foundation for causal video-based person Re-ID and to catalyze the next phase of research in this rapidly evolving domain.
Human Re-ID Meets LVLMs: What can we expect?
Jan 30, 2025



Large vision-language models (LVLMs) have been regarded as a breakthrough advance in an astoundingly variety of tasks, from content generation to virtual assistants and multimodal search or retrieval. However, for many of these applications, the performance of these methods has been widely criticized, particularly when compared with state-of-the-art methods and technologies in each specific domain. In this work, we compare the performance of the leading large vision-language models in the human re-identification task, using as baseline the performance attained by state-of-the-art AI models specifically designed for this problem. We compare the results due to ChatGPT-4o, Gemini-2.0-Flash, Claude 3.5 Sonnet, and Qwen-VL-Max to a baseline ReID PersonViT model, using the well-known Market1501 dataset. Our evaluation pipeline includes the dataset curation, prompt engineering, and metric selection to assess the models' performance. Results are analyzed from many different perspectives: similarity scores, classification accuracy, and classification metrics, including precision, recall, F1 score, and area under curve (AUC). Our results confirm the strengths of LVLMs, but also their severe limitations that often lead to catastrophic answers and should be the scope of further research. As a concluding remark, we speculate about some further research that should fuse traditional and LVLMs to combine the strengths from both families of techniques and achieve solid improvements in performance.
A Laplacian-based Quantum Graph Neural Network for Semi-Supervised Learning
Aug 13, 2024



Laplacian learning method is a well-established technique in classical graph-based semi-supervised learning, but its potential in the quantum domain remains largely unexplored. This study investigates the performance of the Laplacian-based Quantum Semi-Supervised Learning (QSSL) method across four benchmark datasets -- Iris, Wine, Breast Cancer Wisconsin, and Heart Disease. Further analysis explores the impact of increasing Qubit counts, revealing that adding more Qubits to a quantum system doesn't always improve performance. The effectiveness of additional Qubits depends on the quantum algorithm and how well it matches the dataset. Additionally, we examine the effects of varying entangling layers on entanglement entropy and test accuracy. The performance of Laplacian learning is highly dependent on the number of entangling layers, with optimal configurations varying across different datasets. Typically, moderate levels of entanglement offer the best balance between model complexity and generalization capabilities. These observations highlight the crucial need for precise hyperparameter tuning tailored to each dataset to achieve optimal performance in Laplacian learning methods.