 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeHow to Squeeze An Explanation Out of Your Model
Paper and Code
Dec 06, 2024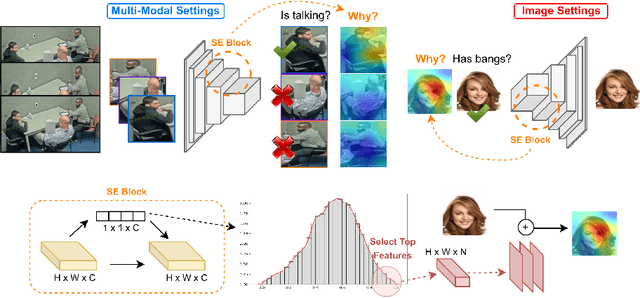
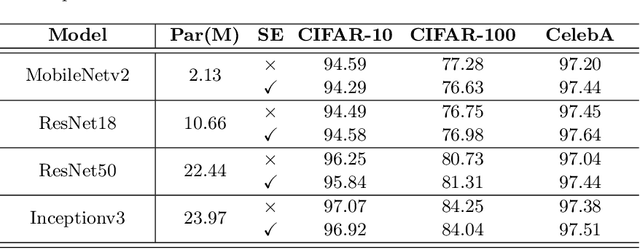

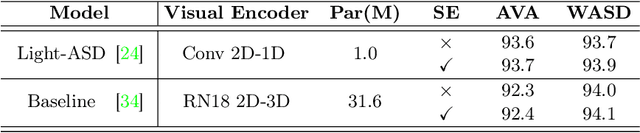
Deep learning models are widely used nowadays for their reliability in performing various tasks. However, they do not typically provide the reasoning behind their decision, which is a significant drawback, particularly for more sensitive areas such as biometrics, security and healthcare. The most commonly used approaches to provide interpretability create visual attention heatmaps of regions of interest on an image based on models gradient backpropagation. Although this is a viable approach, current methods are targeted toward image settings and default/standard deep learning models, meaning that they require significant adaptations to work on video/multi-modal settings and custom architectures. This paper proposes an approach for interpretability that is model-agnostic, based on a novel use of the Squeeze and Excitation (SE) block that creates visual attention heatmaps. By including an SE block prior to the classification layer of any model, we are able to retrieve the most influential features via SE vector manipulation, one of the key components of the SE block. Our results show that this new SE-based interpretability can be applied to various models in image and video/multi-modal settings, namely biometrics of facial features with CelebA and behavioral biometrics using Active Speaker Detection datasets. Furthermore, our proposal does not compromise model performance toward the original task, and has competitive results with current interpretability approaches in state-of-the-art object datasets, highlighting its robustness to perform in varying data aside from the biometric context.