 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeZQBA: Zero Query Black-box Adversarial Attack
Oct 01, 2025Current black-box adversarial attacks either require multiple queries or diffusion models to produce adversarial samples that can impair the target model performance. However, these methods require training a surrogate loss or diffusion models to produce adversarial samples, which limits their applicability in real-world settings. Thus, we propose a Zero Query Black-box Adversarial (ZQBA) attack that exploits the representations of Deep Neural Networks (DNNs) to fool other networks. Instead of requiring thousands of queries to produce deceiving adversarial samples, we use the feature maps obtained from a DNN and add them to clean images to impair the classification of a target model. The results suggest that ZQBA can transfer the adversarial samples to different models and across various datasets, namely CIFAR and Tiny ImageNet. The experiments also show that ZQBA is more effective than state-of-the-art black-box attacks with a single query, while maintaining the imperceptibility of perturbations, evaluated both quantitatively (SSIM) and qualitatively, emphasizing the vulnerabilities of employing DNNs in real-world contexts. All the source code is available at https://github.com/Joana-Cabral/ZQBA.
LISArD: Learning Image Similarity to Defend Against Gray-box Adversarial Attacks
Feb 27, 2025State-of-the-art defense mechanisms are typically evaluated in the context of white-box attacks, which is not realistic, as it assumes the attacker can access the gradients of the target network. To protect against this scenario, Adversarial Training (AT) and Adversarial Distillation (AD) include adversarial examples during the training phase, and Adversarial Purification uses a generative model to reconstruct all the images given to the classifier. This paper considers an even more realistic evaluation scenario: gray-box attacks, which assume that the attacker knows the architecture and the dataset used to train the target network, but cannot access its gradients. We provide empirical evidence that models are vulnerable to gray-box attacks and propose LISArD, a defense mechanism that does not increase computational and temporal costs but provides robustness against gray-box and white-box attacks without including AT. Our method approximates a cross-correlation matrix, created with the embeddings of perturbed and clean images, to a diagonal matrix while simultaneously conducting classification learning. Our results show that LISArD can effectively protect against gray-box attacks, can be used in multiple architectures, and carries over its resilience to the white-box scenario. Also, state-of-the-art AD models underperform greatly when removing AT and/or moving to gray-box settings, highlighting the lack of robustness from existing approaches to perform in various conditions (aside from white-box settings). All the source code is available at https://github.com/Joana-Cabral/LISArD.
How to Squeeze An Explanation Out of Your Model
Dec 06, 2024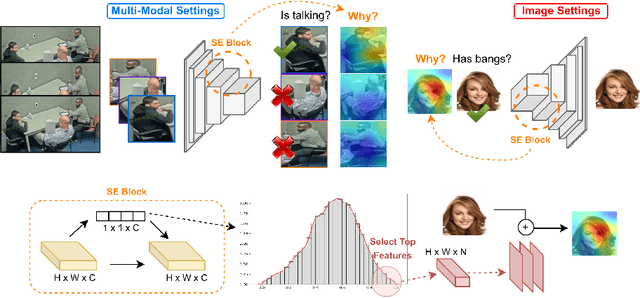
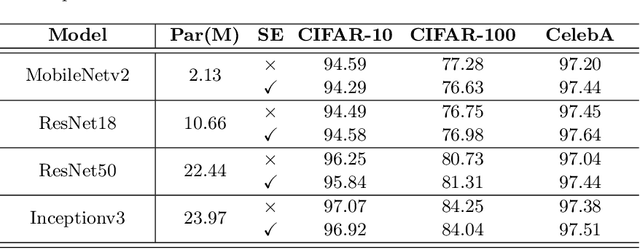

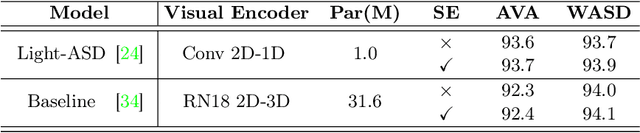
Deep learning models are widely used nowadays for their reliability in performing various tasks. However, they do not typically provide the reasoning behind their decision, which is a significant drawback, particularly for more sensitive areas such as biometrics, security and healthcare. The most commonly used approaches to provide interpretability create visual attention heatmaps of regions of interest on an image based on models gradient backpropagation. Although this is a viable approach, current methods are targeted toward image settings and default/standard deep learning models, meaning that they require significant adaptations to work on video/multi-modal settings and custom architectures. This paper proposes an approach for interpretability that is model-agnostic, based on a novel use of the Squeeze and Excitation (SE) block that creates visual attention heatmaps. By including an SE block prior to the classification layer of any model, we are able to retrieve the most influential features via SE vector manipulation, one of the key components of the SE block. Our results show that this new SE-based interpretability can be applied to various models in image and video/multi-modal settings, namely biometrics of facial features with CelebA and behavioral biometrics using Active Speaker Detection datasets. Furthermore, our proposal does not compromise model performance toward the original task, and has competitive results with current interpretability approaches in state-of-the-art object datasets, highlighting its robustness to perform in varying data aside from the biometric context.
BIAS: A Body-based Interpretable Active Speaker Approach
Dec 06, 2024



State-of-the-art Active Speaker Detection (ASD) approaches heavily rely on audio and facial features to perform, which is not a sustainable approach in wild scenarios. Although these methods achieve good results in the standard AVA-ActiveSpeaker set, a recent wilder ASD dataset (WASD) showed the limitations of such models and raised the need for new approaches. As such, we propose BIAS, a model that, for the first time, combines audio, face, and body information, to accurately predict active speakers in varying/challenging conditions. Additionally, we design BIAS to provide interpretability by proposing a novel use for Squeeze-and-Excitation blocks, namely in attention heatmaps creation and feature importance assessment. For a full interpretability setup, we annotate an ASD-related actions dataset (ASD-Text) to finetune a ViT-GPT2 for text scene description to complement BIAS interpretability. The results show that BIAS is state-of-the-art in challenging conditions where body-based features are of utmost importance (Columbia, open-settings, and WASD), and yields competitive results in AVA-ActiveSpeaker, where face is more influential than body for ASD. BIAS interpretability also shows the features/aspects more relevant towards ASD prediction in varying settings, making it a strong baseline for further developments in interpretable ASD models, and is available at https://github.com/Tiago-Roxo/BIAS.
How Deep Learning Sees the World: A Survey on Adversarial Attacks & Defenses
May 18, 2023



Deep Learning is currently used to perform multiple tasks, such as object recognition, face recognition, and natural language processing. However, Deep Neural Networks (DNNs) are vulnerable to perturbations that alter the network prediction (adversarial examples), raising concerns regarding its usage in critical areas, such as self-driving vehicles, malware detection, and healthcare. This paper compiles the most recent adversarial attacks, grouped by the attacker capacity, and modern defenses clustered by protection strategies. We also present the new advances regarding Vision Transformers, summarize the datasets and metrics used in the context of adversarial settings, and compare the state-of-the-art results under different attacks, finishing with the identification of open issues.
WASD: A Wilder Active Speaker Detection Dataset
Mar 09, 2023



Current Active Speaker Detection (ASD) models achieve great results on AVA-ActiveSpeaker (AVA), using only sound and facial features. Although this approach is applicable in movie setups (AVA), it is not suited for less constrained conditions. To demonstrate this limitation, we propose a Wilder Active Speaker Detection (WASD) dataset, with increased difficulty by targeting the two key components of current ASD: audio and face. Grouped into 5 categories, ranging from optimal conditions to surveillance settings, WASD contains incremental challenges for ASD with tactical impairment of audio and face data. We select state-of-the-art models and assess their performance in two groups of WASD: Easy (cooperative settings) and Hard (audio and/or face are specifically degraded). The results show that: 1) AVA trained models maintain a state-of-the-art performance in WASD Easy group, while underperforming in the Hard one, showing the 2) similarity between AVA and Easy data; and 3) training in WASD does not improve models performance to AVA levels, particularly for audio impairment and surveillance settings. This shows that AVA does not prepare models for wild ASD and current approaches are subpar to deal with such conditions. The proposed dataset also contains body data annotations to provide a new source for ASD, and is available at https://github.com/Tiago-Roxo/WASD.