 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTokenization of Gaze Data
Mar 28, 2025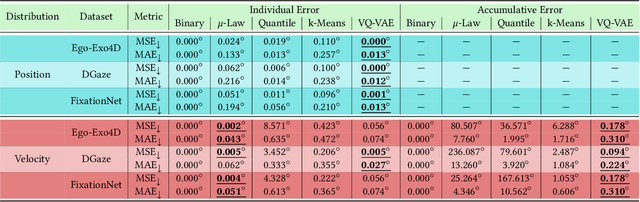
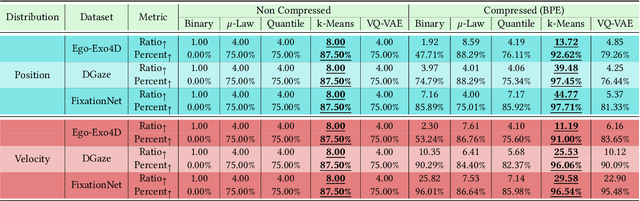
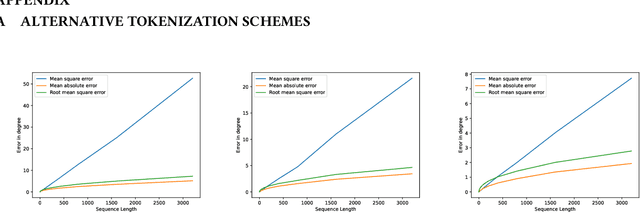
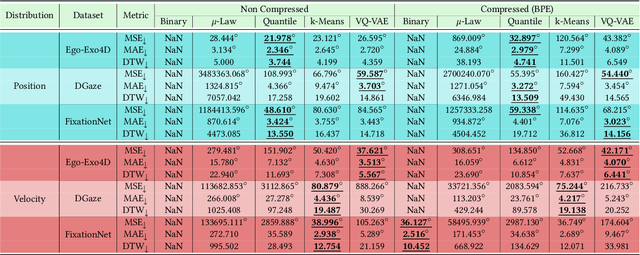
A considerable part of the performance of today's large language models (LLM's) and multimodal large language models (MLLM's) depends on their tokenization strategies. While tokenizers are extensively researched for textual and visual input, there is no research on tokenization strategies for gaze data due to its nature. However, a corresponding tokenization strategy would allow using the vision capabilities of pre-trained MLLM's for gaze data, for example, through fine-tuning. In this paper, we aim to close this research gap by analyzing five different tokenizers for gaze data on three different datasets for the forecasting and generation of gaze data through LLMs (cf.~\cref{fig:teaser}). We evaluate the tokenizers regarding their reconstruction and compression abilities. Further, we train an LLM for each tokenization strategy, measuring its generative and predictive performance. Overall, we found that a quantile tokenizer outperforms all others in predicting the gaze positions and k-means is best when predicting gaze velocities.
A Hands-free Spatial Selection and Interaction Technique using Gaze and Blink Input with Blink Prediction for Extended Reality
Jan 20, 2025



Gaze-based interaction techniques have created significant interest in the field of spatial interaction. Many of these methods require additional input modalities, such as hand gestures (e.g., gaze coupled with pinch). Those can be uncomfortable and difficult to perform in public or limited spaces, and pose challenges for users who are unable to execute pinch gestures. To address these aspects, we propose a novel, hands-free Gaze+Blink interaction technique that leverages the user's gaze and intentional eye blinks. This technique enables users to perform selections by executing intentional blinks. It facilitates continuous interactions, such as scrolling or drag-and-drop, through eye blinks coupled with head movements. So far, this concept has not been explored for hands-free spatial interaction techniques. We evaluated the performance and user experience (UX) of our Gaze+Blink method with two user studies and compared it with Gaze+Pinch in a realistic user interface setup featuring common menu interaction tasks. Study 1 demonstrated that while Gaze+Blink achieved comparable selection speeds, it was prone to accidental selections resulting from unintentional blinks. In Study 2 we explored an enhanced technique employing a deep learning algorithms for filtering out unintentional blinks.
A Toolkit for Virtual Reality Data Collection
Dec 23, 2024Due to the still relatively low number of users, acquiring large-scale and multidimensional virtual reality datasets remains a significant challenge. Consequently, VR datasets comparable in size to state-of-the-art collections in natural language processing or computer vision are rare or absent. However, the availability of such datasets could unlock groundbreaking advancements in deep-learning, psychological modeling, and data analysis in the context of VR. In this paper, we present a versatile data collection toolkit designed to facilitate the capturing of extensive VR datasets. Our toolkit seamlessly integrates with any device, either directly via OpenXR or through the use of a virtual device. Additionally, we introduce a robust data collection pipeline that emphasizes ethical practices (e.g., ensuring data protection and regulation) and ensures a standardized, reproducible methodology.
SOS: Segment Object System for Open-World Instance Segmentation With Object Priors
Sep 22, 2024

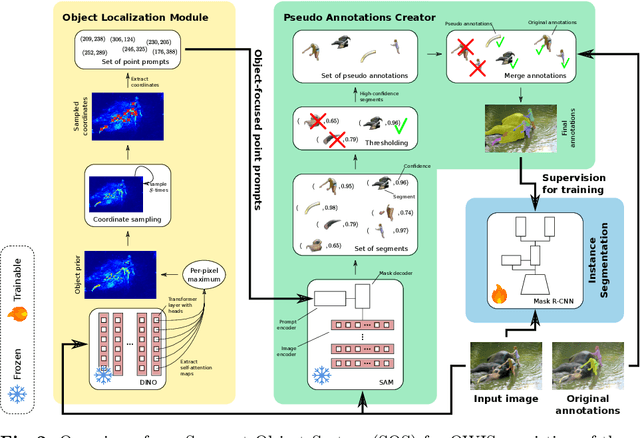

We propose an approach for Open-World Instance Segmentation (OWIS), a task that aims to segment arbitrary unknown objects in images by generalizing from a limited set of annotated object classes during training. Our Segment Object System (SOS) explicitly addresses the generalization ability and the low precision of state-of-the-art systems, which often generate background detections. To this end, we generate high-quality pseudo annotations based on the foundation model SAM. We thoroughly study various object priors to generate prompts for SAM, explicitly focusing the foundation model on objects. The strongest object priors were obtained by self-attention maps from self-supervised Vision Transformers, which we utilize for prompting SAM. Finally, the post-processed segments from SAM are used as pseudo annotations to train a standard instance segmentation system. Our approach shows strong generalization capabilities on COCO, LVIS, and ADE20k datasets and improves on the precision by up to 81.6% compared to the state-of-the-art. Source code is available at: https://github.com/chwilms/SOS
Select High-Level Features: Efficient Experts from a Hierarchical Classification Network
Mar 08, 2024

This study introduces a novel expert generation method that dynamically reduces task and computational complexity without compromising predictive performance. It is based on a new hierarchical classification network topology that combines sequential processing of generic low-level features with parallelism and nesting of high-level features. This structure allows for the innovative extraction technique: the ability to select only high-level features of task-relevant categories. In certain cases, it is possible to skip almost all unneeded high-level features, which can significantly reduce the inference cost and is highly beneficial in resource-constrained conditions. We believe this method paves the way for future network designs that are lightweight and adaptable, making them suitable for a wide range of applications, from compact edge devices to large-scale clouds. In terms of dynamic inference our methodology can achieve an exclusion of up to 88.7\,\% of parameters and 73.4\,\% fewer giga-multiply accumulate (GMAC) operations, analysis against comparative baselines showing an average reduction of 47.6\,\% in parameters and 5.8\,\% in GMACs across the cases we evaluated.
High-Level Features Parallelization for Inference Cost Reduction Through Selective Attention
Aug 09, 2023



In this work, we parallelize high-level features in deep networks to selectively skip or select class-specific features to reduce inference costs. This challenges most deep learning methods due to their limited ability to efficiently and effectively focus on selected class-specific features without retraining. We propose a serial-parallel hybrid architecture with serial generic low-level features and parallel high-level features. This accounts for the fact that many high-level features are class-specific rather than generic, and has connections to recent neuroscientific findings that observe spatially and contextually separated neural activations in the human brain. Our approach provides the unique functionality of cutouts: selecting parts of the network to focus on only relevant subsets of classes without requiring retraining. High performance is maintained, but the cost of inference can be significantly reduced. In some of our examples, up to $75\,\%$ of parameters are skipped and $35\,\%$ fewer GMACs (Giga multiply-accumulate) operations are used as the approach adapts to a change in task complexity. This is important for mobile, industrial, and robotic applications where reducing the number of parameters, the computational complexity, and thus the power consumption can be paramount. Another unique functionality is that it allows processing to be directly influenced by enhancing or inhibiting high-level class-specific features, similar to the mechanism of selective attention in the human brain. This can be relevant for cross-modal applications, the use of semantic prior knowledge, and/or context-aware processing.
Immersive Neural Graphics Primitives
Nov 24, 2022



Neural radiance field (NeRF), in particular its extension by instant neural graphics primitives, is a novel rendering method for view synthesis that uses real-world images to build photo-realistic immersive virtual scenes. Despite its potential, research on the combination of NeRF and virtual reality (VR) remains sparse. Currently, there is no integration into typical VR systems available, and the performance and suitability of NeRF implementations for VR have not been evaluated, for instance, for different scene complexities or screen resolutions. In this paper, we present and evaluate a NeRF-based framework that is capable of rendering scenes in immersive VR allowing users to freely move their heads to explore complex real-world scenes. We evaluate our framework by benchmarking three different NeRF scenes concerning their rendering performance at different scene complexities and resolutions. Utilizing super-resolution, our approach can yield a frame rate of 30 frames per second with a resolution of 1280x720 pixels per eye. We discuss potential applications of our framework and provide an open source implementation online.