 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTokenization of Gaze Data
Mar 28, 2025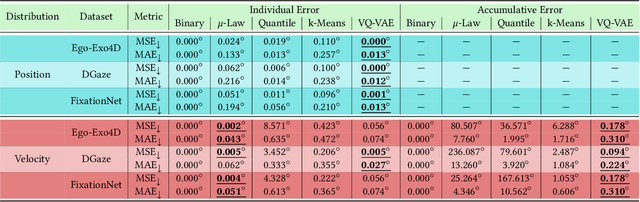
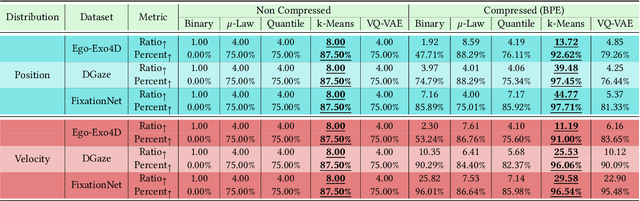
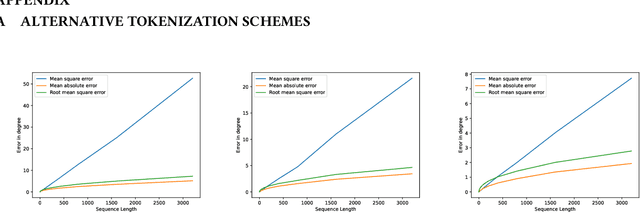
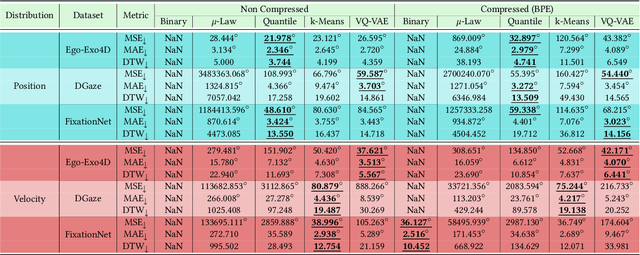
A considerable part of the performance of today's large language models (LLM's) and multimodal large language models (MLLM's) depends on their tokenization strategies. While tokenizers are extensively researched for textual and visual input, there is no research on tokenization strategies for gaze data due to its nature. However, a corresponding tokenization strategy would allow using the vision capabilities of pre-trained MLLM's for gaze data, for example, through fine-tuning. In this paper, we aim to close this research gap by analyzing five different tokenizers for gaze data on three different datasets for the forecasting and generation of gaze data through LLMs (cf.~\cref{fig:teaser}). We evaluate the tokenizers regarding their reconstruction and compression abilities. Further, we train an LLM for each tokenization strategy, measuring its generative and predictive performance. Overall, we found that a quantile tokenizer outperforms all others in predicting the gaze positions and k-means is best when predicting gaze velocities.
A Hands-free Spatial Selection and Interaction Technique using Gaze and Blink Input with Blink Prediction for Extended Reality
Jan 20, 2025



Gaze-based interaction techniques have created significant interest in the field of spatial interaction. Many of these methods require additional input modalities, such as hand gestures (e.g., gaze coupled with pinch). Those can be uncomfortable and difficult to perform in public or limited spaces, and pose challenges for users who are unable to execute pinch gestures. To address these aspects, we propose a novel, hands-free Gaze+Blink interaction technique that leverages the user's gaze and intentional eye blinks. This technique enables users to perform selections by executing intentional blinks. It facilitates continuous interactions, such as scrolling or drag-and-drop, through eye blinks coupled with head movements. So far, this concept has not been explored for hands-free spatial interaction techniques. We evaluated the performance and user experience (UX) of our Gaze+Blink method with two user studies and compared it with Gaze+Pinch in a realistic user interface setup featuring common menu interaction tasks. Study 1 demonstrated that while Gaze+Blink achieved comparable selection speeds, it was prone to accidental selections resulting from unintentional blinks. In Study 2 we explored an enhanced technique employing a deep learning algorithms for filtering out unintentional blinks.
Reality Fusion: Robust Real-time Immersive Mobile Robot Teleoperation with Volumetric Visual Data Fusion
Aug 02, 2024



We introduce Reality Fusion, a novel robot teleoperation system that localizes, streams, projects, and merges a typical onboard depth sensor with a photorealistic, high resolution, high framerate, and wide field of view (FoV) rendering of the complex remote environment represented as 3D Gaussian splats (3DGS). Our framework enables robust egocentric and exocentric robot teleoperation in immersive VR, with the 3DGS effectively extending spatial information of a depth sensor with limited FoV and balancing the trade-off between data streaming costs and data visual quality. We evaluated our framework through a user study with 24 participants, which revealed that Reality Fusion leads to significantly better user performance, situation awareness, and user preferences. To support further research and development, we provide an open-source implementation with an easy-to-replicate custom-made telepresence robot, a high-performance virtual reality 3DGS renderer, and an immersive robot control package. (Source code: https://github.com/uhhhci/RealityFusion)
Moving Avatars and Agents in Social Extended Reality Environments
Jun 26, 2023



Natural interaction between multiple users within a shared virtual environment (VE) relies on each other's awareness of the current position of the interaction partners. This, however, cannot be warranted when users employ noncontinuous locomotion techniques, such as teleportation, which may cause confusion among bystanders. In this paper, we pursue two approaches to create a pleasant experience for both the moving user and the bystanders observing that movement. First, we will introduce a Smart Avatar system that delivers continuous full-body human representations for noncontinuous locomotion in shared virtual reality (VR) spaces. Smart Avatars imitate their assigned user's real-world movements when close-by and autonomously navigate to their user when the distance between them exceeds a certain threshold, i.e., after the user teleports. As part of the Smart Avatar system, we implemented four avatar transition techniques and compared them to conventional avatar locomotion in a user study, revealing significant positive effects on the observer's spatial awareness, as well as pragmatic and hedonic quality scores. Second, we introduce the concept of Stuttered Locomotion, which can be applied to any continuous locomotion method. By converting a continuous movement into short-interval teleport steps, we provide the merits of non-continuous locomotion for the moving user while observers can easily keep track of their path. Thus, while the experience for observers is similarly positive as with continuous motion, a user study confirmed that Stuttered Locomotion can significantly reduce the occurrence of cybersickness symptoms for the moving user, making it an attractive choice for shared VEs. We will discuss the potential of Smart Avatars and Stuttered Locomotion for shared VR experiences, both when applied individually and in combination.
Immersive Neural Graphics Primitives
Nov 24, 2022



Neural radiance field (NeRF), in particular its extension by instant neural graphics primitives, is a novel rendering method for view synthesis that uses real-world images to build photo-realistic immersive virtual scenes. Despite its potential, research on the combination of NeRF and virtual reality (VR) remains sparse. Currently, there is no integration into typical VR systems available, and the performance and suitability of NeRF implementations for VR have not been evaluated, for instance, for different scene complexities or screen resolutions. In this paper, we present and evaluate a NeRF-based framework that is capable of rendering scenes in immersive VR allowing users to freely move their heads to explore complex real-world scenes. We evaluate our framework by benchmarking three different NeRF scenes concerning their rendering performance at different scene complexities and resolutions. Utilizing super-resolution, our approach can yield a frame rate of 30 frames per second with a resolution of 1280x720 pixels per eye. We discuss potential applications of our framework and provide an open source implementation online.