 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeWalk the Lines 2: Contour Tracking for Detailed Segmentation
Nov 07, 2025This paper presents Walk the Lines 2 (WtL2), a unique contour tracking algorithm specifically adapted for detailed segmentation of infrared (IR) ships and various objects in RGB.1 This extends the original Walk the Lines (WtL) [12], which focused solely on detailed ship segmentation in color. These innovative WtLs can replace the standard non-maximum suppression (NMS) by using contour tracking to refine the object contour until a 1-pixel-wide closed shape can be binarized, forming a segmentable area in foreground-background scenarios. WtL2 broadens the application range of WtL beyond its original scope, adapting to IR and expanding to diverse objects within the RGB context. To achieve IR segmentation, we adapt its input, the object contour detector, to IR ships. In addition, the algorithm is enhanced to process a wide range of RGB objects, outperforming the latest generation of contour-based methods when achieving a closed object contour, offering high peak Intersection over Union (IoU) with impressive details. This positions WtL2 as a compelling method for specialized applications that require detailed segmentation or high-quality samples, potentially accelerating progress in several niche areas of image segmentation.
Fusing Monocular RGB Images with AIS Data to Create a 6D Pose Estimation Dataset for Marine Vessels
Aug 20, 2025The paper presents a novel technique for creating a 6D pose estimation dataset for marine vessels by fusing monocular RGB images with Automatic Identification System (AIS) data. The proposed technique addresses the limitations of relying purely on AIS for location information, caused by issues like equipment reliability, data manipulation, and transmission delays. By combining vessel detections from monocular RGB images, obtained using an object detection network (YOLOX-X), with AIS messages, the technique generates 3D bounding boxes that represent the vessels' 6D poses, i.e. spatial and rotational dimensions. The paper evaluates different object detection models to locate vessels in image space. We also compare two transformation methods (homography and Perspective-n-Point) for aligning AIS data with image coordinates. The results of our work demonstrate that the Perspective-n-Point (PnP) method achieves a significantly lower projection error compared to homography-based approaches used before, and the YOLOX-X model achieves a mean Average Precision (mAP) of 0.80 at an Intersection over Union (IoU) threshold of 0.5 for relevant vessel classes. We show indication that our approach allows the creation of a 6D pose estimation dataset without needing manual annotation. Additionally, we introduce the Boats on Nordelbe Kehrwieder (BONK-pose), a publicly available dataset comprising 3753 images with 3D bounding box annotations for pose estimation, created by our data fusion approach. This dataset can be used for training and evaluating 6D pose estimation networks. In addition we introduce a set of 1000 images with 2D bounding box annotations for ship detection from the same scene.
SOS: Segment Object System for Open-World Instance Segmentation With Object Priors
Sep 22, 2024

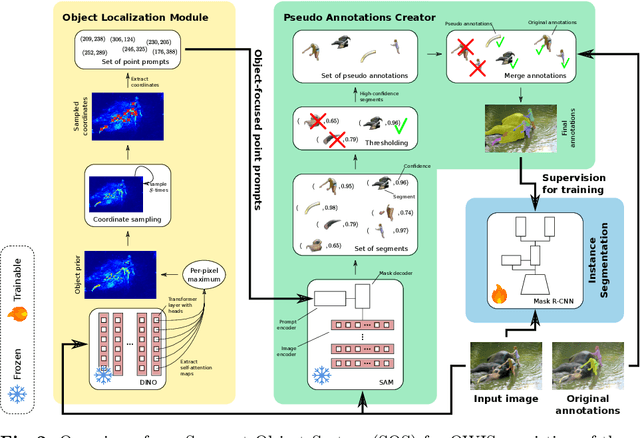

We propose an approach for Open-World Instance Segmentation (OWIS), a task that aims to segment arbitrary unknown objects in images by generalizing from a limited set of annotated object classes during training. Our Segment Object System (SOS) explicitly addresses the generalization ability and the low precision of state-of-the-art systems, which often generate background detections. To this end, we generate high-quality pseudo annotations based on the foundation model SAM. We thoroughly study various object priors to generate prompts for SAM, explicitly focusing the foundation model on objects. The strongest object priors were obtained by self-attention maps from self-supervised Vision Transformers, which we utilize for prompting SAM. Finally, the post-processed segments from SAM are used as pseudo annotations to train a standard instance segmentation system. Our approach shows strong generalization capabilities on COCO, LVIS, and ADE20k datasets and improves on the precision by up to 81.6% compared to the state-of-the-art. Source code is available at: https://github.com/chwilms/SOS
AnomalousPatchCore: Exploring the Use of Anomalous Samples in Industrial Anomaly Detection
Aug 27, 2024
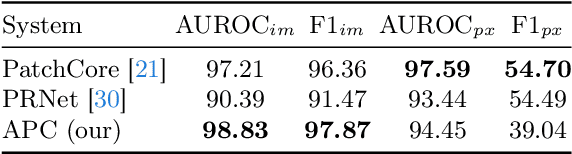

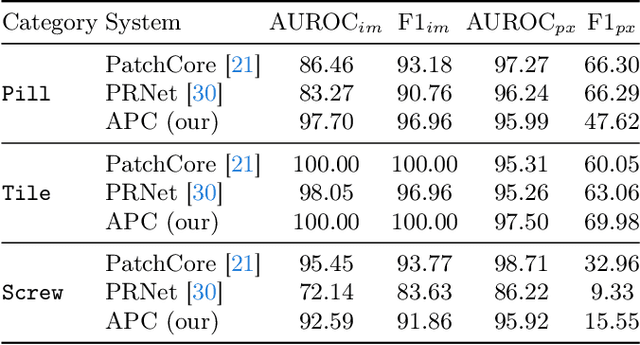
Visual inspection, or industrial anomaly detection, is one of the most common quality control types in manufacturing. The task is to identify the presence of an anomaly given an image, e.g., a missing component on an image of a circuit board, for subsequent manual inspection. While industrial anomaly detection has seen a surge in recent years, most anomaly detection methods still utilize knowledge only from normal samples, failing to leverage the information from the frequently available anomalous samples. Additionally, they heavily rely on very general feature extractors pre-trained on common image classification datasets. In this paper, we address these shortcomings and propose the new anomaly detection system AnomalousPatchCore~(APC) based on a feature extractor fine-tuned with normal and anomalous in-domain samples and a subsequent memory bank for identifying unusual features. To fine-tune the feature extractor in APC, we propose three auxiliary tasks that address the different aspects of anomaly detection~(classification vs. localization) and mitigate the effect of the imbalance between normal and anomalous samples. Our extensive evaluation on the MVTec dataset shows that APC outperforms state-of-the-art systems in detecting anomalies, which is especially important in industrial anomaly detection given the subsequent manual inspection. In detailed ablation studies, we further investigate the properties of our APC.
Select High-Level Features: Efficient Experts from a Hierarchical Classification Network
Mar 08, 2024

This study introduces a novel expert generation method that dynamically reduces task and computational complexity without compromising predictive performance. It is based on a new hierarchical classification network topology that combines sequential processing of generic low-level features with parallelism and nesting of high-level features. This structure allows for the innovative extraction technique: the ability to select only high-level features of task-relevant categories. In certain cases, it is possible to skip almost all unneeded high-level features, which can significantly reduce the inference cost and is highly beneficial in resource-constrained conditions. We believe this method paves the way for future network designs that are lightweight and adaptable, making them suitable for a wide range of applications, from compact edge devices to large-scale clouds. In terms of dynamic inference our methodology can achieve an exclusion of up to 88.7\,\% of parameters and 73.4\,\% fewer giga-multiply accumulate (GMAC) operations, analysis against comparative baselines showing an average reduction of 47.6\,\% in parameters and 5.8\,\% in GMACs across the cases we evaluated.
S$^3$AD: Semi-supervised Small Apple Detection in Orchard Environments
Nov 08, 2023



Crop detection is integral for precision agriculture applications such as automated yield estimation or fruit picking. However, crop detection, e.g., apple detection in orchard environments remains challenging due to a lack of large-scale datasets and the small relative size of the crops in the image. In this work, we address these challenges by reformulating the apple detection task in a semi-supervised manner. To this end, we provide the large, high-resolution dataset MAD comprising 105 labeled images with 14,667 annotated apple instances and 4,440 unlabeled images. Utilizing this dataset, we also propose a novel Semi-Supervised Small Apple Detection system S$^3$AD based on contextual attention and selective tiling to improve the challenging detection of small apples, while limiting the computational overhead. We conduct an extensive evaluation on MAD and the MSU dataset, showing that S$^3$AD substantially outperforms strong fully-supervised baselines, including several small object detection systems, by up to $14.9\%$. Additionally, we exploit the detailed annotations of our dataset w.r.t. apple properties to analyze the influence of relative size or level of occlusion on the results of various systems, quantifying current challenges.
High-Level Features Parallelization for Inference Cost Reduction Through Selective Attention
Aug 09, 2023



In this work, we parallelize high-level features in deep networks to selectively skip or select class-specific features to reduce inference costs. This challenges most deep learning methods due to their limited ability to efficiently and effectively focus on selected class-specific features without retraining. We propose a serial-parallel hybrid architecture with serial generic low-level features and parallel high-level features. This accounts for the fact that many high-level features are class-specific rather than generic, and has connections to recent neuroscientific findings that observe spatially and contextually separated neural activations in the human brain. Our approach provides the unique functionality of cutouts: selecting parts of the network to focus on only relevant subsets of classes without requiring retraining. High performance is maintained, but the cost of inference can be significantly reduced. In some of our examples, up to $75\,\%$ of parameters are skipped and $35\,\%$ fewer GMACs (Giga multiply-accumulate) operations are used as the approach adapts to a change in task complexity. This is important for mobile, industrial, and robotic applications where reducing the number of parameters, the computational complexity, and thus the power consumption can be paramount. Another unique functionality is that it allows processing to be directly influenced by enhancing or inhibiting high-level class-specific features, similar to the mechanism of selective attention in the human brain. This can be relevant for cross-modal applications, the use of semantic prior knowledge, and/or context-aware processing.
Small, but important: Traffic light proposals for detecting small traffic lights and beyond
Jul 27, 2023
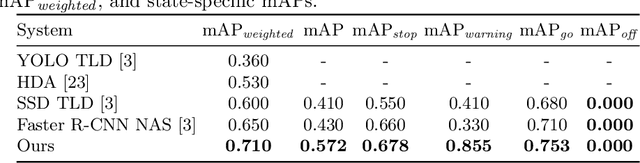


Traffic light detection is a challenging problem in the context of self-driving cars and driver assistance systems. While most existing systems produce good results on large traffic lights, detecting small and tiny ones is often overlooked. A key problem here is the inherent downsampling in CNNs, leading to low-resolution features for detection. To mitigate this problem, we propose a new traffic light detection system, comprising a novel traffic light proposal generator that utilizes findings from general object proposal generation, fine-grained multi-scale features, and attention for efficient processing. Moreover, we design a new detection head for classifying and refining our proposals. We evaluate our system on three challenging, publicly available datasets and compare it against six methods. The results show substantial improvements of at least $12.6\%$ on small and tiny traffic lights, as well as strong results across all sizes of traffic lights.
Audio-Visual Speech Enhancement with Score-Based Generative Models
Jun 02, 2023

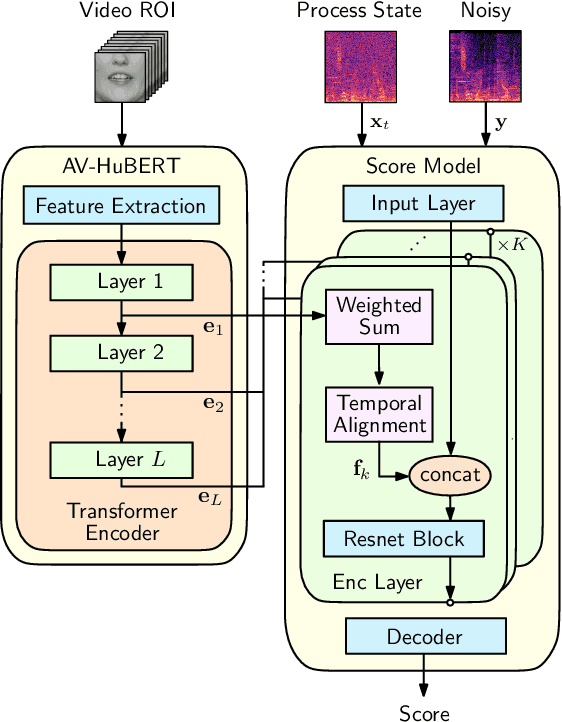

This paper introduces an audio-visual speech enhancement system that leverages score-based generative models, also known as diffusion models, conditioned on visual information. In particular, we exploit audio-visual embeddings obtained from a self-super\-vised learning model that has been fine-tuned on lipreading. The layer-wise features of its transformer-based encoder are aggregated, time-aligned, and incorporated into the noise conditional score network. Experimental evaluations show that the proposed audio-visual speech enhancement system yields improved speech quality and reduces generative artifacts such as phonetic confusions with respect to the audio-only equivalent. The latter is supported by the word error rate of a downstream automatic speech recognition model, which decreases noticeably, especially at low input signal-to-noise ratios.
Teacher Network Calibration Improves Cross-Quality Knowledge Distillation
Apr 15, 2023

We investigate cross-quality knowledge distillation (CQKD), a knowledge distillation method where knowledge from a teacher network trained with full-resolution images is transferred to a student network that takes as input low-resolution images. As image size is a deciding factor for the computational load of computer vision applications, CQKD notably reduces the requirements by only using the student network at inference time. Our experimental results show that CQKD outperforms supervised learning in large-scale image classification problems. We also highlight the importance of calibrating neural networks: we show that with higher temperature smoothing of the teacher's output distribution, the student distribution exhibits a higher entropy, which leads to both, a lower calibration error and a higher network accuracy.