 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePredictive-Generative Drift Decomposition for Speech Enhancement and Separation
May 07, 2026We propose a plug-and-play framework for speech enhancement and separation that augments predictive methods with a generative speech prior. Our approach, termed Stochastic Interpolant Prior for Speech (SIPS), builds on stochastic interpolants and leverages their flexibility to bridge predictive and generative modeling. Specifically, we decompose the interpolation dynamics into a task-specific drift and a stochastic denoising component, allowing a predictive estimate to be integrated directly into the generative sampling process. This results in a mathematically grounded framework for combining strong pretrained predictors with the expressive power of generative models. To this end, we train a score model using only clean speech, yielding a degradation-agnostic prior that can be reused across tasks. During inference, the predictor provides a deterministic drift that steers the sampling process toward a task-consistent estimate, while the score model preserves perceptual naturalness. Unlike prior hybrid approaches, which typically rely on architecture-specific conditioning and are tied to particular predictors or degradation settings, SIPS provides a unified framework that generalizes across predictors and additive degradation tasks. We demonstrate its effectiveness for both speech enhancement and speech separation using recent predictors such as SEMamba and FlexIO. The proposed method consistently improves perceptual quality, achieving gains up +1.0 NISQA for speech separation.
Pushing the Frontier of Audiovisual Perception with Large-Scale Multimodal Correspondence Learning
Dec 22, 2025We introduce Perception Encoder Audiovisual, PE-AV, a new family of encoders for audio and video understanding trained with scaled contrastive learning. Built on PE, PE-AV makes several key contributions to extend representations to audio, and natively support joint embeddings across audio-video, audio-text, and video-text modalities. PE-AV's unified cross-modal embeddings enable novel tasks such as speech retrieval, and set a new state of the art across standard audio and video benchmarks. We unlock this by building a strong audiovisual data engine that synthesizes high-quality captions for O(100M) audio-video pairs, enabling large-scale supervision consistent across modalities. Our audio data includes speech, music, and general sound effects-avoiding single-domain limitations common in prior work. We exploit ten pairwise contrastive objectives, showing that scaling cross-modality and caption-type pairs strengthens alignment and improves zero-shot performance. We further develop PE-A-Frame by fine-tuning PE-AV with frame-level contrastive objectives, enabling fine-grained audio-frame-to-text alignment for tasks such as sound event detection.
SAM Audio: Segment Anything in Audio
Dec 19, 2025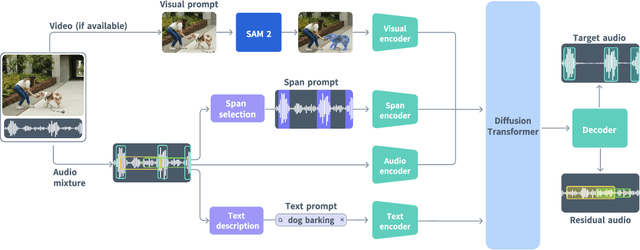

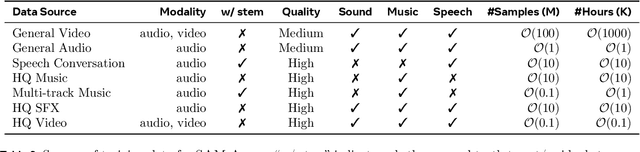
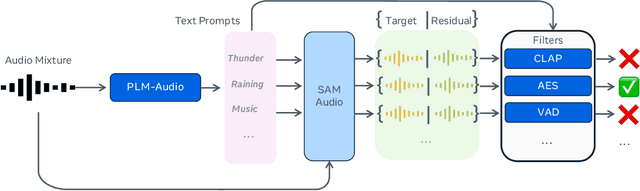
General audio source separation is a key capability for multimodal AI systems that can perceive and reason about sound. Despite substantial progress in recent years, existing separation models are either domain-specific, designed for fixed categories such as speech or music, or limited in controllability, supporting only a single prompting modality such as text. In this work, we present SAM Audio, a foundation model for general audio separation that unifies text, visual, and temporal span prompting within a single framework. Built on a diffusion transformer architecture, SAM Audio is trained with flow matching on large-scale audio data spanning speech, music, and general sounds, and can flexibly separate target sources described by language, visual masks, or temporal spans. The model achieves state-of-the-art performance across a diverse suite of benchmarks, including general sound, speech, music, and musical instrument separation in both in-the-wild and professionally produced audios, substantially outperforming prior general-purpose and specialized systems. Furthermore, we introduce a new real-world separation benchmark with human-labeled multimodal prompts and a reference-free evaluation model that correlates strongly with human judgment.
ReverbFX: A Dataset of Room Impulse Responses Derived from Reverb Effect Plugins for Singing Voice Dereverberation
May 26, 2025We present ReverbFX, a new room impulse response (RIR) dataset designed for singing voice dereverberation research. Unlike existing datasets based on real recorded RIRs, ReverbFX features a diverse collection of RIRs captured from various reverb audio effect plugins commonly used in music production. We conduct comprehensive experiments using the proposed dataset to benchmark the challenge of dereverberation of singing voice recordings affected by artificial reverbs. We train two state-of-the-art generative models using ReverbFX and demonstrate that models trained with plugin-derived RIRs outperform those trained on realistic RIRs in artificial reverb scenarios.
LipDiffuser: Lip-to-Speech Generation with Conditional Diffusion Models
May 16, 2025We present LipDiffuser, a conditional diffusion model for lip-to-speech generation synthesizing natural and intelligible speech directly from silent video recordings. Our approach leverages the magnitude-preserving ablated diffusion model (MP-ADM) architecture as a denoiser model. To effectively condition the model, we incorporate visual features using magnitude-preserving feature-wise linear modulation (MP-FiLM) alongside speaker embeddings. A neural vocoder then reconstructs the speech waveform from the generated mel-spectrograms. Evaluations on LRS3 and TCD-TIMIT demonstrate that LipDiffuser outperforms existing lip-to-speech baselines in perceptual speech quality and speaker similarity, while remaining competitive in downstream automatic speech recognition (ASR). These findings are also supported by a formal listening experiment. Extensive ablation studies and cross-dataset evaluation confirm the effectiveness and generalization capabilities of our approach.
Normalize Everything: A Preconditioned Magnitude-Preserving Architecture for Diffusion-Based Speech Enhancement
May 08, 2025This paper presents a new framework for diffusion-based speech enhancement. Our method employs a Schroedinger bridge to transform the noisy speech distribution into the clean speech distribution. To stabilize and improve training, we employ time-dependent scalings of the inputs and outputs of the network, known as preconditioning. We consider two skip connection configurations, which either include or omit the current process state in the denoiser's output, enabling the network to predict either environmental noise or clean speech. Each approach leads to improved performance on different speech enhancement metrics. To maintain stable magnitude levels and balance during training, we use a magnitude-preserving network architecture that normalizes all activations and network weights to unit length. Additionally, we propose learning the contribution of the noisy input within each network block for effective input conditioning. After training, we apply a method to approximate different exponential moving average (EMA) profiles and investigate their effects on the speech enhancement performance. In contrast to image generation tasks, where longer EMA lengths often enhance mode coverage, we observe that shorter EMA lengths consistently lead to better performance on standard speech enhancement metrics. Code, audio examples, and checkpoints are available online.
Non-intrusive Speech Quality Assessment with Diffusion Models Trained on Clean Speech
Oct 23, 2024



Diffusion models have found great success in generating high quality, natural samples of speech, but their potential for density estimation for speech has so far remained largely unexplored. In this work, we leverage an unconditional diffusion model trained only on clean speech for the assessment of speech quality. We show that the quality of a speech utterance can be assessed by estimating the likelihood of a corresponding sample in the terminating Gaussian distribution, obtained via a deterministic noising process. The resulting method is purely unsupervised, trained only on clean speech, and therefore does not rely on annotations. Our diffusion-based approach leverages clean speech priors to assess quality based on how the input relates to the learned distribution of clean data. Our proposed log-likelihoods show promising results, correlating well with intrusive speech quality metrics such as POLQA and SI-SDR.
Investigating Training Objectives for Generative Speech Enhancement
Sep 16, 2024


Generative speech enhancement has recently shown promising advancements in improving speech quality in noisy environments. Multiple diffusion-based frameworks exist, each employing distinct training objectives and learning techniques. This paper aims at explaining the differences between these frameworks by focusing our investigation on score-based generative models and Schr\"odinger bridge. We conduct a series of comprehensive experiments to compare their performance and highlight differing training behaviors. Furthermore, we propose a novel perceptual loss function tailored for the Schr\"odinger bridge framework, demonstrating enhanced performance and improved perceptual quality of the enhanced speech signals. All experimental code and pre-trained models are publicly available to facilitate further research and development in this.
EARS: An Anechoic Fullband Speech Dataset Benchmarked for Speech Enhancement and Dereverberation
Jun 11, 2024



We release the EARS (Expressive Anechoic Recordings of Speech) dataset, a high-quality speech dataset comprising 107 speakers from diverse backgrounds, totaling in 100 hours of clean, anechoic speech data. The dataset covers a large range of different speaking styles, including emotional speech, different reading styles, non-verbal sounds, and conversational freeform speech. We benchmark various methods for speech enhancement and dereverberation on the dataset and evaluate their performance through a set of instrumental metrics. In addition, we conduct a listening test with 20 participants for the speech enhancement task, where a generative method is preferred. We introduce a blind test set that allows for automatic online evaluation of uploaded data. Dataset download links and automatic evaluation server can be found online.
The PESQetarian: On the Relevance of Goodhart's Law for Speech Enhancement
Jun 05, 2024



To obtain improved speech enhancement models, researchers often focus on increasing performance according to specific instrumental metrics. However, when the same metric is used in a loss function to optimize models, it may be detrimental to aspects that the given metric does not see. The goal of this paper is to illustrate the risk of overfitting a speech enhancement model to the metric used for evaluation. For this, we introduce enhancement models that exploit the widely used PESQ measure. Our "PESQetarian" model achieves 3.82 PESQ on VB-DMD while scoring very poorly in a listening experiment. While the obtained PESQ value of 3.82 would imply "state-of-the-art" PESQ-performance on the VB-DMD benchmark, our examples show that when optimizing w.r.t. a metric, an isolated evaluation on the same metric may be misleading. Instead, other metrics should be included in the evaluation and the resulting performance predictions should be confirmed by listening.