 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeReal-Time Streamable Generative Speech Restoration with Flow Matching
Dec 22, 2025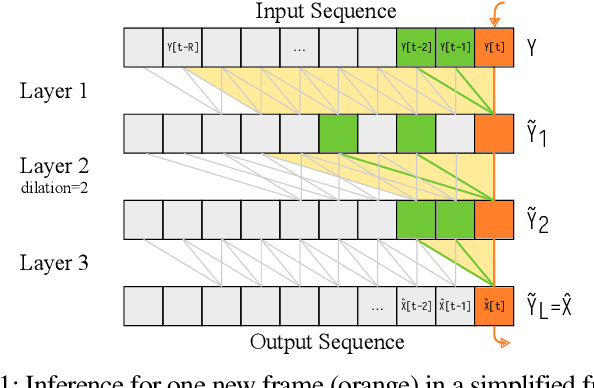
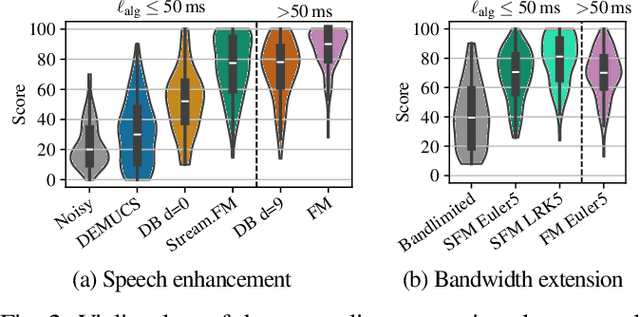

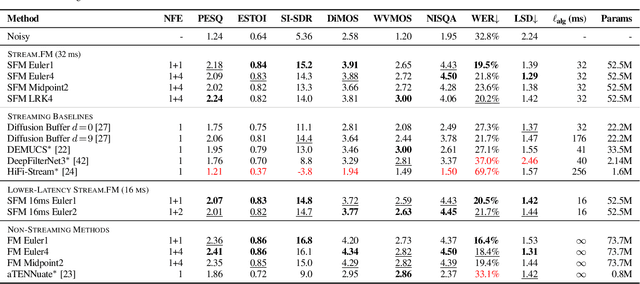
Diffusion-based generative models have greatly impacted the speech processing field in recent years, exhibiting high speech naturalness and spawning a new research direction. Their application in real-time communication is, however, still lagging behind due to their computation-heavy nature involving multiple calls of large DNNs. Here, we present Stream.FM, a frame-causal flow-based generative model with an algorithmic latency of 32 milliseconds (ms) and a total latency of 48 ms, paving the way for generative speech processing in real-time communication. We propose a buffered streaming inference scheme and an optimized DNN architecture, show how learned few-step numerical solvers can boost output quality at a fixed compute budget, explore model weight compression to find favorable points along a compute/quality tradeoff, and contribute a model variant with 24 ms total latency for the speech enhancement task. Our work looks beyond theoretical latencies, showing that high-quality streaming generative speech processing can be realized on consumer GPUs available today. Stream.FM can solve a variety of speech processing tasks in a streaming fashion: speech enhancement, dereverberation, codec post-filtering, bandwidth extension, STFT phase retrieval, and Mel vocoding. As we verify through comprehensive evaluations and a MUSHRA listening test, Stream.FM establishes a state-of-the-art for generative streaming speech restoration, exhibits only a reasonable reduction in quality compared to a non-streaming variant, and outperforms our recent work (Diffusion Buffer) on generative streaming speech enhancement while operating at a lower latency.
Real-Time Streaming Mel Vocoding with Generative Flow Matching
Sep 18, 2025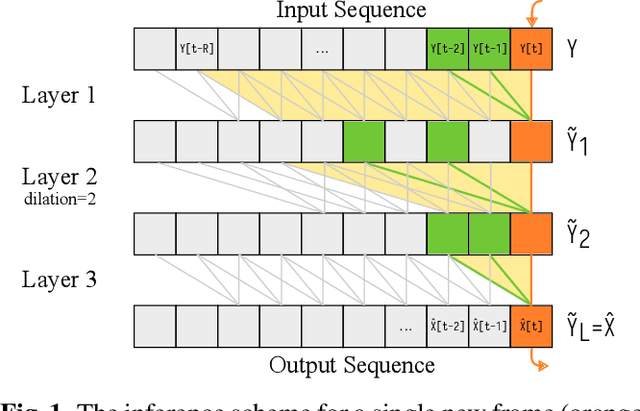
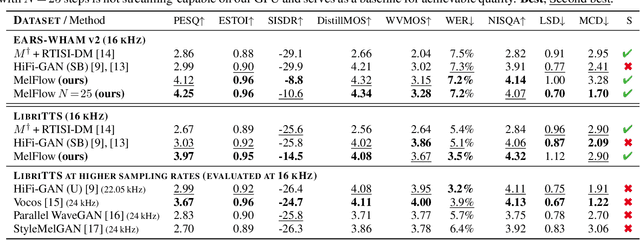
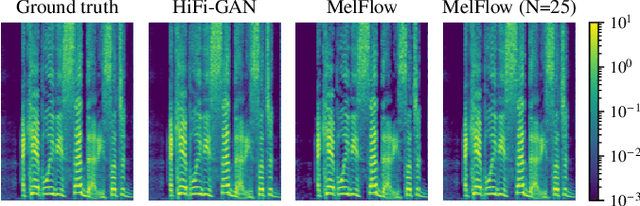
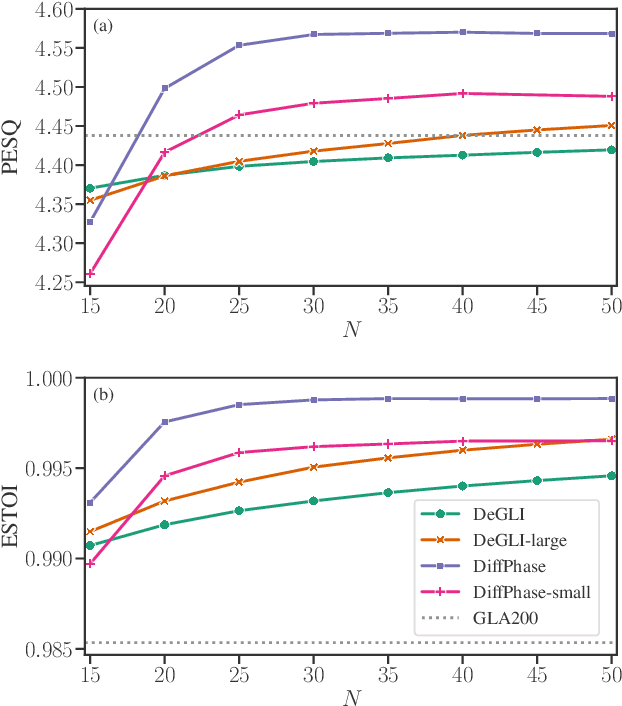
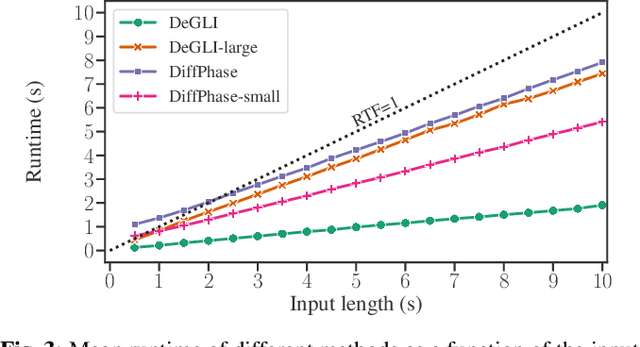
The task of Mel vocoding, i.e., the inversion of a Mel magnitude spectrogram to an audio waveform, is still a key component in many text-to-speech (TTS) systems today. Based on generative flow matching, our prior work on generative STFT phase retrieval (DiffPhase), and the pseudoinverse operator of the Mel filterbank, we develop MelFlow, a streaming-capable generative Mel vocoder for speech sampled at 16 kHz with an algorithmic latency of only 32 ms and a total latency of 48 ms. We show real-time streaming capability at this latency not only in theory, but in practice on a consumer laptop GPU. Furthermore, we show that our model achieves substantially better PESQ and SI-SDR values compared to well-established not streaming-capable baselines for Mel vocoding including HiFi-GAN.
LipDiffuser: Lip-to-Speech Generation with Conditional Diffusion Models
May 16, 2025We present LipDiffuser, a conditional diffusion model for lip-to-speech generation synthesizing natural and intelligible speech directly from silent video recordings. Our approach leverages the magnitude-preserving ablated diffusion model (MP-ADM) architecture as a denoiser model. To effectively condition the model, we incorporate visual features using magnitude-preserving feature-wise linear modulation (MP-FiLM) alongside speaker embeddings. A neural vocoder then reconstructs the speech waveform from the generated mel-spectrograms. Evaluations on LRS3 and TCD-TIMIT demonstrate that LipDiffuser outperforms existing lip-to-speech baselines in perceptual speech quality and speaker similarity, while remaining competitive in downstream automatic speech recognition (ASR). These findings are also supported by a formal listening experiment. Extensive ablation studies and cross-dataset evaluation confirm the effectiveness and generalization capabilities of our approach.
Live Iterative Ptychography with projection-based algorithms
Sep 19, 2023In this work, we demonstrate that the ptychographic phase problem can be solved in a live fashion during scanning, while data is still being collected. We propose a generally applicable modification of the widespread projection-based algorithms such as Error Reduction (ER) and Difference Map (DM). This novel variant of ptychographic phase retrieval enables immediate visual feedback during experiments, reconstruction of arbitrary-sized objects with a fixed amount of computational resources, and adaptive scanning. By building upon the Real-Time Iterative Spectrogram Inversion (RTISI) family of algorithms from the audio processing literature, we show that live variants of projection-based methods such as DM can be derived naturally and may even achieve higher-quality reconstructions than their classic non-live counterparts with comparable effective computational load.
A Flexible Online Framework for Projection-Based STFT Phase Retrieval
Sep 13, 2023Several recent contributions in the field of iterative STFT phase retrieval have demonstrated that the performance of the classical Griffin-Lim method can be considerably improved upon. By using the same projection operators as Griffin-Lim, but combining them in innovative ways, these approaches achieve better results in terms of both reconstruction quality and required number of iterations, while retaining a similar computational complexity per iteration. However, like Griffin-Lim, these algorithms operate in an offline manner and thus require an entire spectrogram as input, which is an unrealistic requirement for many real-world speech communication applications. We propose to extend RTISI -- an existing online (frame-by-frame) variant of the Griffin-Lim algorithm -- into a flexible framework that enables straightforward online implementation of any algorithm based on iterative projections. We further employ this framework to implement online variants of the fast Griffin-Lim algorithm, the accelerated Griffin-Lim algorithm, and two algorithms from the optics domain. Evaluation results on speech signals show that, similarly to the offline case, these algorithms can achieve a considerable performance gain compared to RTISI.
On the Behavior of Intrusive and Non-intrusive Speech Enhancement Metrics in Predictive and Generative Settings
Jun 05, 2023Since its inception, the field of deep speech enhancement has been dominated by predictive (discriminative) approaches, such as spectral mapping or masking. Recently, however, novel generative approaches have been applied to speech enhancement, attaining good denoising performance with high subjective quality scores. At the same time, advances in deep learning also allowed for the creation of neural network-based metrics, which have desirable traits such as being able to work without a reference (non-intrusively). Since generatively enhanced speech tends to exhibit radically different residual distortions, its evaluation using instrumental speech metrics may behave differently compared to predictively enhanced speech. In this paper, we evaluate the performance of the same speech enhancement backbone trained under predictive and generative paradigms on a variety of metrics and show that intrusive and non-intrusive measures correlate differently for each paradigm. This analysis motivates the search for metrics that can together paint a complete and unbiased picture of speech enhancement performance, irrespective of the model's training process.
Speech Signal Improvement Using Causal Generative Diffusion Models
Mar 15, 2023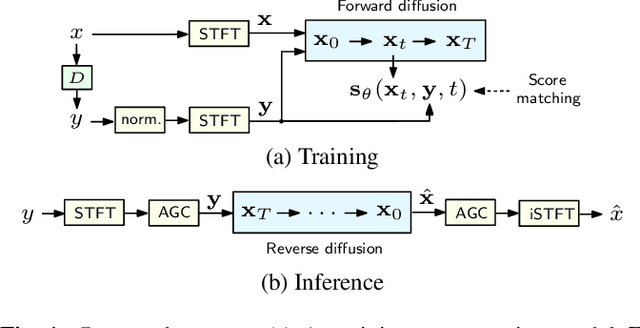
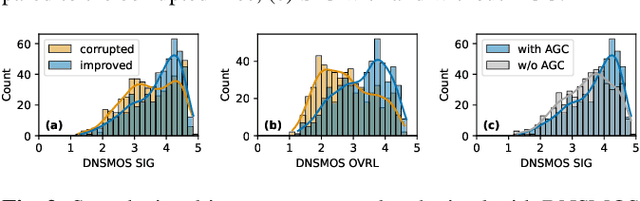
In this paper, we present a causal speech signal improvement system that is designed to handle different types of distortions. The method is based on a generative diffusion model which has been shown to work well in scenarios with missing data and non-linear corruptions. To guarantee causal processing, we modify the network architecture of our previous work and replace global normalization with causal adaptive gain control. We generate diverse training data containing a broad range of distortions. This work was performed in the context of an "ICASSP Signal Processing Grand Challenge" and submitted to the non-real-time track of the "Speech Signal Improvement Challenge 2023", where it was ranked fifth.
DiffPhase: Generative Diffusion-based STFT Phase Retrieval
Nov 08, 2022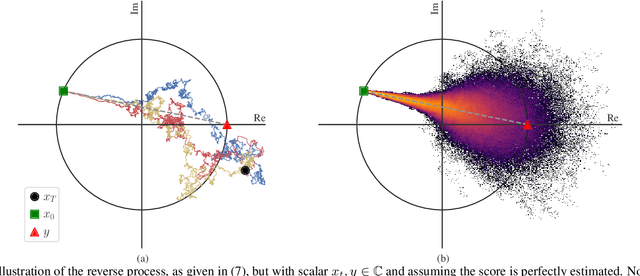

Diffusion probabilistic models have been recently used in a variety of tasks, including speech enhancement and synthesis. As a generative approach, diffusion models have been shown to be especially suitable for imputation problems, where missing data is generated based on existing data. Phase retrieval is inherently an imputation problem, where phase information has to be generated based on the given magnitude. In this work we build upon previous work in the speech domain, adapting a speech enhancement diffusion model specifically for STFT phase retrieval. Evaluation using speech quality and intelligibility metrics shows the diffusion approach is well-suited to the phase retrieval task, with performance surpassing both classical and modern methods.
Efficient Transformer-based Speech Enhancement Using Long Frames and STFT Magnitudes
Jun 23, 2022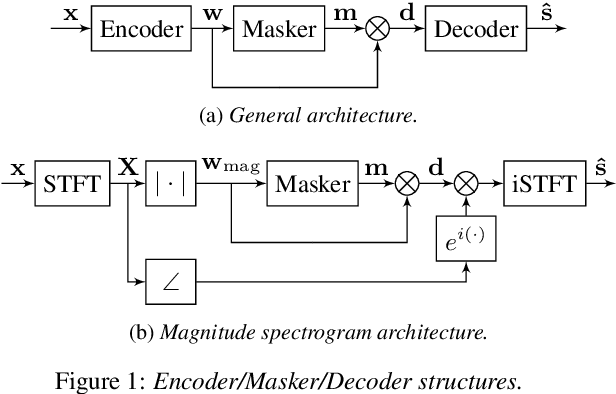
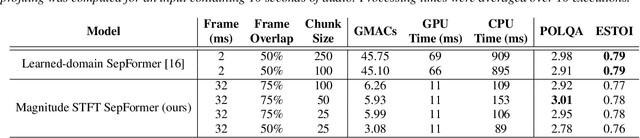
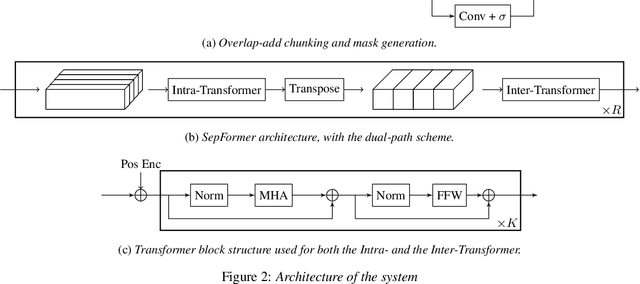
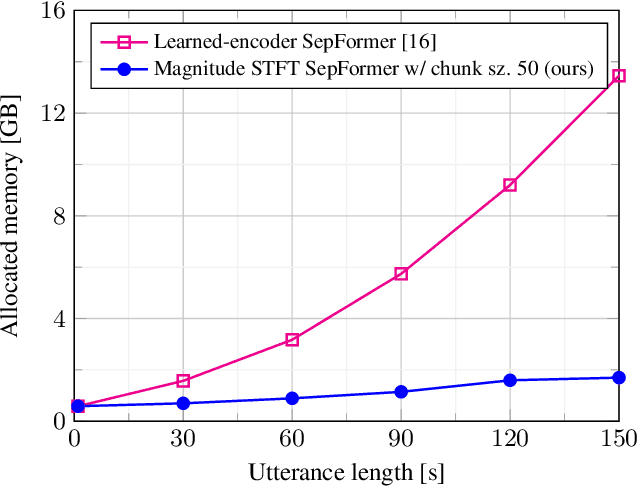
The SepFormer architecture shows very good results in speech separation. Like other learned-encoder models, it uses short frames, as they have been shown to obtain better performance in these cases. This results in a large number of frames at the input, which is problematic; since the SepFormer is transformer-based, its computational complexity drastically increases with longer sequences. In this paper, we employ the SepFormer in a speech enhancement task and show that by replacing the learned-encoder features with a magnitude short-time Fourier transform (STFT) representation, we can use long frames without compromising perceptual enhancement performance. We obtained equivalent quality and intelligibility evaluation scores while reducing the number of operations by a factor of approximately 8 for a 10-second utterance.
Beyond Griffin-Lim: Improved Iterative Phase Retrieval for Speech
May 11, 2022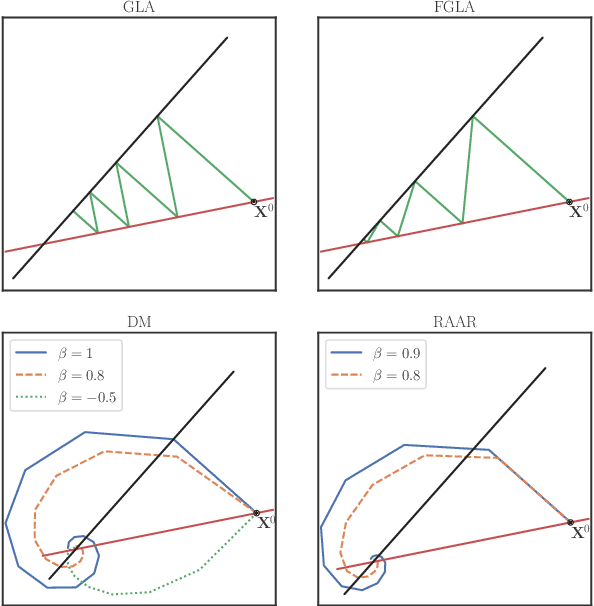
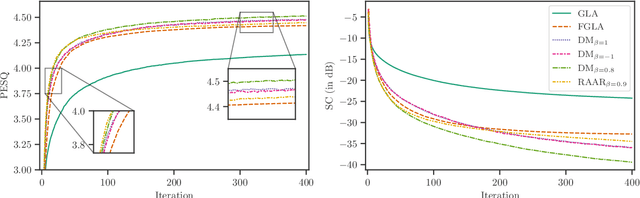
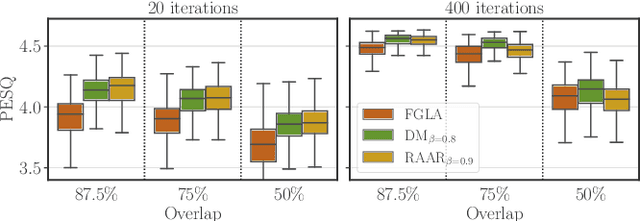
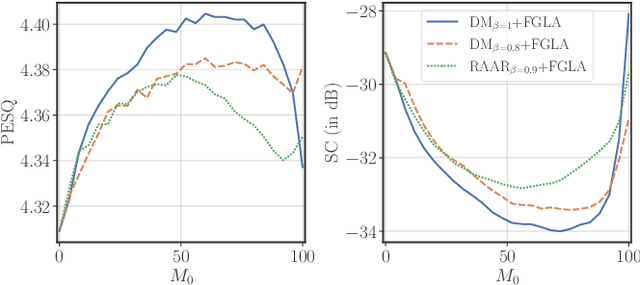
Phase retrieval is a problem encountered not only in speech and audio processing, but in many other fields such as optics. Iterative algorithms based on non-convex set projections are effective and frequently used for retrieving the phase when only STFT magnitudes are available. While the basic Griffin-Lim algorithm and its variants have been the prevalent method for decades, more recent advances, e.g. in optics, raise the question: Can we do better than Griffin-Lim for speech signals, using the same principle of iterative projection? In this paper we compare the classical algorithms in the speech domain with two modern methods from optics with respect to reconstruction quality and convergence rate. Based on this study, we propose to combine Griffin-Lim with the Difference Map algorithm in a hybrid approach which shows superior results, in terms of both convergence and quality of the final reconstruction.