 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeA Fast Solver for Interpolating Stochastic Differential Equation Diffusion Models for Speech Restoration
Mar 10, 2026Diffusion Probabilistic Models (DPMs) are a well-established class of diffusion models for unconditional image generation, while SGMSE+ is a well-established conditional diffusion model for speech enhancement. One of the downsides of diffusion models is that solving the reverse process requires many evaluations of a large Neural Network. Although advanced fast sampling solvers have been developed for DPMs, they are not directly applicable to models such as SGMSE+ due to differences in their diffusion processes. Specifically, DPMs transform between the data distribution and a standard Gaussian distribution, whereas SGMSE+ interpolates between the target distribution and a noisy observation. This work first develops a formalism of interpolating Stochastic Differential Equations (iSDEs) that includes SGMSE+, and second proposes a solver for iSDEs. The proposed solver enables fast sampling with as few as 10 Neural Network evaluations across multiple speech restoration tasks.
Bone-conduction Guided Multimodal Speech Enhancement with Conditional Diffusion Models
Jan 18, 2026Single-channel speech enhancement models face significant performance degradation in extremely noisy environments. While prior work has shown that complementary bone-conducted speech can guide enhancement, effective integration of this noise-immune modality remains a challenge. This paper introduces a novel multimodal speech enhancement framework that integrates bone-conduction sensors with air-conducted microphones using a conditional diffusion model. Our proposed model significantly outperforms previously established multimodal techniques and a powerful diffusion-based single-modal baseline across a wide range of acoustic conditions.
Real-Time Streamable Generative Speech Restoration with Flow Matching
Dec 22, 2025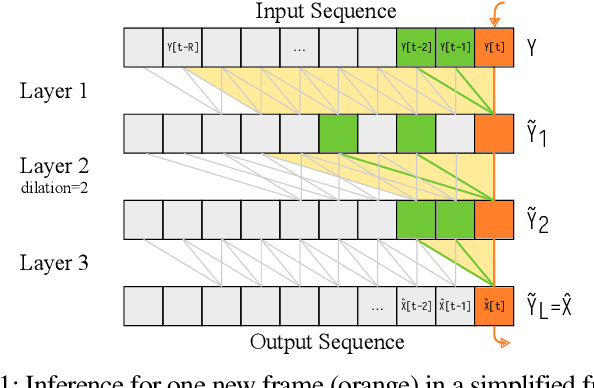
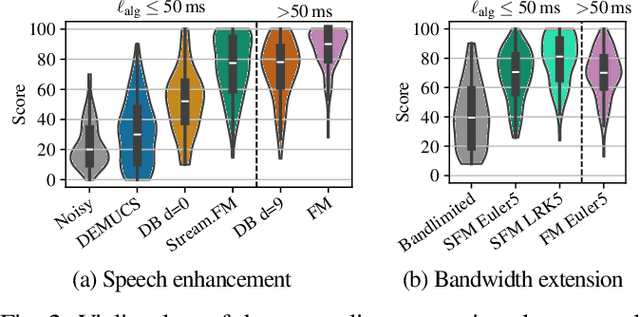

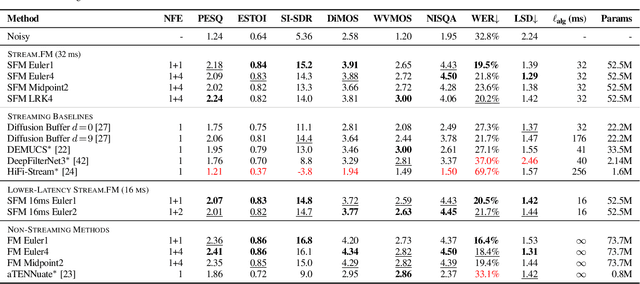
Diffusion-based generative models have greatly impacted the speech processing field in recent years, exhibiting high speech naturalness and spawning a new research direction. Their application in real-time communication is, however, still lagging behind due to their computation-heavy nature involving multiple calls of large DNNs. Here, we present Stream.FM, a frame-causal flow-based generative model with an algorithmic latency of 32 milliseconds (ms) and a total latency of 48 ms, paving the way for generative speech processing in real-time communication. We propose a buffered streaming inference scheme and an optimized DNN architecture, show how learned few-step numerical solvers can boost output quality at a fixed compute budget, explore model weight compression to find favorable points along a compute/quality tradeoff, and contribute a model variant with 24 ms total latency for the speech enhancement task. Our work looks beyond theoretical latencies, showing that high-quality streaming generative speech processing can be realized on consumer GPUs available today. Stream.FM can solve a variety of speech processing tasks in a streaming fashion: speech enhancement, dereverberation, codec post-filtering, bandwidth extension, STFT phase retrieval, and Mel vocoding. As we verify through comprehensive evaluations and a MUSHRA listening test, Stream.FM establishes a state-of-the-art for generative streaming speech restoration, exhibits only a reasonable reduction in quality compared to a non-streaming variant, and outperforms our recent work (Diffusion Buffer) on generative streaming speech enhancement while operating at a lower latency.
Robustness of Speech Separation Models for Similar-pitch Speakers
Jul 22, 2024Single-channel speech separation is a crucial task for enhancing speech recognition systems in multi-speaker environments. This paper investigates the robustness of state-of-the-art Neural Network models in scenarios where the pitch differences between speakers are minimal. Building on earlier findings by Ditter and Gerkmann, which identified a significant performance drop for the 2018 Chimera++ under similar-pitch conditions, our study extends the analysis to more recent and sophisticated Neural Network models. Our experiments reveal that modern models have substantially reduced the performance gap for matched training and testing conditions. However, a substantial performance gap persists under mismatched conditions, with models performing well for large pitch differences but showing worse performance if the speakers' pitches are similar. These findings motivate further research into the generalizability of speech separation models to similar-pitch speakers and unseen data.
EARS: An Anechoic Fullband Speech Dataset Benchmarked for Speech Enhancement and Dereverberation
Jun 11, 2024



We release the EARS (Expressive Anechoic Recordings of Speech) dataset, a high-quality speech dataset comprising 107 speakers from diverse backgrounds, totaling in 100 hours of clean, anechoic speech data. The dataset covers a large range of different speaking styles, including emotional speech, different reading styles, non-verbal sounds, and conversational freeform speech. We benchmark various methods for speech enhancement and dereverberation on the dataset and evaluate their performance through a set of instrumental metrics. In addition, we conduct a listening test with 20 participants for the speech enhancement task, where a generative method is preferred. We introduce a blind test set that allows for automatic online evaluation of uploaded data. Dataset download links and automatic evaluation server can be found online.
An Analysis of the Variance of Diffusion-based Speech Enhancement
Feb 01, 2024Diffusion models proved to be powerful models for generative speech enhancement. In recent SGMSE+ approaches, training involves a stochastic differential equation for the diffusion process, adding both Gaussian and environmental noise to the clean speech signal gradually. The speech enhancement performance varies depending on the choice of the stochastic differential equation that controls the evolution of the mean and the variance along the diffusion processes when adding environmental and Gaussian noise. In this work, we highlight that the scale of the variance is a dominant parameter for speech enhancement performance and show that it controls the tradeoff between noise attenuation and speech distortions. More concretely, we show that a larger variance increases the noise attenuation and allows for reducing the computational footprint, as fewer function evaluations for generating the estimate are required.
Single and Few-step Diffusion for Generative Speech Enhancement
Sep 18, 2023

Diffusion models have shown promising results in speech enhancement, using a task-adapted diffusion process for the conditional generation of clean speech given a noisy mixture. However, at test time, the neural network used for score estimation is called multiple times to solve the iterative reverse process. This results in a slow inference process and causes discretization errors that accumulate over the sampling trajectory. In this paper, we address these limitations through a two-stage training approach. In the first stage, we train the diffusion model the usual way using the generative denoising score matching loss. In the second stage, we compute the enhanced signal by solving the reverse process and compare the resulting estimate to the clean speech target using a predictive loss. We show that using this second training stage enables achieving the same performance as the baseline model using only 5 function evaluations instead of 60 function evaluations. While the performance of usual generative diffusion algorithms drops dramatically when lowering the number of function evaluations (NFEs) to obtain single-step diffusion, we show that our proposed method keeps a steady performance and therefore largely outperforms the diffusion baseline in this setting and also generalizes better than its predictive counterpart.
EMOCONV-DIFF: Diffusion-based Speech Emotion Conversion for Non-parallel and In-the-wild Data
Sep 14, 2023



Speech emotion conversion is the task of converting the expressed emotion of a spoken utterance to a target emotion while preserving the lexical content and speaker identity. While most existing works in speech emotion conversion rely on acted-out datasets and parallel data samples, in this work we specifically focus on more challenging in-the-wild scenarios and do not rely on parallel data. To this end, we propose a diffusion-based generative model for speech emotion conversion, the EmoConv-Diff, that is trained to reconstruct an input utterance while also conditioning on its emotion. Subsequently, at inference, a target emotion embedding is employed to convert the emotion of the input utterance to the given target emotion. As opposed to performing emotion conversion on categorical representations, we use a continuous arousal dimension to represent emotions while also achieving intensity control. We validate the proposed methodology on a large in-the-wild dataset, the MSP-Podcast v1.10. Our results show that the proposed diffusion model is indeed capable of synthesizing speech with a controllable target emotion. Crucially, the proposed approach shows improved performance along the extreme values of arousal and thereby addresses a common challenge in the speech emotion conversion literature.
Speech Signal Improvement Using Causal Generative Diffusion Models
Mar 15, 2023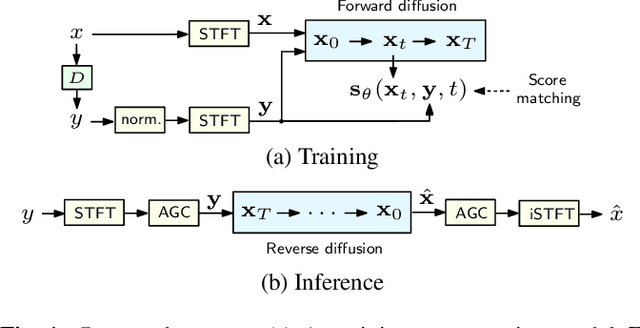
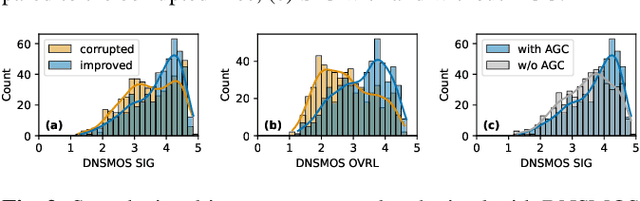
In this paper, we present a causal speech signal improvement system that is designed to handle different types of distortions. The method is based on a generative diffusion model which has been shown to work well in scenarios with missing data and non-linear corruptions. To guarantee causal processing, we modify the network architecture of our previous work and replace global normalization with causal adaptive gain control. We generate diverse training data containing a broad range of distortions. This work was performed in the context of an "ICASSP Signal Processing Grand Challenge" and submitted to the non-real-time track of the "Speech Signal Improvement Challenge 2023", where it was ranked fifth.
Reducing the Prior Mismatch of Stochastic Differential Equations for Diffusion-based Speech Enhancement
Feb 28, 2023


Recently, score-based generative models have been successfully employed for the task of speech enhancement. A stochastic differential equation is used to model the iterative forward process, where at each step environmental noise and white Gaussian noise are added to the clean speech signal. While in limit the mean of the forward process ends at the noisy mixture, in practice it stops earlier and thus only at an approximation of the noisy mixture. This results in a discrepancy between the terminating distribution of the forward process and the prior used for solving the reverse process at inference. In this paper, we address this discrepancy. To this end, we propose a forward process based on a Brownian bridge and show that such a process leads to a reduction of the mismatch compared to previous diffusion processes. More importantly, we show that our approach improves in objective metrics over the baseline process with only half of the iteration steps and having one hyperparameter less to tune.