 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAutoregressive Guidance of Deep Spatially Selective Filters using Bayesian Tracking for Efficient Extraction of Moving Speakers
Mar 24, 2026Deep spatially selective filters achieve high-quality enhancement with real-time capable architectures for stationary speakers of known directions. To retain this level of performance in dynamic scenarios when only the speakers' initial directions are given, accurate, yet computationally lightweight tracking algorithms become necessary. Assuming a frame-wise causal processing style, temporal feedback allows for leveraging the enhanced speech signal to improve tracking performance. In this work, we investigate strategies to incorporate the enhanced signal into lightweight tracking algorithms and autoregressively guide deep spatial filters. Our proposed Bayesian tracking algorithms are compatible with arbitrary deep spatial filters. To increase the realism of simulated trajectories during development and evaluation, we propose and publish a novel dataset based on the social force model. Results validate that the autoregressive incorporation significantly improves the accuracy of our Bayesian trackers, resulting in superior enhancement with none or only negligibly increased computational overhead. Real-world recordings complement these findings and demonstrate the generalizability of our methods to unseen, challenging acoustic conditions.
A Fast Solver for Interpolating Stochastic Differential Equation Diffusion Models for Speech Restoration
Mar 10, 2026Diffusion Probabilistic Models (DPMs) are a well-established class of diffusion models for unconditional image generation, while SGMSE+ is a well-established conditional diffusion model for speech enhancement. One of the downsides of diffusion models is that solving the reverse process requires many evaluations of a large Neural Network. Although advanced fast sampling solvers have been developed for DPMs, they are not directly applicable to models such as SGMSE+ due to differences in their diffusion processes. Specifically, DPMs transform between the data distribution and a standard Gaussian distribution, whereas SGMSE+ interpolates between the target distribution and a noisy observation. This work first develops a formalism of interpolating Stochastic Differential Equations (iSDEs) that includes SGMSE+, and second proposes a solver for iSDEs. The proposed solver enables fast sampling with as few as 10 Neural Network evaluations across multiple speech restoration tasks.
Adaptive Rotary Steering with Joint Autoregression for Robust Extraction of Closely Moving Speakers in Dynamic Scenarios
Jan 21, 2026Latest advances in deep spatial filtering for Ambisonics demonstrate strong performance in stationary multi-speaker scenarios by rotating the sound field toward a target speaker prior to multi-channel enhancement. For applicability in dynamic acoustic conditions with moving speakers, we propose to automate this rotary steering using an interleaved tracking algorithm conditioned on the target's initial direction. However, for nearby or crossing speakers, robust tracking becomes difficult and spatial cues less effective for enhancement. By incorporating the processed recording as additional guide into both algorithms, our novel joint autoregressive framework leverages temporal-spectral correlations of speech to resolve spatially challenging speaker constellations. Consequently, our proposed method significantly improves tracking and enhancement of closely spaced speakers, consistently outperforming comparable non-autoregressive methods on a synthetic dataset. Real-world recordings complement these findings in complex scenarios with multiple speaker crossings and varying speaker-to-array distances.
Bone-conduction Guided Multimodal Speech Enhancement with Conditional Diffusion Models
Jan 18, 2026Single-channel speech enhancement models face significant performance degradation in extremely noisy environments. While prior work has shown that complementary bone-conducted speech can guide enhancement, effective integration of this noise-immune modality remains a challenge. This paper introduces a novel multimodal speech enhancement framework that integrates bone-conduction sensors with air-conducted microphones using a conditional diffusion model. Our proposed model significantly outperforms previously established multimodal techniques and a powerful diffusion-based single-modal baseline across a wide range of acoustic conditions.
Real-Time Streamable Generative Speech Restoration with Flow Matching
Dec 22, 2025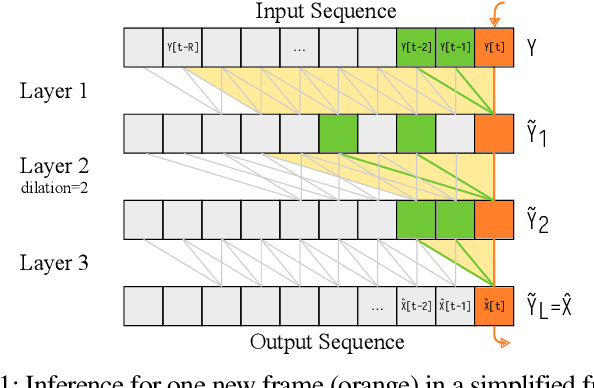
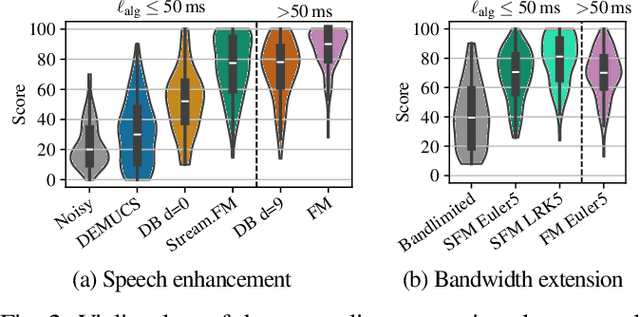

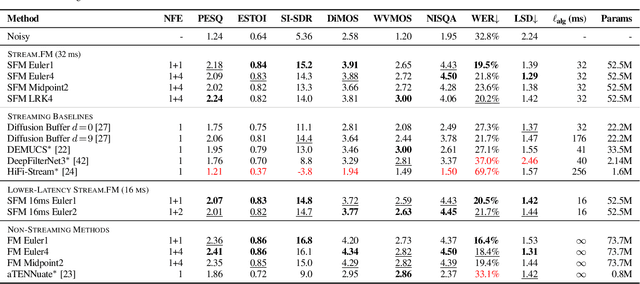
Diffusion-based generative models have greatly impacted the speech processing field in recent years, exhibiting high speech naturalness and spawning a new research direction. Their application in real-time communication is, however, still lagging behind due to their computation-heavy nature involving multiple calls of large DNNs. Here, we present Stream.FM, a frame-causal flow-based generative model with an algorithmic latency of 32 milliseconds (ms) and a total latency of 48 ms, paving the way for generative speech processing in real-time communication. We propose a buffered streaming inference scheme and an optimized DNN architecture, show how learned few-step numerical solvers can boost output quality at a fixed compute budget, explore model weight compression to find favorable points along a compute/quality tradeoff, and contribute a model variant with 24 ms total latency for the speech enhancement task. Our work looks beyond theoretical latencies, showing that high-quality streaming generative speech processing can be realized on consumer GPUs available today. Stream.FM can solve a variety of speech processing tasks in a streaming fashion: speech enhancement, dereverberation, codec post-filtering, bandwidth extension, STFT phase retrieval, and Mel vocoding. As we verify through comprehensive evaluations and a MUSHRA listening test, Stream.FM establishes a state-of-the-art for generative streaming speech restoration, exhibits only a reasonable reduction in quality compared to a non-streaming variant, and outperforms our recent work (Diffusion Buffer) on generative streaming speech enhancement while operating at a lower latency.
Real-Time Streaming Mel Vocoding with Generative Flow Matching
Sep 18, 2025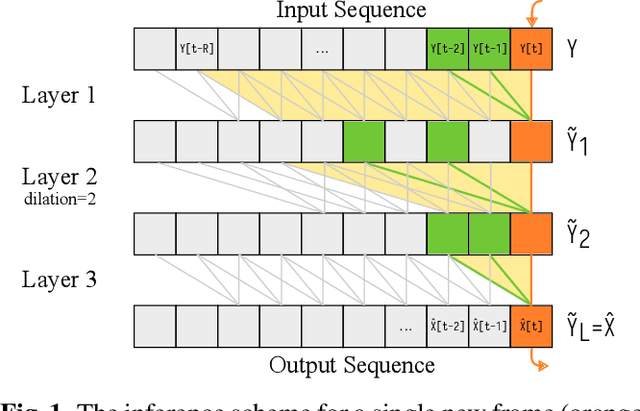
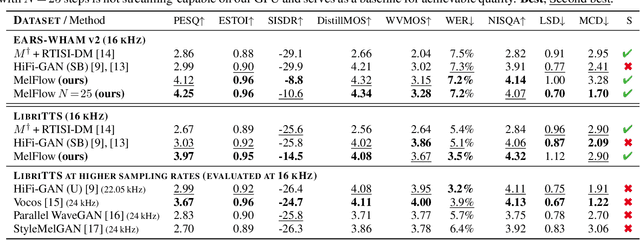
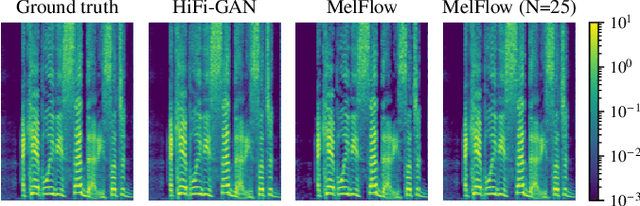
The task of Mel vocoding, i.e., the inversion of a Mel magnitude spectrogram to an audio waveform, is still a key component in many text-to-speech (TTS) systems today. Based on generative flow matching, our prior work on generative STFT phase retrieval (DiffPhase), and the pseudoinverse operator of the Mel filterbank, we develop MelFlow, a streaming-capable generative Mel vocoder for speech sampled at 16 kHz with an algorithmic latency of only 32 ms and a total latency of 48 ms. We show real-time streaming capability at this latency not only in theory, but in practice on a consumer laptop GPU. Furthermore, we show that our model achieves substantially better PESQ and SI-SDR values compared to well-established not streaming-capable baselines for Mel vocoding including HiFi-GAN.
Self-Steering Deep Non-Linear Spatially Selective Filters for Efficient Extraction of Moving Speakers under Weak Guidance
Jul 03, 2025Recent works on deep non-linear spatially selective filters demonstrate exceptional enhancement performance with computationally lightweight architectures for stationary speakers of known directions. However, to maintain this performance in dynamic scenarios, resource-intensive data-driven tracking algorithms become necessary to provide precise spatial guidance conditioned on the initial direction of a target speaker. As this additional computational overhead hinders application in resource-constrained scenarios such as real-time speech enhancement, we present a novel strategy utilizing a low-complexity tracking algorithm in the form of a particle filter instead. Assuming a causal, sequential processing style, we introduce temporal feedback to leverage the enhanced speech signal of the spatially selective filter to compensate for the limited modeling capabilities of the particle filter. Evaluation on a synthetic dataset illustrates how the autoregressive interplay between both algorithms drastically improves tracking accuracy and leads to strong enhancement performance. A listening test with real-world recordings complements these findings by indicating a clear trend towards our proposed self-steering pipeline as preferred choice over comparable methods.
ReverbFX: A Dataset of Room Impulse Responses Derived from Reverb Effect Plugins for Singing Voice Dereverberation
May 26, 2025We present ReverbFX, a new room impulse response (RIR) dataset designed for singing voice dereverberation research. Unlike existing datasets based on real recorded RIRs, ReverbFX features a diverse collection of RIRs captured from various reverb audio effect plugins commonly used in music production. We conduct comprehensive experiments using the proposed dataset to benchmark the challenge of dereverberation of singing voice recordings affected by artificial reverbs. We train two state-of-the-art generative models using ReverbFX and demonstrate that models trained with plugin-derived RIRs outperform those trained on realistic RIRs in artificial reverb scenarios.
Steering Deep Non-Linear Spatially Selective Filters for Weakly Guided Extraction of Moving Speakers in Dynamic Scenarios
May 20, 2025Recent speaker extraction methods using deep non-linear spatial filtering perform exceptionally well when the target direction is known and stationary. However, spatially dynamic scenarios are considerably more challenging due to time-varying spatial features and arising ambiguities, e.g. when moving speakers cross. While in a static scenario it may be easy for a user to point to the target's direction, manually tracking a moving speaker is impractical. Instead of relying on accurate time-dependent directional cues, which we refer to as strong guidance, in this paper we propose a weakly guided extraction method solely depending on the target's initial position to cope with spatial dynamic scenarios. By incorporating our own deep tracking algorithm and developing a joint training strategy on a synthetic dataset, we demonstrate the proficiency of our approach in resolving spatial ambiguities and even outperform a mismatched, but strongly guided extraction method.
Normalize Everything: A Preconditioned Magnitude-Preserving Architecture for Diffusion-Based Speech Enhancement
May 08, 2025This paper presents a new framework for diffusion-based speech enhancement. Our method employs a Schroedinger bridge to transform the noisy speech distribution into the clean speech distribution. To stabilize and improve training, we employ time-dependent scalings of the inputs and outputs of the network, known as preconditioning. We consider two skip connection configurations, which either include or omit the current process state in the denoiser's output, enabling the network to predict either environmental noise or clean speech. Each approach leads to improved performance on different speech enhancement metrics. To maintain stable magnitude levels and balance during training, we use a magnitude-preserving network architecture that normalizes all activations and network weights to unit length. Additionally, we propose learning the contribution of the noisy input within each network block for effective input conditioning. After training, we apply a method to approximate different exponential moving average (EMA) profiles and investigate their effects on the speech enhancement performance. In contrast to image generation tasks, where longer EMA lengths often enhance mode coverage, we observe that shorter EMA lengths consistently lead to better performance on standard speech enhancement metrics. Code, audio examples, and checkpoints are available online.