 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeUnsupervised Estimation of Nonlinear Audio Effects: Comparing Diffusion-Based and Adversarial approaches
Apr 07, 2025Accurately estimating nonlinear audio effects without access to paired input-output signals remains a challenging problem.This work studies unsupervised probabilistic approaches for solving this task. We introduce a method, novel for this application, based on diffusion generative models for blind system identification, enabling the estimation of unknown nonlinear effects using black- and gray-box models. This study compares this method with a previously proposed adversarial approach, analyzing the performance of both methods under different parameterizations of the effect operator and varying lengths of available effected recordings.Through experiments on guitar distortion effects, we show that the diffusion-based approach provides more stable results and is less sensitive to data availability, while the adversarial approach is superior at estimating more pronounced distortion effects. Our findings contribute to the robust unsupervised blind estimation of audio effects, demonstrating the potential of diffusion models for system identification in music technology.
Resampling Filter Design for Multirate Neural Audio Effect Processing
Jan 30, 2025Neural networks have become ubiquitous in audio effects modelling, especially for guitar amplifiers and distortion pedals. One limitation of such models is that the sample rate of the training data is implicitly encoded in the model weights and therefore not readily adjustable at inference. Recent work explored modifications to recurrent neural network architecture to approximate a sample rate independent system, enabling audio processing at a rate that differs from the original training rate. This method works well for integer oversampling and can reduce aliasing caused by nonlinear activation functions. For small fractional changes in sample rate, fractional delay filters can be used to approximate sample rate independence, but in some cases this method fails entirely. Here, we explore the use of signal resampling at the input and output of the neural network as an alternative solution. We investigate several resampling filter designs and show that a two-stage design consisting of a half-band IIR filter cascaded with a Kaiser window FIR filter can give similar or better results to the previously proposed model adjustment method with many fewer operations per sample and less than one millisecond of latency at typical audio rates. Furthermore, we investigate interpolation and decimation filters for the task of integer oversampling and show that cascaded half-band IIR and FIR designs can be used in conjunction with the model adjustment method to reduce aliasing in a range of distortion effect models.
Estimation and Restoration of Unknown Nonlinear Distortion using Diffusion
Jan 10, 2025The restoration of nonlinearly distorted audio signals, alongside the identification of the applied memoryless nonlinear operation, is studied. The paper focuses on the difficult but practically important case in which both the nonlinearity and the original input signal are unknown. The proposed method uses a generative diffusion model trained unconditionally on guitar or speech signals to jointly model and invert the nonlinear system at inference time. Both the memoryless nonlinear function model and the restored audio signal are obtained as output. Successful example case studies are presented including inversion of hard and soft clipping, digital quantization, half-wave rectification, and wavefolding nonlinearities. Our results suggest that, out of the nonlinear functions tested here, the cubic Catmull-Rom spline is best suited to approximating these nonlinearities. In the case of guitar recordings, comparisons with informed and supervised methods show that the proposed blind method is at least as good as they are in terms of objective metrics. Experiments on distorted speech show that the proposed blind method outperforms general-purpose speech enhancement techniques and restores the original voice quality. The proposed method can be applied to audio effects modeling, restoration of music and speech recordings, and characterization of analog recording media.
HRTF Estimation using a Score-based Prior
Oct 02, 2024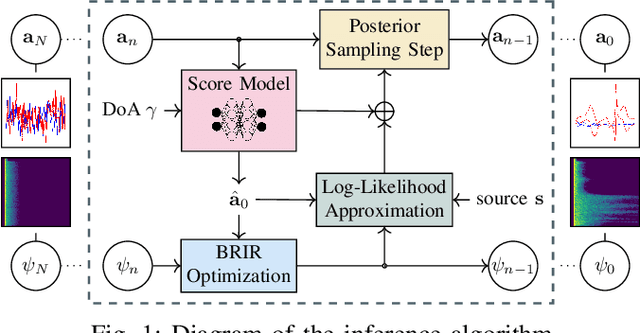
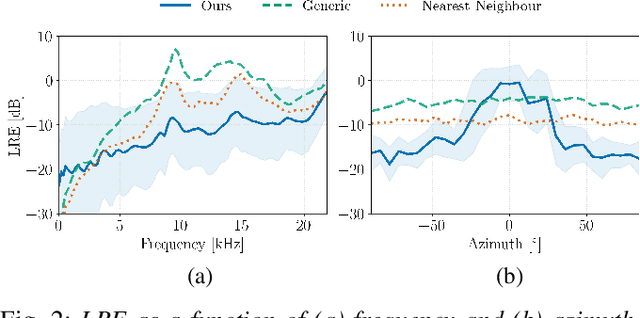
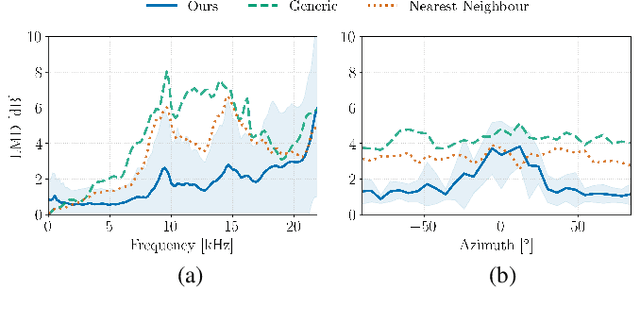

We present a head-related transfer function (HRTF) estimation method which relies on a data-driven prior given by a score-based diffusion model. The HRTF is estimated in reverberant environments using natural excitation signals, e.g. human speech. The impulse response of the room is estimated along with the HRTF by optimizing a parametric model of reverberation based on the statistical behaviour of room acoustics. The posterior distribution of HRTF given the reverberant measurement and excitation signal is modelled using the score-based HRTF prior and a log-likelihood approximation. We show that the resulting method outperforms several baselines, including an oracle recommender system that assigns the optimal HRTF in our training set based on the smallest distance to the true HRTF at the given direction of arrival. In particular, we show that the diffusion prior can account for the large variability of high-frequency content in HRTFs.
FLAMO: An Open-Source Library for Frequency-Domain Differentiable Audio Processing
Sep 13, 2024


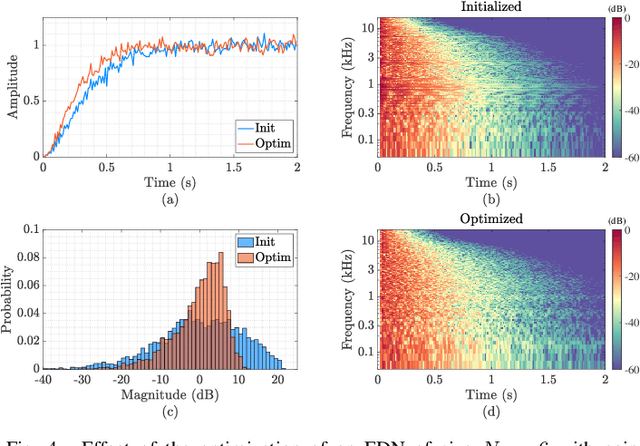
We present FLAMO, a Frequency-sampling Library for Audio-Module Optimization designed to implement and optimize differentiable linear time-invariant audio systems. The library is open-source and built on the frequency-sampling filter design method, allowing for the creation of differentiable modules that can be used stand-alone or within the computation graph of neural networks, simplifying the development of differentiable audio systems. It includes predefined filtering modules and auxiliary classes for constructing, training, and logging the optimized systems, all accessible through an intuitive interface. Practical application of these modules is demonstrated through two case studies: the optimization of an artificial reverberator and an active acoustics system for improved response smoothness.
Similarity Metrics For Late Reverberation
Aug 27, 2024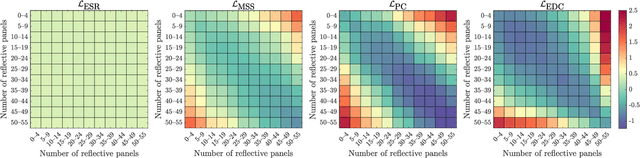
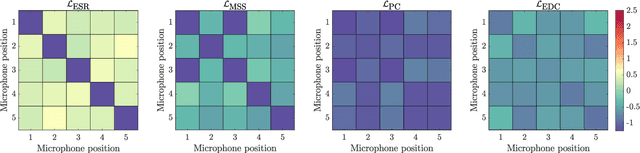
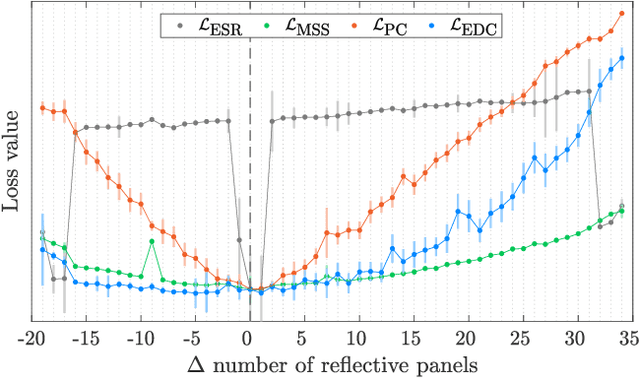
Automatic tuning of reverberation algorithms relies on the optimization of a cost function. While general audio similarity metrics are useful, they are not optimized for the specific statistical properties of reverberation in rooms. This paper presents two novel metrics for assessing the similarity of late reverberation in room impulse responses. These metrics are differentiable and can be utilized within a machine-learning framework. We compare the performance of these metrics to two popular audio metrics using a large dataset of room impulse responses encompassing various room configurations and microphone positions. The results indicate that the proposed functions based on averaged power and frequency-band energy decay outperform the baselines with the former exhibiting the most suitable profile towards the minimum. The proposed work holds promise as an improvement to the design and evaluation of reverberation similarity metrics.
Unsupervised Blind Joint Dereverberation and Room Acoustics Estimation with Diffusion Models
Aug 14, 2024This paper presents an unsupervised method for single-channel blind dereverberation and room impulse response (RIR) estimation, called BUDDy. The algorithm is rooted in Bayesian posterior sampling: it combines a likelihood model enforcing fidelity to the reverberant measurement, and an anechoic speech prior implemented by an unconditional diffusion model. We design a parametric filter representing the RIR, with exponential decay for each frequency subband. Room acoustics estimation and speech dereverberation are jointly carried out, as the filter parameters are iteratively estimated and the speech utterance refined along the reverse diffusion trajectory. In a blind scenario where the room impulse response is unknown, BUDDy successfully performs speech dereverberation in various acoustic scenarios, significantly outperforming other blind unsupervised baselines. Unlike supervised methods, which often struggle to generalize, BUDDy seamlessly adapts to different acoustic conditions. This paper extends our previous work by offering new experimental results and insights into the algorithm's performance and versatility. We first investigate the robustness of informed dereverberation methods to RIR estimation errors, to motivate the joint acoustic estimation and dereverberation paradigm. Then, we demonstrate the adaptability of our method to high-resolution singing voice dereverberation, study its performance in RIR estimation, and conduct subjective evaluation experiments to validate the perceptual quality of the results, among other contributions. Audio samples and code can be found online.
Fade-in Reverberation in Multi-room Environments Using the Common-Slope Model
Jul 18, 2024In multi-room environments, modelling the sound propagation is complex due to the coupling of rooms and diverse source-receiver positions. A common scenario is when the source and the receiver are in different rooms without a clear line of sight. For such source-receiver configurations, an initial increase in energy is observed, referred to as the "fade-in" of reverberation. Based on recent work of representing inhomogeneous and anisotropic reverberation with common decay times, this work proposes an extended parametric model that enables the modelling of the fade-in phenomenon. The method performs fitting on the envelopes, instead of energy decay functions, and allows negative amplitudes of decaying exponentials. We evaluate the method on simulated and measured multi-room environments, where we show that the proposed approach can now model the fade-ins that were unrealisable with the previous method.
Sample Rate Independent Recurrent Neural Networks for Audio Effects Processing
Jun 10, 2024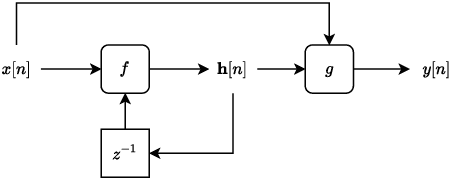

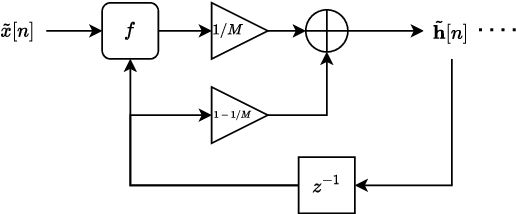
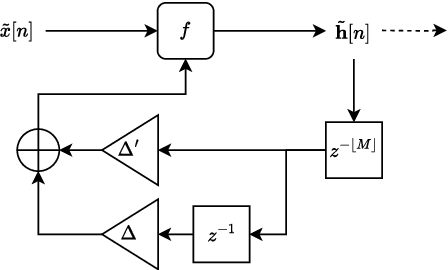
In recent years, machine learning approaches to modelling guitar amplifiers and effects pedals have been widely investigated and have become standard practice in some consumer products. In particular, recurrent neural networks (RNNs) are a popular choice for modelling non-linear devices such as vacuum tube amplifiers and distortion circuitry. One limitation of such models is that they are trained on audio at a specific sample rate and therefore give unreliable results when operating at another rate. Here, we investigate several methods of modifying RNN structures to make them approximately sample rate independent, with a focus on oversampling. In the case of integer oversampling, we demonstrate that a previously proposed delay-based approach provides high fidelity sample rate conversion whilst additionally reducing aliasing. For non-integer sample rate adjustment, we propose two novel methods and show that one of these, based on cubic Lagrange interpolation of a delay-line, provides a significant improvement over existing methods. To our knowledge, this work provides the first in-depth study into this problem.
BUDDy: Single-Channel Blind Unsupervised Dereverberation with Diffusion Models
May 07, 2024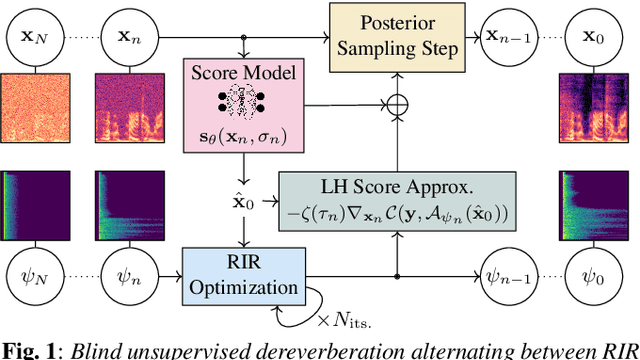
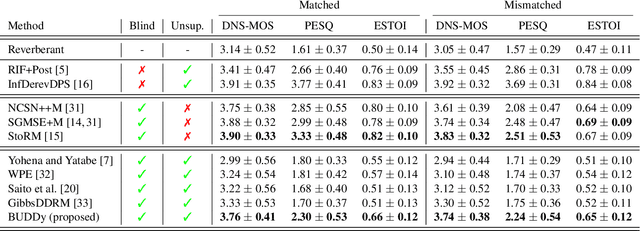
In this paper, we present an unsupervised single-channel method for joint blind dereverberation and room impulse response estimation, based on posterior sampling with diffusion models. We parameterize the reverberation operator using a filter with exponential decay for each frequency subband, and iteratively estimate the corresponding parameters as the speech utterance gets refined along the reverse diffusion trajectory. A measurement consistency criterion enforces the fidelity of the generated speech with the reverberant measurement, while an unconditional diffusion model implements a strong prior for clean speech generation. Without any knowledge of the room impulse response nor any coupled reverberant-anechoic data, we can successfully perform dereverberation in various acoustic scenarios. Our method significantly outperforms previous blind unsupervised baselines, and we demonstrate its increased robustness to unseen acoustic conditions in comparison to blind supervised methods. Audio samples and code are available online.