 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeNon-intrusive Speech Quality Assessment with Diffusion Models Trained on Clean Speech
Oct 23, 2024



Diffusion models have found great success in generating high quality, natural samples of speech, but their potential for density estimation for speech has so far remained largely unexplored. In this work, we leverage an unconditional diffusion model trained only on clean speech for the assessment of speech quality. We show that the quality of a speech utterance can be assessed by estimating the likelihood of a corresponding sample in the terminating Gaussian distribution, obtained via a deterministic noising process. The resulting method is purely unsupervised, trained only on clean speech, and therefore does not rely on annotations. Our diffusion-based approach leverages clean speech priors to assess quality based on how the input relates to the learned distribution of clean data. Our proposed log-likelihoods show promising results, correlating well with intrusive speech quality metrics such as POLQA and SI-SDR.
HRTF Estimation using a Score-based Prior
Oct 02, 2024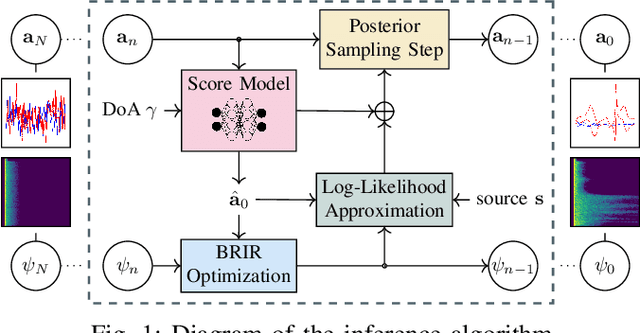
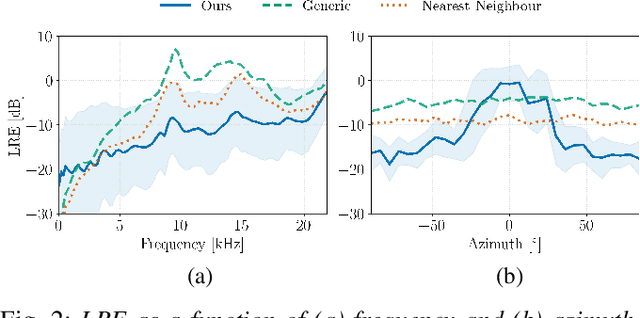
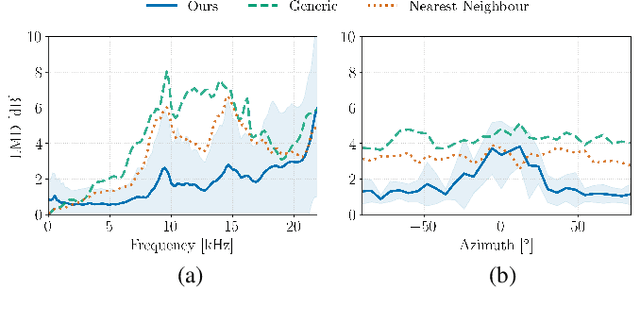

We present a head-related transfer function (HRTF) estimation method which relies on a data-driven prior given by a score-based diffusion model. The HRTF is estimated in reverberant environments using natural excitation signals, e.g. human speech. The impulse response of the room is estimated along with the HRTF by optimizing a parametric model of reverberation based on the statistical behaviour of room acoustics. The posterior distribution of HRTF given the reverberant measurement and excitation signal is modelled using the score-based HRTF prior and a log-likelihood approximation. We show that the resulting method outperforms several baselines, including an oracle recommender system that assigns the optimal HRTF in our training set based on the smallest distance to the true HRTF at the given direction of arrival. In particular, we show that the diffusion prior can account for the large variability of high-frequency content in HRTFs.
Unsupervised Blind Joint Dereverberation and Room Acoustics Estimation with Diffusion Models
Aug 14, 2024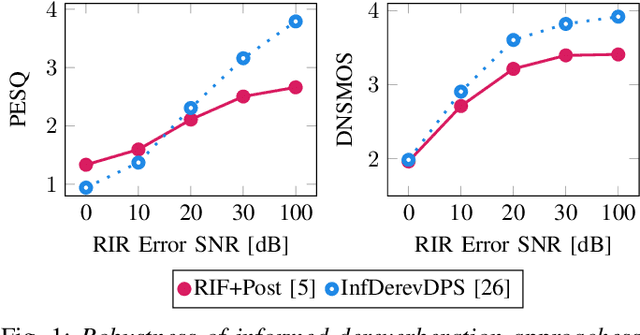
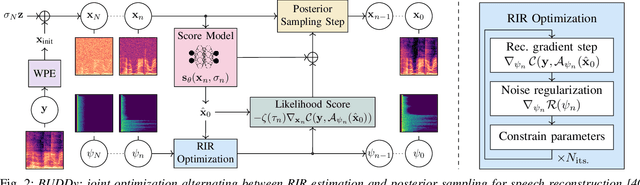
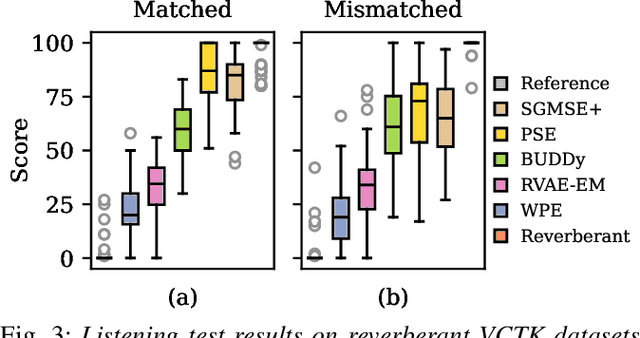
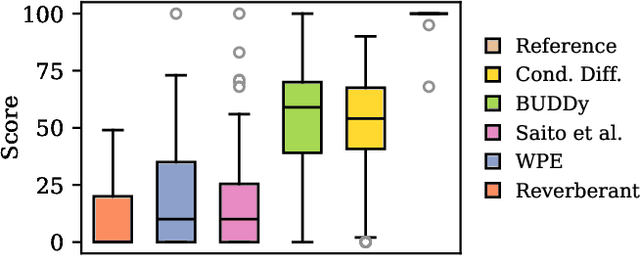
This paper presents an unsupervised method for single-channel blind dereverberation and room impulse response (RIR) estimation, called BUDDy. The algorithm is rooted in Bayesian posterior sampling: it combines a likelihood model enforcing fidelity to the reverberant measurement, and an anechoic speech prior implemented by an unconditional diffusion model. We design a parametric filter representing the RIR, with exponential decay for each frequency subband. Room acoustics estimation and speech dereverberation are jointly carried out, as the filter parameters are iteratively estimated and the speech utterance refined along the reverse diffusion trajectory. In a blind scenario where the room impulse response is unknown, BUDDy successfully performs speech dereverberation in various acoustic scenarios, significantly outperforming other blind unsupervised baselines. Unlike supervised methods, which often struggle to generalize, BUDDy seamlessly adapts to different acoustic conditions. This paper extends our previous work by offering new experimental results and insights into the algorithm's performance and versatility. We first investigate the robustness of informed dereverberation methods to RIR estimation errors, to motivate the joint acoustic estimation and dereverberation paradigm. Then, we demonstrate the adaptability of our method to high-resolution singing voice dereverberation, study its performance in RIR estimation, and conduct subjective evaluation experiments to validate the perceptual quality of the results, among other contributions. Audio samples and code can be found online.
An Independence-promoting Loss for Music Generation with Language Models
Jun 04, 2024Music generation schemes using language modeling rely on a vocabulary of audio tokens, generally provided as codes in a discrete latent space learnt by an auto-encoder. Multi-stage quantizers are often employed to produce these tokens, therefore the decoding strategy used for token prediction must be adapted to account for multiple codebooks: either it should model the joint distribution over all codebooks, or fit the product of the codebook marginal distributions. Modelling the joint distribution requires a costly increase in the number of auto-regressive steps, while fitting the product of the marginals yields an inexact model unless the codebooks are mutually independent. In this work, we introduce an independence-promoting loss to regularize the auto-encoder used as the tokenizer in language models for music generation. The proposed loss is a proxy for mutual information based on the maximum mean discrepancy principle, applied in reproducible kernel Hilbert spaces. Our criterion is simple to implement and train, and it is generalizable to other multi-stream codecs. We show that it reduces the statistical dependence between codebooks during auto-encoding. This leads to an increase in the generated music quality when modelling the product of the marginal distributions, while generating audio much faster than the joint distribution model.
BUDDy: Single-Channel Blind Unsupervised Dereverberation with Diffusion Models
May 07, 2024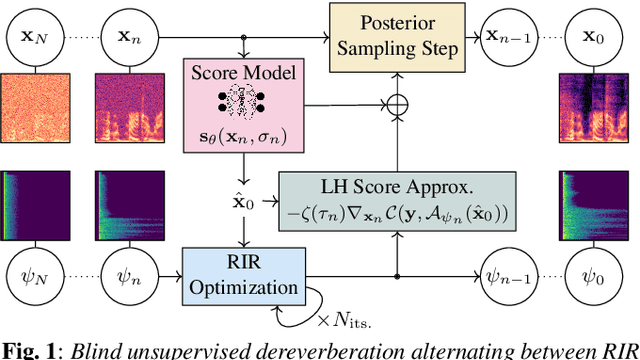
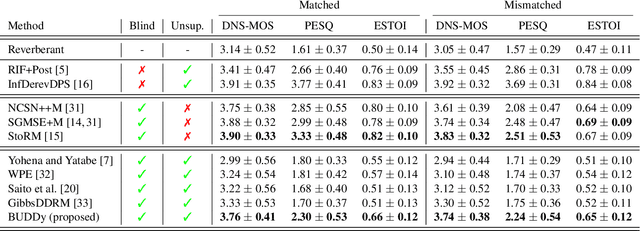
In this paper, we present an unsupervised single-channel method for joint blind dereverberation and room impulse response estimation, based on posterior sampling with diffusion models. We parameterize the reverberation operator using a filter with exponential decay for each frequency subband, and iteratively estimate the corresponding parameters as the speech utterance gets refined along the reverse diffusion trajectory. A measurement consistency criterion enforces the fidelity of the generated speech with the reverberant measurement, while an unconditional diffusion model implements a strong prior for clean speech generation. Without any knowledge of the room impulse response nor any coupled reverberant-anechoic data, we can successfully perform dereverberation in various acoustic scenarios. Our method significantly outperforms previous blind unsupervised baselines, and we demonstrate its increased robustness to unseen acoustic conditions in comparison to blind supervised methods. Audio samples and code are available online.
Diffusion Models for Audio Restoration
Feb 15, 2024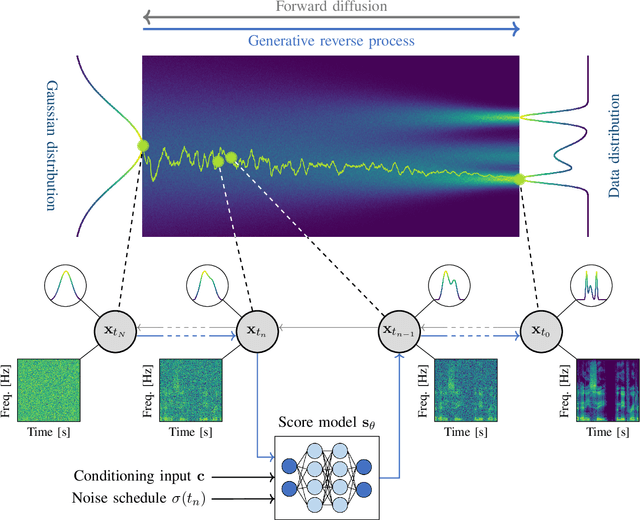
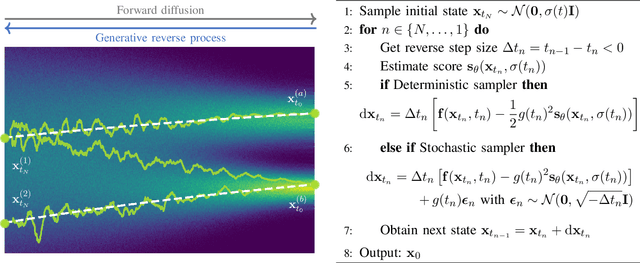
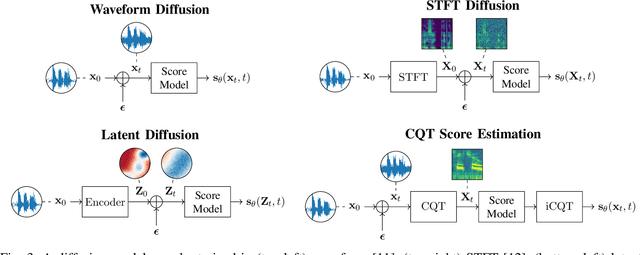
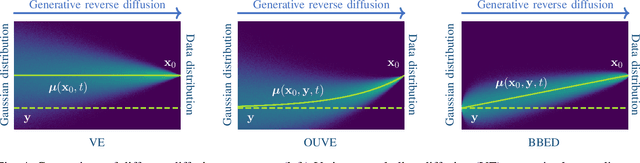
With the development of audio playback devices and fast data transmission, the demand for high sound quality is rising, for both entertainment and communications. In this quest for better sound quality, challenges emerge from distortions and interferences originating at the recording side or caused by an imperfect transmission pipeline. To address this problem, audio restoration methods aim to recover clean sound signals from the corrupted input data. We present here audio restoration algorithms based on diffusion models, with a focus on speech enhancement and music restoration tasks. Traditional approaches, often grounded in handcrafted rules and statistical heuristics, have shaped our understanding of audio signals. In the past decades, there has been a notable shift towards data-driven methods that exploit the modeling capabilities of deep neural networks (DNNs). Deep generative models, and among them diffusion models, have emerged as powerful techniques for learning complex data distributions. However, relying solely on DNN-based learning approaches carries the risk of reducing interpretability, particularly when employing end-to-end models. Nonetheless, data-driven approaches allow more flexibility in comparison to statistical model-based frameworks whose performance depends on distributional and statistical assumptions that can be difficult to guarantee. Here, we aim to show that diffusion models can combine the best of both worlds and offer the opportunity to design audio restoration algorithms with a good degree of interpretability and a remarkable performance in terms of sound quality.
Single and Few-step Diffusion for Generative Speech Enhancement
Sep 18, 2023

Diffusion models have shown promising results in speech enhancement, using a task-adapted diffusion process for the conditional generation of clean speech given a noisy mixture. However, at test time, the neural network used for score estimation is called multiple times to solve the iterative reverse process. This results in a slow inference process and causes discretization errors that accumulate over the sampling trajectory. In this paper, we address these limitations through a two-stage training approach. In the first stage, we train the diffusion model the usual way using the generative denoising score matching loss. In the second stage, we compute the enhanced signal by solving the reverse process and compare the resulting estimate to the clean speech target using a predictive loss. We show that using this second training stage enables achieving the same performance as the baseline model using only 5 function evaluations instead of 60 function evaluations. While the performance of usual generative diffusion algorithms drops dramatically when lowering the number of function evaluations (NFEs) to obtain single-step diffusion, we show that our proposed method keeps a steady performance and therefore largely outperforms the diffusion baseline in this setting and also generalizes better than its predictive counterpart.
Wind Noise Reduction with a Diffusion-based Stochastic Regeneration Model
Jun 22, 2023



In this paper we present a method for single-channel wind noise reduction using our previously proposed diffusion-based stochastic regeneration model combining predictive and generative modelling. We introduce a non-additive speech in noise model to account for the non-linear deformation of the membrane caused by the wind flow and possible clipping. We show that our stochastic regeneration model outperforms other neural-network-based wind noise reduction methods as well as purely predictive and generative models, on a dataset using simulated and real-recorded wind noise. We further show that the proposed method generalizes well by testing on an unseen dataset with real-recorded wind noise. Audio samples, data generation scripts and code for the proposed methods can be found online (https://uhh.de/inf-sp-storm-wind).
Diffusion Posterior Sampling for Informed Single-Channel Dereverberation
Jun 21, 2023

We present in this paper an informed single-channel dereverberation method based on conditional generation with diffusion models. With knowledge of the room impulse response, the anechoic utterance is generated via reverse diffusion using a measurement consistency criterion coupled with a neural network that represents the clean speech prior. The proposed approach is largely more robust to measurement noise compared to a state-of-the-art informed single-channel dereverberation method, especially for non-stationary noise. Furthermore, we compare to other blind dereverberation methods using diffusion models and show superiority of the proposed approach for large reverberation times. We motivate the presented algorithm by introducing an extension for blind dereverberation allowing joint estimation of the room impulse response and anechoic speech. Audio samples and code can be found online (https://uhh.de/inf-sp-derev-dps).
On the Behavior of Intrusive and Non-intrusive Speech Enhancement Metrics in Predictive and Generative Settings
Jun 05, 2023Since its inception, the field of deep speech enhancement has been dominated by predictive (discriminative) approaches, such as spectral mapping or masking. Recently, however, novel generative approaches have been applied to speech enhancement, attaining good denoising performance with high subjective quality scores. At the same time, advances in deep learning also allowed for the creation of neural network-based metrics, which have desirable traits such as being able to work without a reference (non-intrusively). Since generatively enhanced speech tends to exhibit radically different residual distortions, its evaluation using instrumental speech metrics may behave differently compared to predictively enhanced speech. In this paper, we evaluate the performance of the same speech enhancement backbone trained under predictive and generative paradigms on a variety of metrics and show that intrusive and non-intrusive measures correlate differently for each paradigm. This analysis motivates the search for metrics that can together paint a complete and unbiased picture of speech enhancement performance, irrespective of the model's training process.