 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSolving Room Impulse Response Inverse Problems Using Flow Matching with Analytic Wiener Denoiser
Jan 31, 2026Room impulse response (RIR) estimation naturally arises as a class of inverse problems, including denoising and deconvolution. While recent approaches often rely on supervised learning or learned generative priors, such methods require large amounts of training data and may generalize poorly outside the training distribution. In this work, we present RIRFlow, a training-free Bayesian framework for RIR inverse problems using flow matching. We derive a flow-consistent analytic prior from the statistical structure of RIRs, eliminating the need for data-driven priors. Specifically, we model RIR as a Gaussian process with exponentially decaying variance, which yields a closed-form minimum mean squared error (MMSE) Wiener denoiser. This analytic denoiser is integrated as a prior in an existing flow-based inverse solver, where inverse problems are solved via guided posterior sampling. Furthermore, we extend the solver to nonlinear and non-Gaussian inverse problems via a local Gaussian approximation of the guided posterior, and empirically demonstrate that this approximation remains effective in practice. Experiments on real RIRs across different inverse problems demonstrate robust performance, highlighting the effectiveness of combining a classic RIR model with the recent flow-based generative inference.
Fade-in Reverberation in Multi-room Environments Using the Common-Slope Model
Jul 18, 2024



In multi-room environments, modelling the sound propagation is complex due to the coupling of rooms and diverse source-receiver positions. A common scenario is when the source and the receiver are in different rooms without a clear line of sight. For such source-receiver configurations, an initial increase in energy is observed, referred to as the "fade-in" of reverberation. Based on recent work of representing inhomogeneous and anisotropic reverberation with common decay times, this work proposes an extended parametric model that enables the modelling of the fade-in phenomenon. The method performs fitting on the envelopes, instead of energy decay functions, and allows negative amplitudes of decaying exponentials. We evaluate the method on simulated and measured multi-room environments, where we show that the proposed approach can now model the fade-ins that were unrealisable with the previous method.
Blind Identification of Binaural Room Impulse Responses from Smart Glasses
Mar 28, 2024
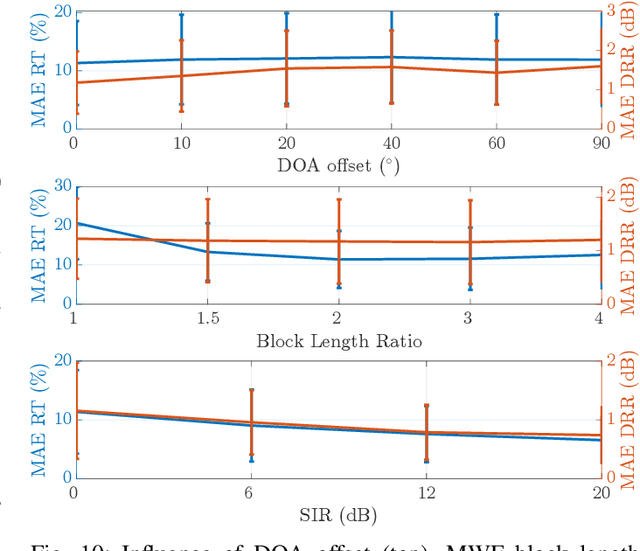
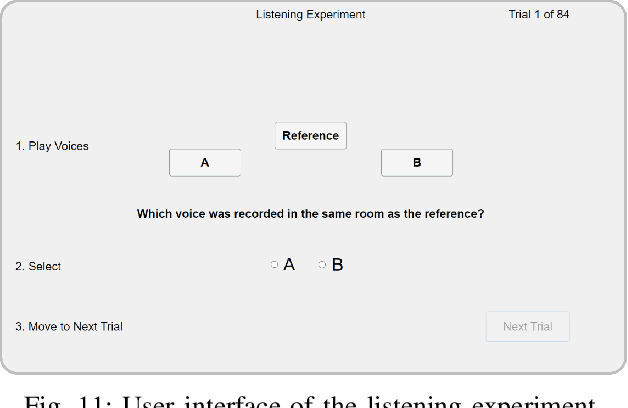
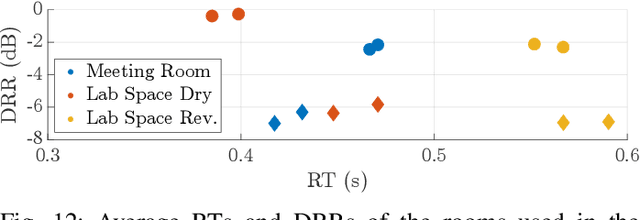
Smart glasses are increasingly recognized as a key medium for augmented reality, offering a hands-free platform with integrated microphones and non-ear-occluding loudspeakers to seamlessly mix virtual sound sources into the real-world acoustic scene. To convincingly integrate virtual sound sources, the room acoustic rendering of the virtual sources must match the real-world acoustics. Information about a user's acoustic environment however is typically not available. This work uses a microphone array in a pair of smart glasses to blindly identify binaural room impulse responses (BRIRs) from a few seconds of speech in the real-world environment. The proposed method uses dereverberation and beamforming to generate a pseudo reference signal that is used by a multichannel Wiener filter to estimate room impulse responses which are then converted to BRIRs. The multichannel room impulse responses can be used to estimate room acoustic parameters which is shown to outperform baseline algorithms in the estimation of reverberation time and direct-to-reverberant energy ratio. Results from a listening experiment further indicate that the estimated BRIRs often reproduce the real-world room acoustics perceptually more convincingly than measured BRIRs from other rooms with similar geometry.
Direction Specific Ambisonics Source Separation with End-To-End Deep Learning
May 19, 2023



Ambisonics is a scene-based spatial audio format that has several useful features compared to object-based formats, such as efficient whole scene rotation and versatility. However, it does not provide direct access to the individual source signals, so that these have to be separated from the mixture when required. Typically, this is done with linear spherical harmonics (SH) beamforming. In this paper, we explore deep-learning-based source separation on static Ambisonics mixtures. In contrast to most source separation approaches, which separate a fixed number of sources of specific sound types, we focus on separating arbitrary sound from specific directions. Specifically, we propose three operating modes that combine a source separation neural network with SH beamforming: refinement, implicit, and mixed mode. We show that a neural network can implicitly associate conditioning directions with the spatial information contained in the Ambisonics scene to extract specific sources. We evaluate the performance of the three proposed approaches and compare them to SH beamforming on musical mixtures generated with the musdb18 dataset, as well as with mixtures generated with the FUSS dataset for universal source separation, under both anechoic and room conditions. Results show that the proposed approaches offer improved separation performance and spatial selectivity compared to conventional SH beamforming.