 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDirection Specific Ambisonics Source Separation with End-To-End Deep Learning
May 19, 2023



Ambisonics is a scene-based spatial audio format that has several useful features compared to object-based formats, such as efficient whole scene rotation and versatility. However, it does not provide direct access to the individual source signals, so that these have to be separated from the mixture when required. Typically, this is done with linear spherical harmonics (SH) beamforming. In this paper, we explore deep-learning-based source separation on static Ambisonics mixtures. In contrast to most source separation approaches, which separate a fixed number of sources of specific sound types, we focus on separating arbitrary sound from specific directions. Specifically, we propose three operating modes that combine a source separation neural network with SH beamforming: refinement, implicit, and mixed mode. We show that a neural network can implicitly associate conditioning directions with the spatial information contained in the Ambisonics scene to extract specific sources. We evaluate the performance of the three proposed approaches and compare them to SH beamforming on musical mixtures generated with the musdb18 dataset, as well as with mixtures generated with the FUSS dataset for universal source separation, under both anechoic and room conditions. Results show that the proposed approaches offer improved separation performance and spatial selectivity compared to conventional SH beamforming.
Points2Sound: From mono to binaural audio using 3D point cloud scenes
Apr 26, 2021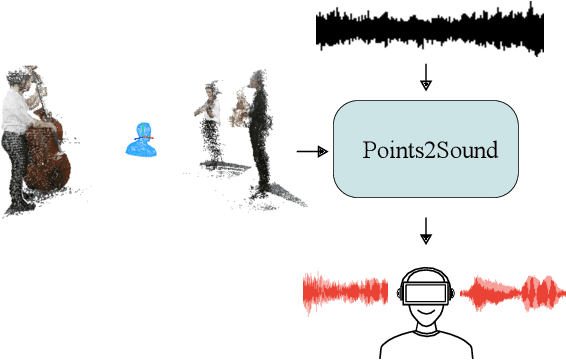
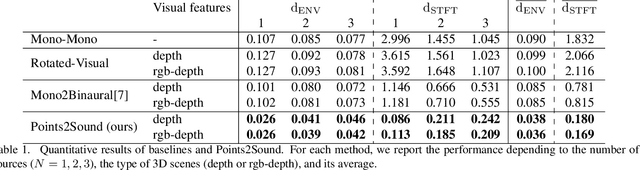
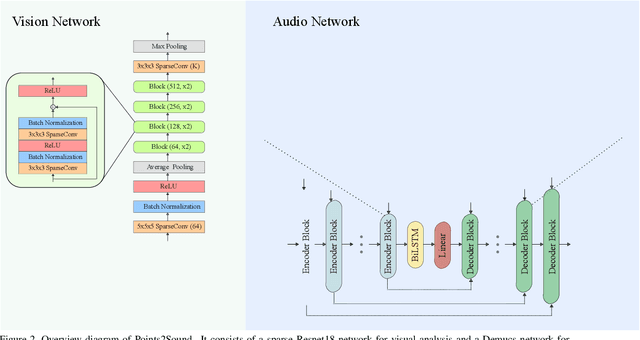
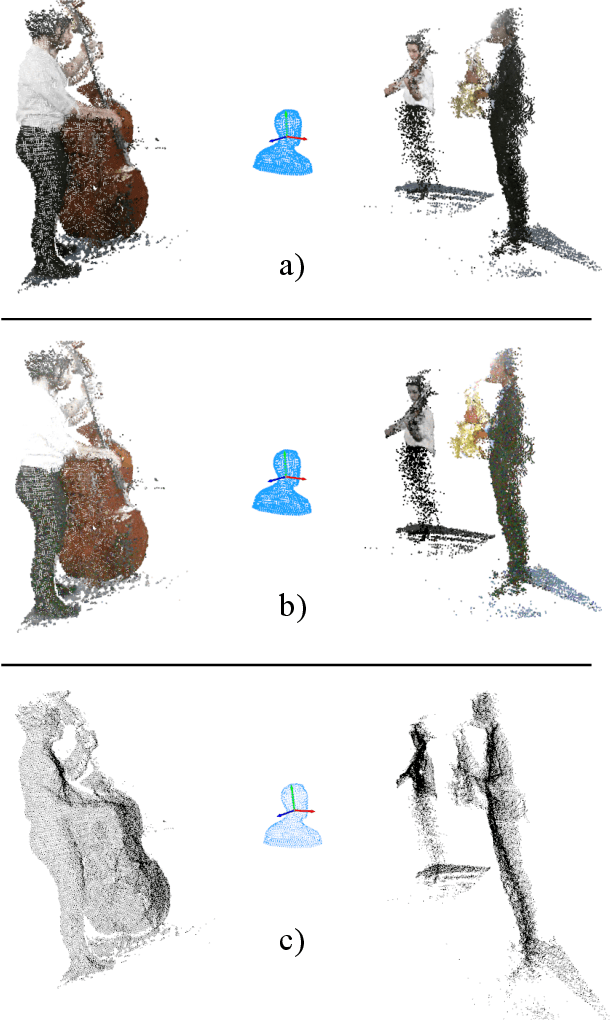
Binaural sound that matches the visual counterpart is crucial to bring meaningful and immersive experiences to people in augmented reality (AR) and virtual reality (VR) applications. Recent works have shown the possibility to generate binaural audio from mono using 2D visual information as guidance. Using 3D visual information may allow for a more accurate representation of a virtual audio scene for VR/AR applications. This paper proposes Points2Sound, a multi-modal deep learning model which generates a binaural version from mono audio using 3D point cloud scenes. Specifically, Points2Sound consist of a vision network which extracts visual features from the point cloud scene to condition an audio network, which operates in the waveform domain, to synthesize the binaural version. Both quantitative and perceptual evaluations indicate that our proposed model is preferred over a reference case, based on a recent 2D mono-to-binaural model.
Music source separation conditioned on 3D point clouds
Feb 03, 2021
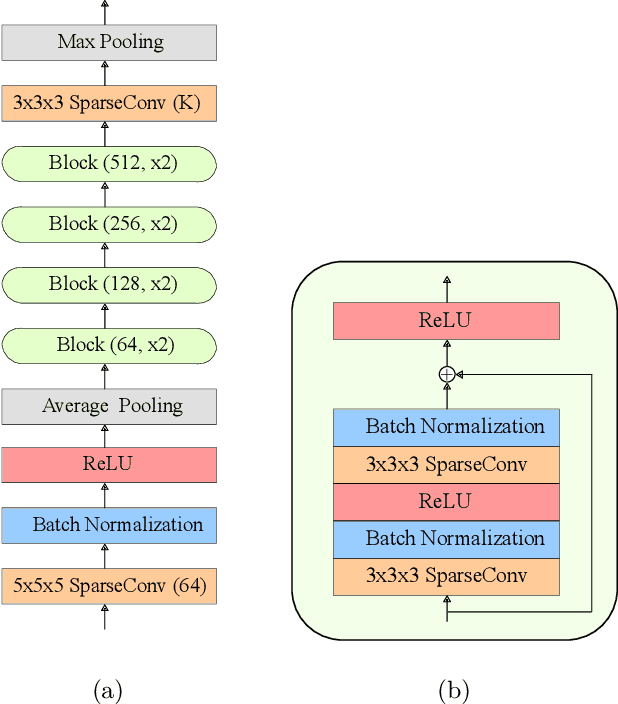
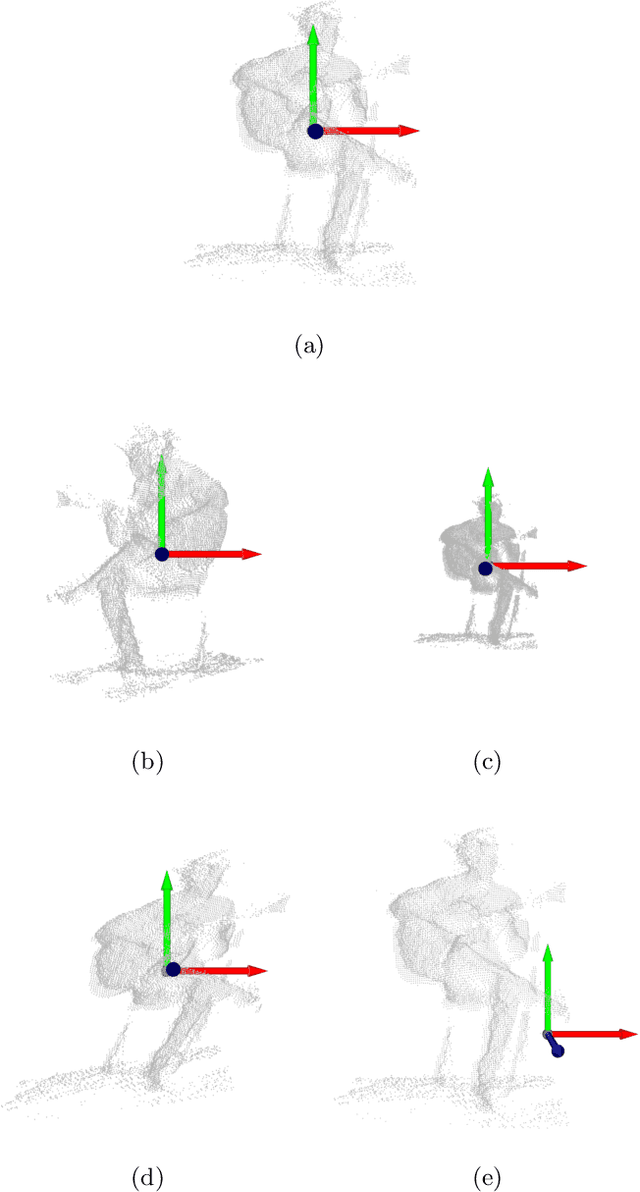

Recently, significant progress has been made in audio source separation by the application of deep learning techniques. Current methods that combine both audio and visual information use 2D representations such as images to guide the separation process. However, in order to (re)-create acoustically correct scenes for 3D virtual/augmented reality applications from recordings of real music ensembles, detailed information about each sound source in the 3D environment is required. This demand, together with the proliferation of 3D visual acquisition systems like LiDAR or rgb-depth cameras, stimulates the creation of models that can guide the audio separation using 3D visual information. This paper proposes a multi-modal deep learning model to perform music source separation conditioned on 3D point clouds of music performance recordings. This model extracts visual features using 3D sparse convolutions, while audio features are extracted using dense convolutions. A fusion module combines the extracted features to finally perform the audio source separation. It is shown, that the presented model can distinguish the musical instruments from a single 3D point cloud frame, and perform source separation qualitatively similar to a reference case, where manually assigned instrument labels are provided.