 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePoints2Sound: From mono to binaural audio using 3D point cloud scenes
Paper and Code
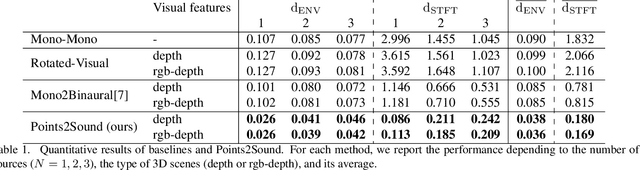
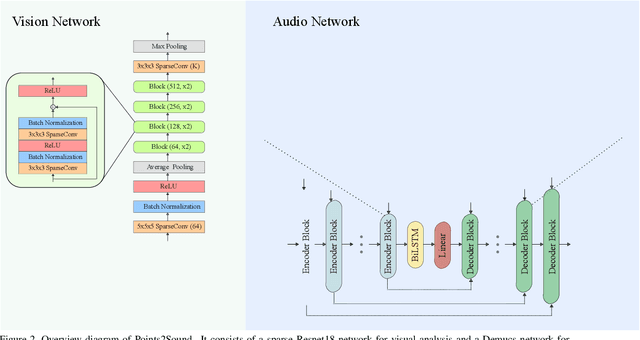
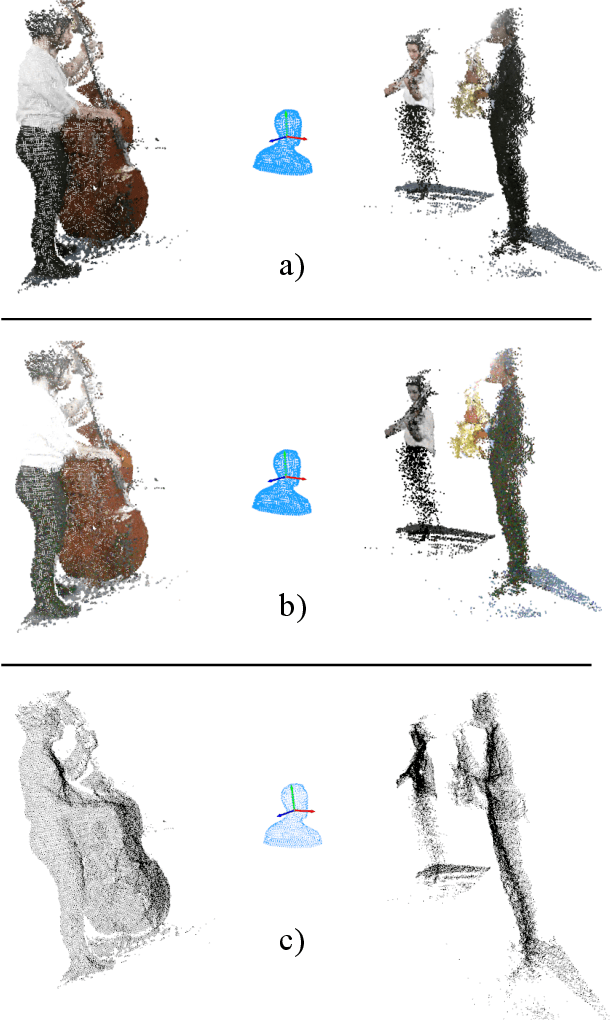
Binaural sound that matches the visual counterpart is crucial to bring meaningful and immersive experiences to people in augmented reality (AR) and virtual reality (VR) applications. Recent works have shown the possibility to generate binaural audio from mono using 2D visual information as guidance. Using 3D visual information may allow for a more accurate representation of a virtual audio scene for VR/AR applications. This paper proposes Points2Sound, a multi-modal deep learning model which generates a binaural version from mono audio using 3D point cloud scenes. Specifically, Points2Sound consist of a vision network which extracts visual features from the point cloud scene to condition an audio network, which operates in the waveform domain, to synthesize the binaural version. Both quantitative and perceptual evaluations indicate that our proposed model is preferred over a reference case, based on a recent 2D mono-to-binaural model.