 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAliasing-Free Neural Audio Synthesis
Dec 23, 2025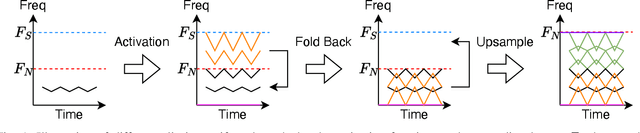
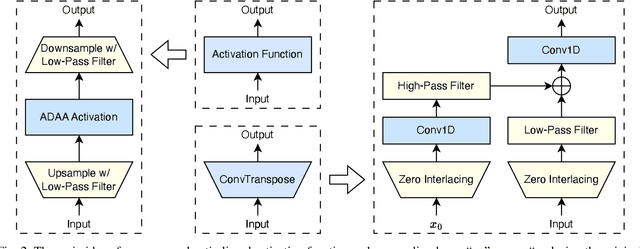
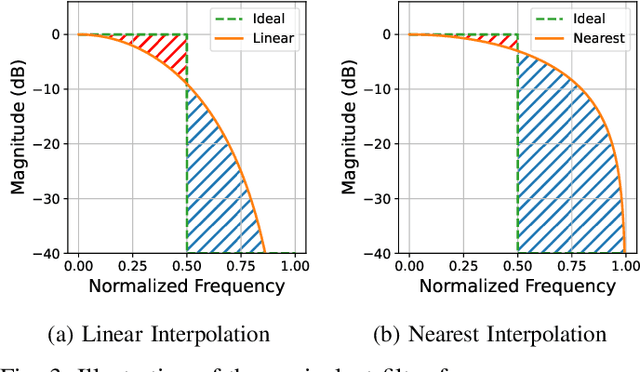
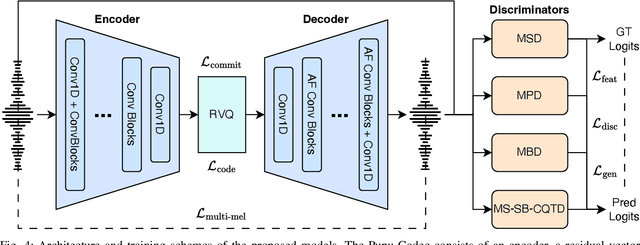
Neural vocoders and codecs reconstruct waveforms from acoustic representations, which directly impact the audio quality. Among existing methods, upsampling-based time-domain models are superior in both inference speed and synthesis quality, achieving state-of-the-art performance. Still, despite their success in producing perceptually natural sound, their synthesis fidelity remains limited due to the aliasing artifacts brought by the inadequately designed model architectures. In particular, the unconstrained nonlinear activation generates an infinite number of harmonics that exceed the Nyquist frequency, resulting in ``folded-back'' aliasing artifacts. The widely used upsampling layer, ConvTranspose, copies the mirrored low-frequency parts to fill the empty high-frequency region, resulting in ``mirrored'' aliasing artifacts. Meanwhile, the combination of its inherent periodicity and the mirrored DC bias also brings ``tonal artifact,'' resulting in constant-frequency ringing. This paper aims to solve these issues from a signal processing perspective. Specifically, we apply oversampling and anti-derivative anti-aliasing to the activation function to obtain its anti-aliased form, and replace the problematic ConvTranspose layer with resampling to avoid the ``tonal artifact'' and eliminate aliased components. Based on our proposed anti-aliased modules, we introduce Pupu-Vocoder and Pupu-Codec, and release high-quality pre-trained checkpoints to facilitate audio generation research. We build a test signal benchmark to illustrate the effectiveness of the anti-aliased modules, and conduct experiments on speech, singing voice, music, and audio to validate our proposed models. Experimental results confirm that our lightweight Pupu-Vocoder and Pupu-Codec models can easily outperform existing systems on singing voice, music, and audio, while achieving comparable performance on speech.
De-crackling Virtual Analog Controls with Asymptotically Stable Recurrent Neural Networks
Sep 19, 2025Recurrent neural networks are used in virtual analog modeling applications to digitally replicate the sound of analog hardware audio processors. The controls of hardware devices can be used as a conditioning input to these networks. A common method for introducing control conditioning to these models is the direct static concatenation of controls with input audio samples, which we show produces audio artifacts under time-varied conditioning. Here we derive constraints for asymptotically stable variants of commonly used recurrent neural networks and demonstrate that asymptotical stability in recurrent neural networks can eliminate audio artifacts from the model output under zero input and time-varied conditioning. Furthermore, our results suggest a possible general solution to mitigate conditioning-induced artifacts in other audio neural network architectures, such as convolutional and state-space models.
Pronunciation Editing for Finnish Speech using Phonetic Posteriorgrams
Jul 02, 2025Synthesizing second-language (L2) speech is potentially highly valued for L2 language learning experience and feedback. However, due to the lack of L2 speech synthesis datasets, it is difficult to synthesize L2 speech for low-resourced languages. In this paper, we provide a practical solution for editing native speech to approximate L2 speech and present PPG2Speech, a diffusion-based multispeaker Phonetic-Posteriorgrams-to-Speech model that is capable of editing a single phoneme without text alignment. We use Matcha-TTS's flow-matching decoder as the backbone, transforming Phonetic Posteriorgrams (PPGs) to mel-spectrograms conditioned on external speaker embeddings and pitch. PPG2Speech strengthens the Matcha-TTS's flow-matching decoder with Classifier-free Guidance (CFG) and Sway Sampling. We also propose a new task-specific objective evaluation metric, the Phonetic Aligned Consistency (PAC), between the edited PPGs and the PPGs extracted from the synthetic speech for editing effects. We validate the effectiveness of our method on Finnish, a low-resourced, nearly phonetic language, using approximately 60 hours of data. We conduct objective and subjective evaluations of our approach to compare its naturalness, speaker similarity, and editing effectiveness with TTS-based editing. Our source code is published at https://github.com/aalto-speech/PPG2Speech.
Neurodyne: Neural Pitch Manipulation with Representation Learning and Cycle-Consistency GAN
May 21, 2025Pitch manipulation is the process of producers adjusting the pitch of an audio segment to a specific key and intonation, which is essential in music production. Neural-network-based pitch-manipulation systems have been popular in recent years due to their superior synthesis quality compared to classical DSP methods. However, their performance is still limited due to their inaccurate feature disentanglement using source-filter models and the lack of paired in- and out-of-tune training data. This work proposes Neurodyne to address these issues. Specifically, Neurodyne uses adversarial representation learning to learn a pitch-independent latent representation to avoid inaccurate disentanglement and cycle-consistency training to create paired training data implicitly. Experimental results on global-key and template-based pitch manipulation demonstrate the effectiveness of the proposed system, marking improved synthesis quality while maintaining the original singer identity.
Unsupervised Estimation of Nonlinear Audio Effects: Comparing Diffusion-Based and Adversarial approaches
Apr 07, 2025Accurately estimating nonlinear audio effects without access to paired input-output signals remains a challenging problem.This work studies unsupervised probabilistic approaches for solving this task. We introduce a method, novel for this application, based on diffusion generative models for blind system identification, enabling the estimation of unknown nonlinear effects using black- and gray-box models. This study compares this method with a previously proposed adversarial approach, analyzing the performance of both methods under different parameterizations of the effect operator and varying lengths of available effected recordings.Through experiments on guitar distortion effects, we show that the diffusion-based approach provides more stable results and is less sensitive to data availability, while the adversarial approach is superior at estimating more pronounced distortion effects. Our findings contribute to the robust unsupervised blind estimation of audio effects, demonstrating the potential of diffusion models for system identification in music technology.
Diff-SSL-G-Comp: Towards a Large-Scale and Diverse Dataset for Virtual Analog Modeling
Apr 06, 2025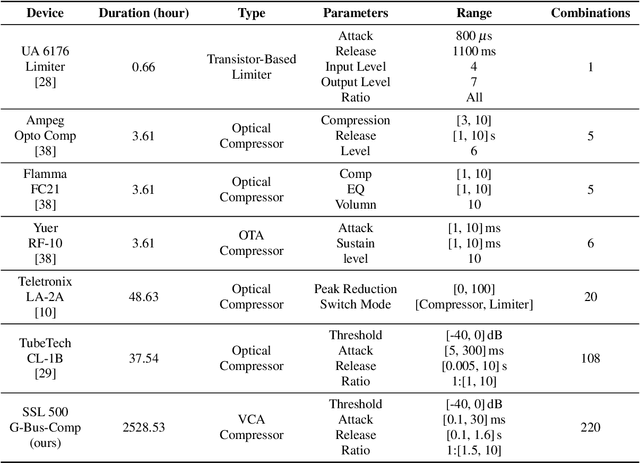
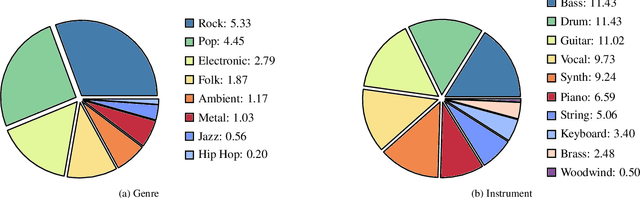
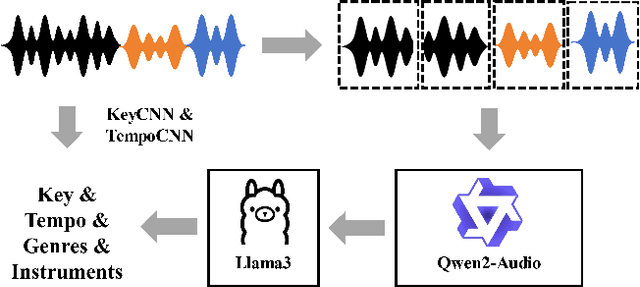
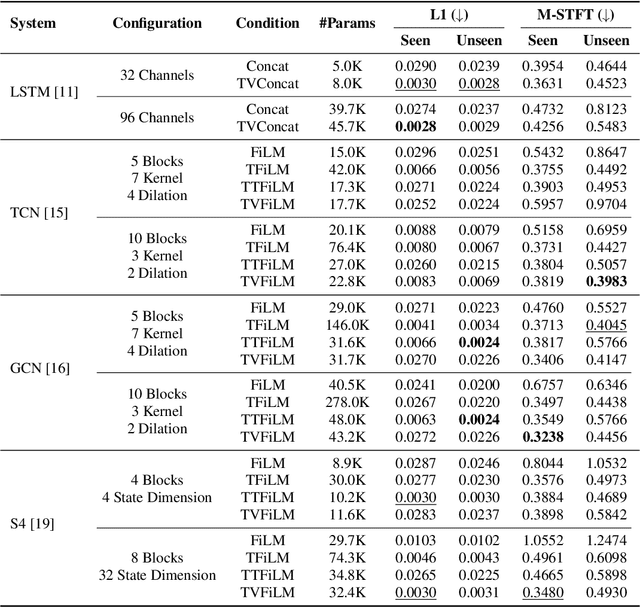
Virtual Analog (VA) modeling aims to simulate the behavior of hardware circuits via algorithms to replicate their tone digitally. Dynamic Range Compressor (DRC) is an audio processing module that controls the dynamics of a track by reducing and amplifying the volumes of loud and quiet sounds, which is essential in music production. In recent years, neural-network-based VA modeling has shown great potential in producing high-fidelity models. However, due to the lack of data quantity and diversity, their generalization ability in different parameter settings and input sounds is still limited. To tackle this problem, we present Diff-SSL-G-Comp, the first large-scale and diverse dataset for modeling the SSL 500 G-Bus Compressor. Specifically, we manually collected 175 unmastered songs from the Cambridge Multitrack Library. We recorded the compressed audio in 220 parameter combinations, resulting in an extensive 2528-hour dataset with diverse genres, instruments, tempos, and keys. Moreover, to facilitate the use of our proposed dataset, we conducted benchmark experiments in various open-sourced black-box and grey-box models, as well as white-box plugins. We also conducted ablation studies in different data subsets to illustrate the effectiveness of improved data diversity and quantity. The dataset and demos are on our project page: http://www.yichenggu.com/DiffSSLGComp/.
Estimation and Restoration of Unknown Nonlinear Distortion using Diffusion
Jan 10, 2025The restoration of nonlinearly distorted audio signals, alongside the identification of the applied memoryless nonlinear operation, is studied. The paper focuses on the difficult but practically important case in which both the nonlinearity and the original input signal are unknown. The proposed method uses a generative diffusion model trained unconditionally on guitar or speech signals to jointly model and invert the nonlinear system at inference time. Both the memoryless nonlinear function model and the restored audio signal are obtained as output. Successful example case studies are presented including inversion of hard and soft clipping, digital quantization, half-wave rectification, and wavefolding nonlinearities. Our results suggest that, out of the nonlinear functions tested here, the cubic Catmull-Rom spline is best suited to approximating these nonlinearities. In the case of guitar recordings, comparisons with informed and supervised methods show that the proposed blind method is at least as good as they are in terms of objective metrics. Experiments on distorted speech show that the proposed blind method outperforms general-purpose speech enhancement techniques and restores the original voice quality. The proposed method can be applied to audio effects modeling, restoration of music and speech recordings, and characterization of analog recording media.
Open-Amp: Synthetic Data Framework for Audio Effect Foundation Models
Nov 22, 2024This paper introduces Open-Amp, a synthetic data framework for generating large-scale and diverse audio effects data. Audio effects are relevant to many musical audio processing and Music Information Retrieval (MIR) tasks, such as modelling of analog audio effects, automatic mixing, tone matching and transcription. Existing audio effects datasets are limited in scope, usually including relatively few audio effects processors and a limited amount of input audio signals. Our proposed framework overcomes these issues, by crowdsourcing neural network emulations of guitar amplifiers and effects, created by users of open-source audio effects emulation software. This allows users of Open-Amp complete control over the input signals to be processed by the effects models, as well as providing high-quality emulations of hundreds of devices. Open-Amp can render audio online during training, allowing great flexibility in data augmentation. Our experiments show that using Open-Amp to train a guitar effects encoder achieves new state-of-the-art results on multiple guitar effects classification tasks. Furthermore, we train a one-to-many guitar effects model using Open-Amp, and use it to emulate unseen analog effects via manipulation of its learned latent space, indicating transferability to analog guitar effects data.
End-to-End Amp Modeling: From Data to Controllable Guitar Amplifier Models
Mar 13, 2024



This paper describes a data-driven approach to creating real-time neural network models of guitar amplifiers, recreating the amplifiers' sonic response to arbitrary inputs at the full range of controls present on the physical device. While the focus on the paper is on the data collection pipeline, we demonstrate the effectiveness of this conditioned black-box approach by training an LSTM model to the task, and comparing its performance to an offline white-box SPICE circuit simulation. Our listening test results demonstrate that the neural amplifier modeling approach can match the subjective performance of a high-quality SPICE model, all while using an automated, non-intrusive data collection process, and an end-to-end trainable, real-time feasible neural network model.
Collaborative Watermarking for Adversarial Speech Synthesis
Sep 26, 2023


Advances in neural speech synthesis have brought us technology that is not only close to human naturalness, but is also capable of instant voice cloning with little data, and is highly accessible with pre-trained models available. Naturally, the potential flood of generated content raises the need for synthetic speech detection and watermarking. Recently, considerable research effort in synthetic speech detection has been related to the Automatic Speaker Verification and Spoofing Countermeasure Challenge (ASVspoof), which focuses on passive countermeasures. This paper takes a complementary view to generated speech detection: a synthesis system should make an active effort to watermark the generated speech in a way that aids detection by another machine, but remains transparent to a human listener. We propose a collaborative training scheme for synthetic speech watermarking and show that a HiFi-GAN neural vocoder collaborating with the ASVspoof 2021 baseline countermeasure models consistently improves detection performance over conventional classifier training. Furthermore, we demonstrate how collaborative training can be paired with augmentation strategies for added robustness against noise and time-stretching. Finally, listening tests demonstrate that collaborative training has little adverse effect on perceptual quality of vocoded speech.