 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEnd-to-End Amp Modeling: From Data to Controllable Guitar Amplifier Models
Mar 13, 2024



This paper describes a data-driven approach to creating real-time neural network models of guitar amplifiers, recreating the amplifiers' sonic response to arbitrary inputs at the full range of controls present on the physical device. While the focus on the paper is on the data collection pipeline, we demonstrate the effectiveness of this conditioned black-box approach by training an LSTM model to the task, and comparing its performance to an offline white-box SPICE circuit simulation. Our listening test results demonstrate that the neural amplifier modeling approach can match the subjective performance of a high-quality SPICE model, all while using an automated, non-intrusive data collection process, and an end-to-end trainable, real-time feasible neural network model.
Conditioned Time-Dilated Convolutions for Sound Event Detection
Jul 10, 2020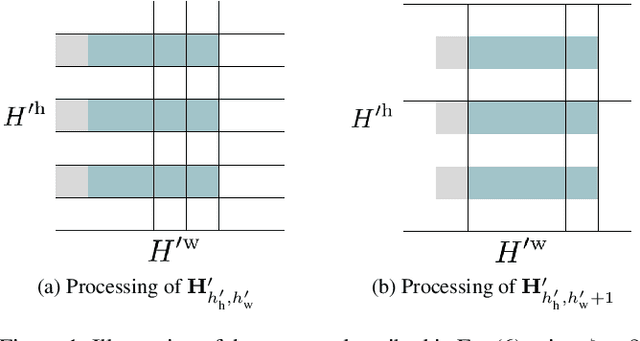
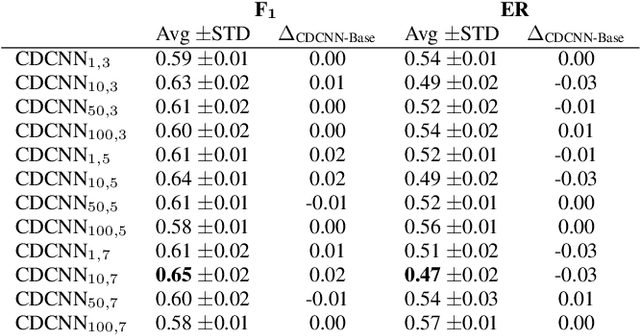
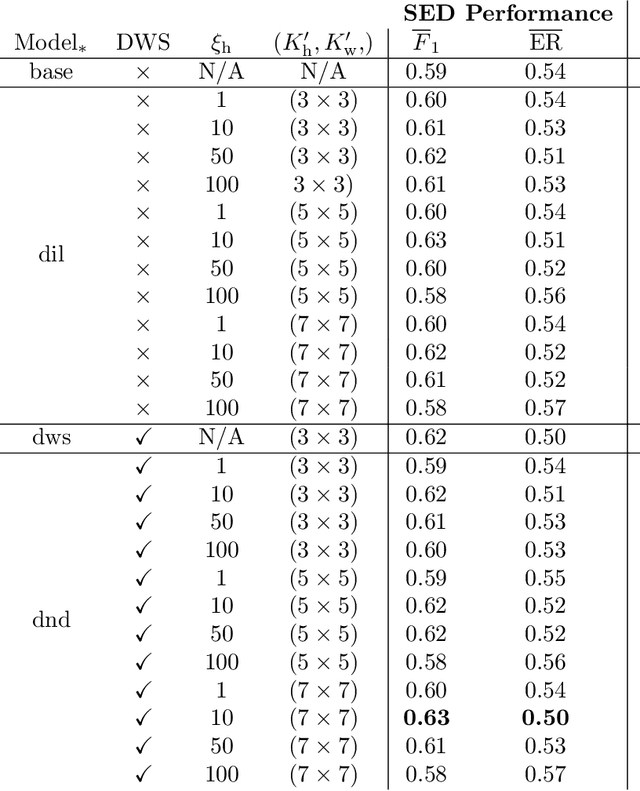
Sound event detection (SED) is the task of identifying sound events along with their onset and offset times. A recent, convolutional neural networks based SED method, proposed the usage of depthwise separable (DWS) and time-dilated convolutions. DWS and time-dilated convolutions yielded state-of-the-art results for SED, with considerable small amount of parameters. In this work we propose the expansion of the time-dilated convolutions, by conditioning them with jointly learned embeddings of the SED predictions by the SED classifier. We present a novel algorithm for the conditioning of the time-dilated convolutions which functions similarly to language modelling, and enhances the performance of the these convolutions. We employ the freely available TUT-SED Synthetic dataset, and we assess the performance of our method using the average per-frame $\text{F}_{1}$ score and average per-frame error rate, over the 10 experiments. We achieve an increase of 2\% (from 0.63 to 0.65) at the average $\text{F}_{1}$ score (the higher the better) and a decrease of 3\% (from 0.50 to 0.47) at the error rate (the lower the better).
Sound Event Detection with Depthwise Separable and Dilated Convolutions
Feb 02, 2020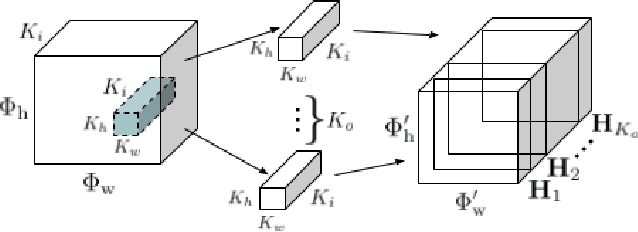
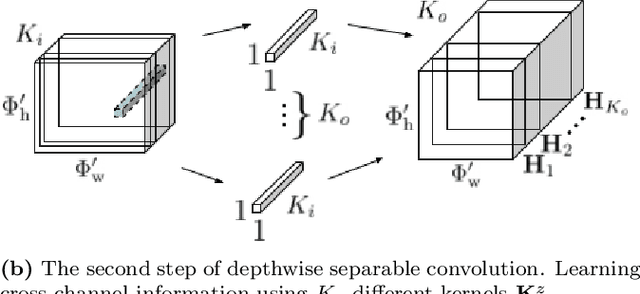

State-of-the-art sound event detection (SED) methods usually employ a series of convolutional neural networks (CNNs) to extract useful features from the input audio signal, and then recurrent neural networks (RNNs) to model longer temporal context in the extracted features. The number of the channels of the CNNs and size of the weight matrices of the RNNs have a direct effect on the total amount of parameters of the SED method, which is to a couple of millions. Additionally, the usually long sequences that are used as an input to an SED method along with the employment of an RNN, introduce implications like increased training time, difficulty at gradient flow, and impeding the parallelization of the SED method. To tackle all these problems, we propose the replacement of the CNNs with depthwise separable convolutions and the replacement of the RNNs with dilated convolutions. We compare the proposed method to a baseline convolutional neural network on a SED task, and achieve a reduction of the amount of parameters by 85% and average training time per epoch by 78%, and an increase the average frame-wise F1 score and reduction of the average error rate by 4.6% and 3.8%, respectively.
SignalTrain: Profiling Audio Compressors with Deep Neural Networks
May 30, 2019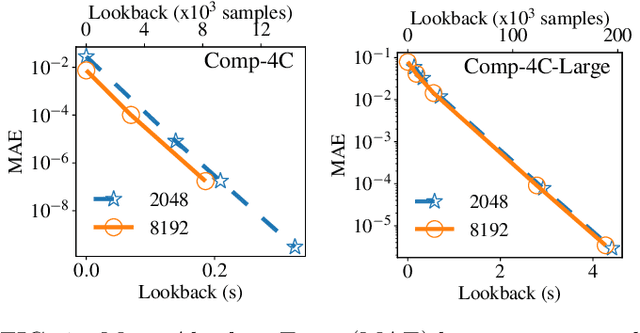
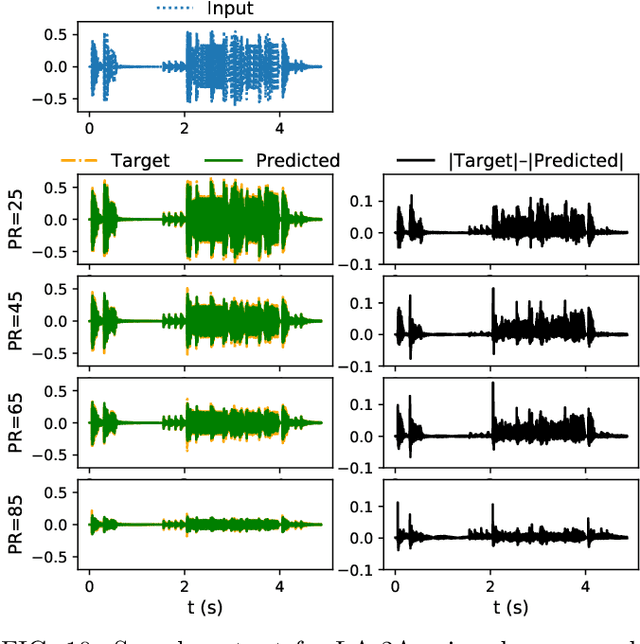
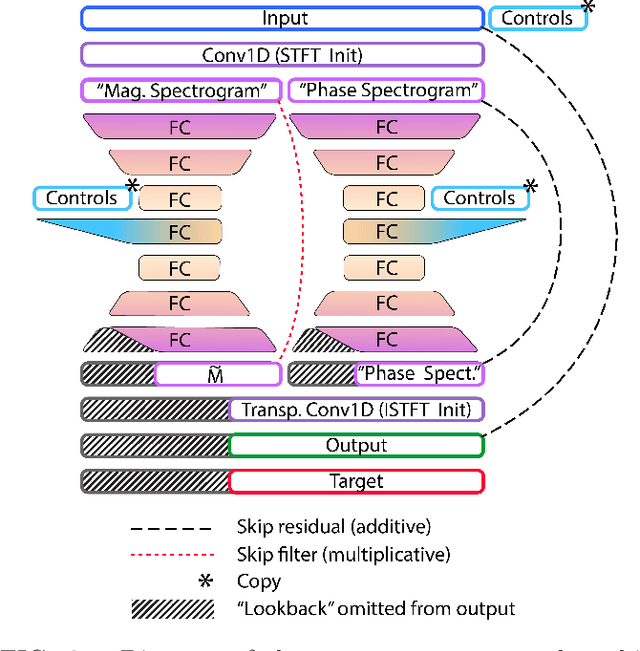
In this work we present a data-driven approach for predicting the behavior of (i.e., profiling) a given non-linear audio signal processing effect (henceforth "audio effect"). Our objective is to learn a mapping function that maps the unprocessed audio to the processed by the audio effect to be profiled, using time-domain samples. To that aim, we employ a deep auto-encoder model that is conditioned on both time-domain samples and the control parameters of the target audio effect. As a test-case study, we focus on the offline profiling of two dynamic range compression audio effects, one software-based and the other analog. Compressors were chosen because they are a widely used and important set of effects and because their parameterized nonlinear time-dependent nature makes them a challenging problem for a system aiming to profile "general" audio effects. Results from our experimental procedure show that the primary functional and auditory characteristics of the compressors can be captured, however there is still sufficient audible noise to merit further investigation before such methods are applied to real-world audio processing workflows.