 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeRepresentation Learning for Audio Privacy Preservation using Source Separation and Robust Adversarial Learning
Aug 09, 2023



Privacy preservation has long been a concern in smart acoustic monitoring systems, where speech can be passively recorded along with a target signal in the system's operating environment. In this study, we propose the integration of two commonly used approaches in privacy preservation: source separation and adversarial representation learning. The proposed system learns the latent representation of audio recordings such that it prevents differentiating between speech and non-speech recordings. Initially, the source separation network filters out some of the privacy-sensitive data, and during the adversarial learning process, the system will learn privacy-preserving representation on the filtered signal. We demonstrate the effectiveness of our proposed method by comparing our method against systems without source separation, without adversarial learning, and without both. Overall, our results suggest that the proposed system can significantly improve speech privacy preservation compared to that of using source separation or adversarial learning solely while maintaining good performance in the acoustic monitoring task.
Adversarial Representation Learning for Robust Privacy Preservation in Audio
Apr 29, 2023Sound event detection systems are widely used in various applications such as surveillance and environmental monitoring where data is automatically collected, processed, and sent to a cloud for sound recognition. However, this process may inadvertently reveal sensitive information about users or their surroundings, hence raising privacy concerns. In this study, we propose a novel adversarial training method for learning representations of audio recordings that effectively prevents the detection of speech activity from the latent features of the recordings. The proposed method trains a model to generate invariant latent representations of speech-containing audio recordings that cannot be distinguished from non-speech recordings by a speech classifier. The novelty of our work is in the optimization algorithm, where the speech classifier's weights are regularly replaced with the weights of classifiers trained in a supervised manner. This increases the discrimination power of the speech classifier constantly during the adversarial training, motivating the model to generate latent representations in which speech is not distinguishable, even using new speech classifiers trained outside the adversarial training loop. The proposed method is evaluated against a baseline approach with no privacy measures and a prior adversarial training method, demonstrating a significant reduction in privacy violations compared to the baseline approach. Additionally, we show that the prior adversarial method is practically ineffective for this purpose.
Sound Event Detection with Depthwise Separable and Dilated Convolutions
Feb 02, 2020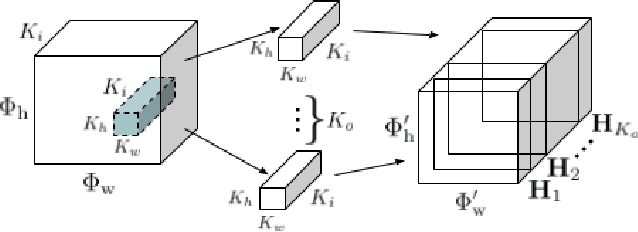
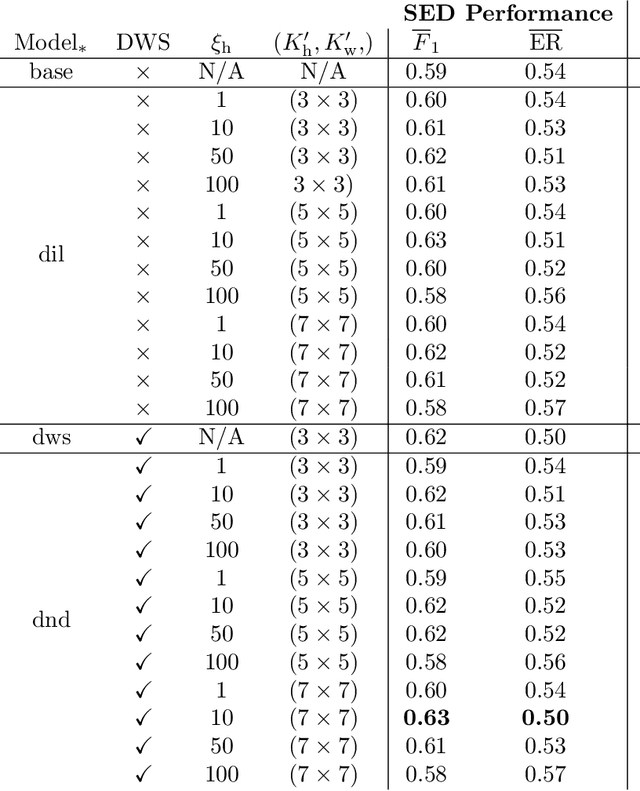
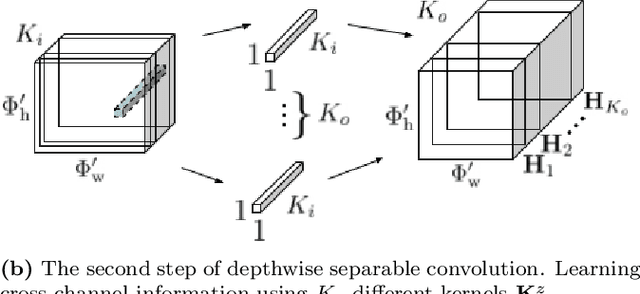

State-of-the-art sound event detection (SED) methods usually employ a series of convolutional neural networks (CNNs) to extract useful features from the input audio signal, and then recurrent neural networks (RNNs) to model longer temporal context in the extracted features. The number of the channels of the CNNs and size of the weight matrices of the RNNs have a direct effect on the total amount of parameters of the SED method, which is to a couple of millions. Additionally, the usually long sequences that are used as an input to an SED method along with the employment of an RNN, introduce implications like increased training time, difficulty at gradient flow, and impeding the parallelization of the SED method. To tackle all these problems, we propose the replacement of the CNNs with depthwise separable convolutions and the replacement of the RNNs with dilated convolutions. We compare the proposed method to a baseline convolutional neural network on a SED task, and achieve a reduction of the amount of parameters by 85% and average training time per epoch by 78%, and an increase the average frame-wise F1 score and reduction of the average error rate by 4.6% and 3.8%, respectively.
Language Modelling for Sound Event Detection with Teacher Forcing and Scheduled Sampling
Jul 22, 2019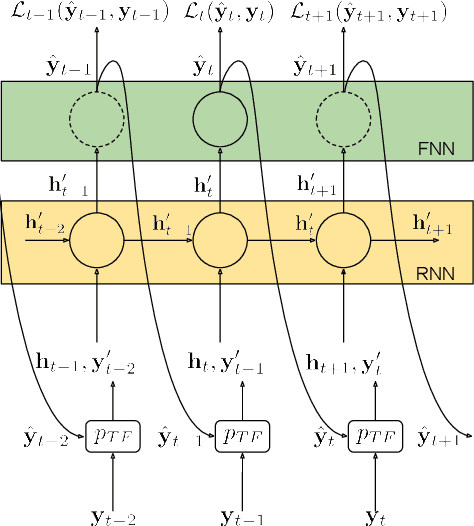
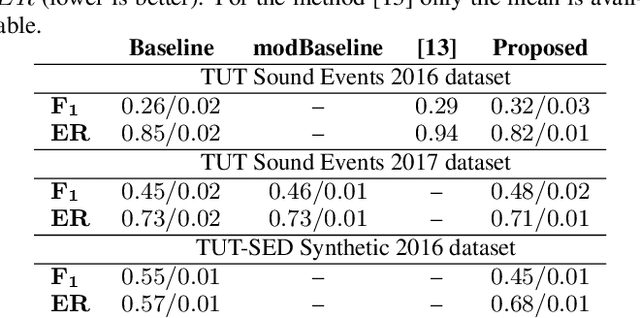
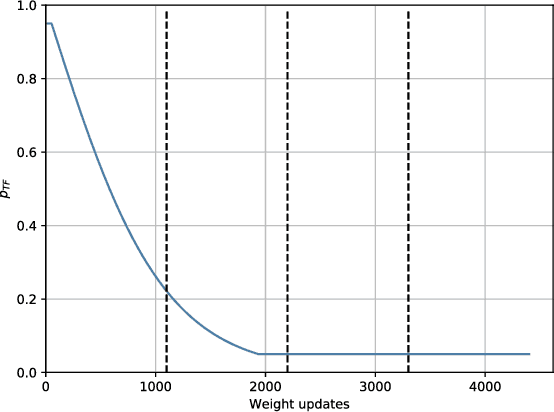
A sound event detection (SED) method typically takes as an input a sequence of audio frames and predicts the activities of sound events in each frame. In real-life recordings, the sound events exhibit some temporal structure: for instance, a "car horn" will likely be followed by a "car passing by". While this temporal structure is widely exploited in sequence prediction tasks (e.g., in machine translation), where language models (LM) are exploited, it is not satisfactorily modeled in SED. In this work we propose a method which allows a recurrent neural network (RNN) to learn an LM for the SED task. The method conditions the input of the RNN with the activities of classes at the previous time step. We evaluate our method using F1 score and error rate (ER) over three different and publicly available datasets; the TUT-SED Synthetic 2016 and the TUT Sound Events 2016 and 2017 datasets. The obtained results show an increase of 6% and 3% at the F1 (higher is better) and a decrease of 3% and 2% at ER (lower is better) for the TUT Sound Events 2016 and 2017 datasets, respectively, when using our method. On the contrary, with our method there is a decrease of 10% at F1 score and an increase of 11% at ER for the TUT-SED Synthetic 2016 dataset.
Unsupervised adversarial domain adaptation for acoustic scene classification
Aug 17, 2018


A general problem in acoustic scene classification task is the mismatched conditions between training and testing data, which significantly reduces the performance of the developed methods on classification accuracy. As a countermeasure, we present the first method of unsupervised adversarial domain adaptation for acoustic scene classification. We employ a model pre-trained on data from one set of conditions and by using data from other set of conditions, we adapt the model in order that its output cannot be used for classifying the set of conditions that input data belong to. We use a freely available dataset from the DCASE 2018 challenge Task 1, subtask B, that contains data from mismatched recording devices. We consider the scenario where the annotations are available for the data recorded from one device, but not for the rest. Our results show that with our model agnostic method we can achieve $\sim 10\%$ increase at the accuracy on an unseen and unlabeled dataset, while keeping almost the same performance on the labeled dataset.
Acoustic Scene Classification: A Competition Review
Aug 02, 2018

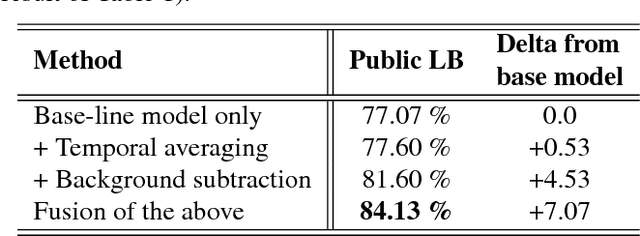
In this paper we study the problem of acoustic scene classification, i.e., categorization of audio sequences into mutually exclusive classes based on their spectral content. We describe the methods and results discovered during a competition organized in the context of a graduate machine learning course; both by the students and external participants. We identify the most suitable methods and study the impact of each by performing an ablation study of the mixture of approaches. We also compare the results with a neural network baseline, and show the improvement over that. Finally, we discuss the impact of using a competition as a part of a university course, and justify its importance in the curriculum based on student feedback.