 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeUSM RNN-T model weights binarization
Jun 06, 2024



Large-scale universal speech models (USM) are already used in production. However, as the model size grows, the serving cost grows too. Serving cost of large models is dominated by model size that is why model size reduction is an important research topic. In this work we are focused on model size reduction using weights only quantization. We present the weights binarization of USM Recurrent Neural Network Transducer (RNN-T) and show that its model size can be reduced by 15.9x times at cost of word error rate (WER) increase by only 1.9% in comparison to the float32 model. It makes it attractive for practical applications.
On Robustness to Missing Video for Audiovisual Speech Recognition
Dec 19, 2023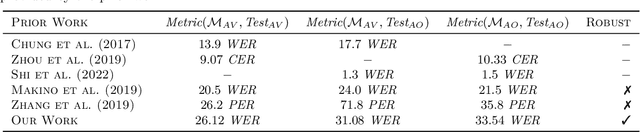
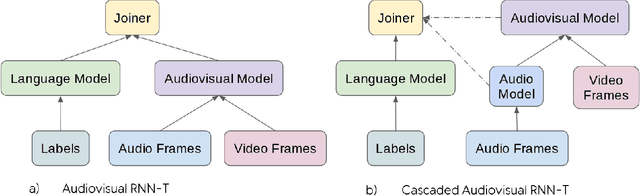
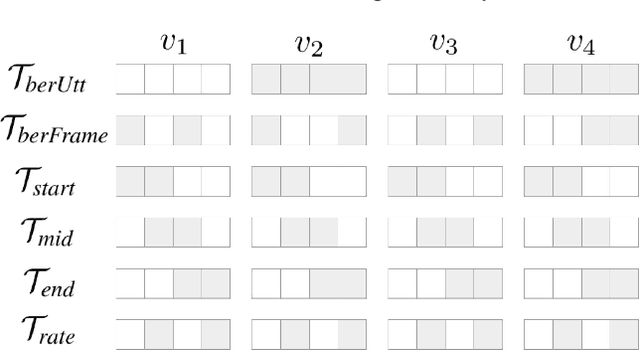
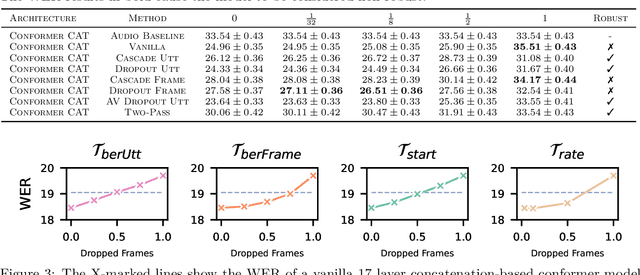
It has been shown that learning audiovisual features can lead to improved speech recognition performance over audio-only features, especially for noisy speech. However, in many common applications, the visual features are partially or entirely missing, e.g.~the speaker might move off screen. Multi-modal models need to be robust: missing video frames should not degrade the performance of an audiovisual model to be worse than that of a single-modality audio-only model. While there have been many attempts at building robust models, there is little consensus on how robustness should be evaluated. To address this, we introduce a framework that allows claims about robustness to be evaluated in a precise and testable way. We also conduct a systematic empirical study of the robustness of common audiovisual speech recognition architectures on a range of acoustic noise conditions and test suites. Finally, we show that an architecture-agnostic solution based on cascades can consistently achieve robustness to missing video, even in settings where existing techniques for robustness like dropout fall short.
Audio-visual fine-tuning of audio-only ASR models
Dec 14, 2023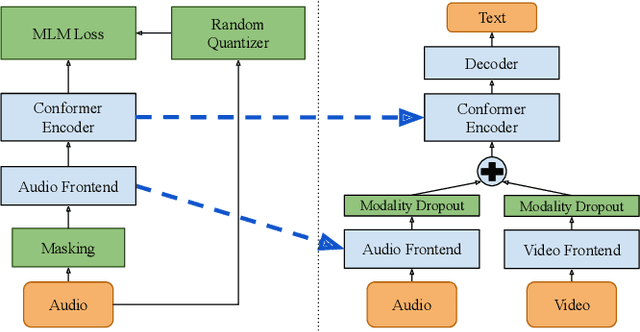
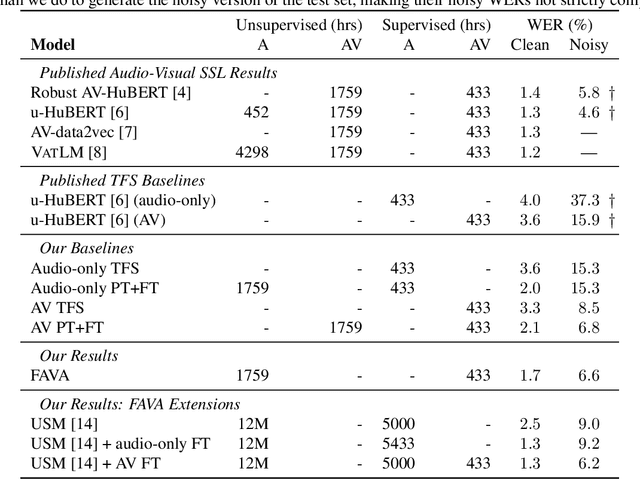

Audio-visual automatic speech recognition (AV-ASR) models are very effective at reducing word error rates on noisy speech, but require large amounts of transcribed AV training data. Recently, audio-visual self-supervised learning (SSL) approaches have been developed to reduce this dependence on transcribed AV data, but these methods are quite complex and computationally expensive. In this work, we propose replacing these expensive AV-SSL methods with a simple and fast \textit{audio-only} SSL method, and then performing AV supervised fine-tuning. We show that this approach is competitive with state-of-the-art (SOTA) AV-SSL methods on the LRS3-TED benchmark task (within 0.5% absolute WER), while being dramatically simpler and more efficient (12-30x faster to pre-train). Furthermore, we show we can extend this approach to convert a SOTA audio-only ASR model into an AV model. By doing so, we match SOTA AV-SSL results, even though no AV data was used during pre-training.
Conformers are All You Need for Visual Speech Recogntion
Feb 17, 2023



Visual speech recognition models extract visual features in a hierarchical manner. At the lower level, there is a visual front-end with a limited temporal receptive field that processes the raw pixels depicting the lips or faces. At the higher level, there is an encoder that attends to the embeddings produced by the front-end over a large temporal receptive field. Previous work has focused on improving the visual front-end of the model to extract more useful features for speech recognition. Surprisingly, our work shows that complex visual front-ends are not necessary. Instead of allocating resources to a sophisticated visual front-end, we find that a linear visual front-end paired with a larger Conformer encoder results in lower latency, more efficient memory usage, and improved WER performance. We achieve a new state-of-the-art of $12.8\%$ WER for visual speech recognition on the TED LRS3 dataset, which rivals the performance of audio-only models from just four years ago.
Transformer-Based Video Front-Ends for Audio-Visual Speech Recognition
Jan 25, 2022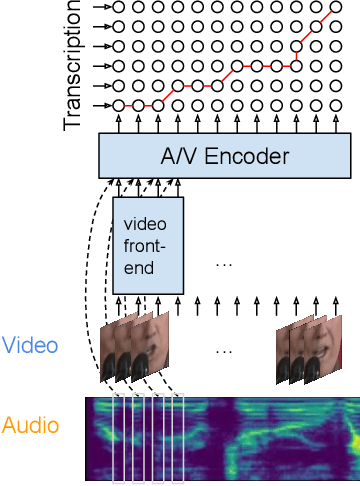
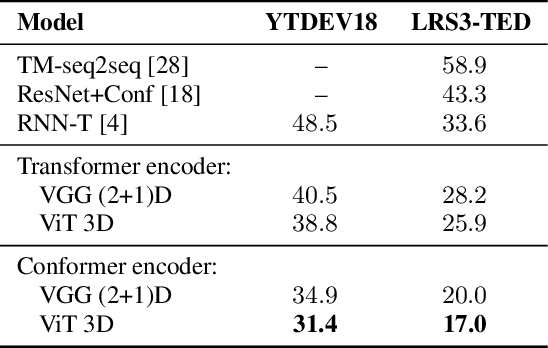
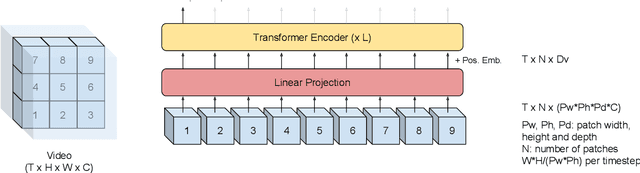
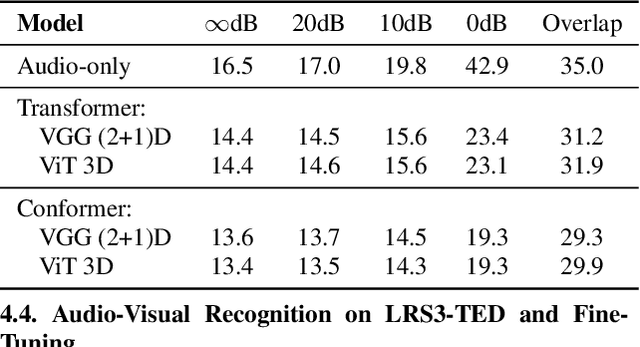
Audio-visual automatic speech recognition (AV-ASR) extends the speech recognition by introducing the video modality. In particular, the information contained in the motion of the speaker's mouth is used to augment the audio features. The video modality is traditionally processed with a 3D convolutional neural network (e.g. 3D version of VGG). Recently, image transformer networks arXiv:2010.11929 demonstrated the ability to extract rich visual features for the image classification task. In this work, we propose to replace the 3D convolution with a video transformer video feature extractor. We train our baselines and the proposed model on a large scale corpus of the YouTube videos. Then we evaluate the performance on a labeled subset of YouTube as well as on the public corpus LRS3-TED. Our best model video-only model achieves the performance of 34.9% WER on YTDEV18 and 19.3% on LRS3-TED which is a 10% and 9% relative improvements over the convolutional baseline. We achieve the state of the art performance of the audio-visual recognition on the LRS3-TED after fine-tuning our model (1.6% WER).
Audio-Visual Speech Recognition is Worth 32$\times$32$\times$8 Voxels
Sep 20, 2021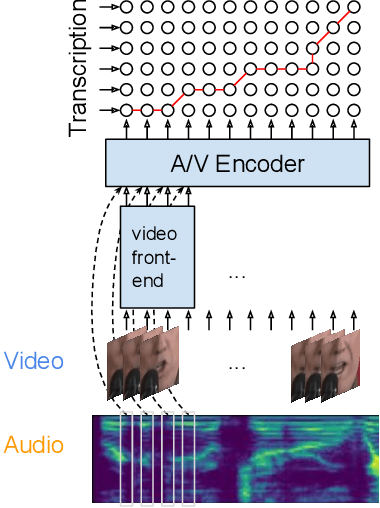


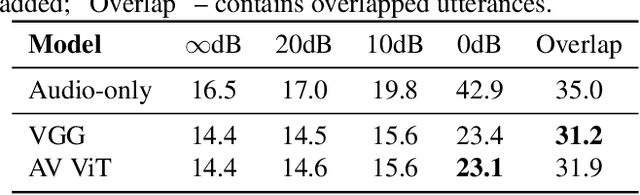
Audio-visual automatic speech recognition (AV-ASR) introduces the video modality into the speech recognition process, often by relying on information conveyed by the motion of the speaker's mouth. The use of the video signal requires extracting visual features, which are then combined with the acoustic features to build an AV-ASR system [1]. This is traditionally done with some form of 3D convolutional network (e.g. VGG) as widely used in the computer vision community. Recently, image transformers [2] have been introduced to extract visual features useful for image classification tasks. In this work, we propose to replace the 3D convolutional visual front-end with a video transformer front-end. We train our systems on a large-scale dataset composed of YouTube videos and evaluate performance on the publicly available LRS3-TED set, as well as on a large set of YouTube videos. On a lip-reading task, the transformer-based front-end shows superior performance compared to a strong convolutional baseline. On an AV-ASR task, the transformer front-end performs as well as (or better than) the convolutional baseline. Fine-tuning our model on the LRS3-TED training set matches previous state of the art. Thus, we experimentally show the viability of the convolution-free model for AV-ASR.
Accounting for Variance in Machine Learning Benchmarks
Mar 01, 2021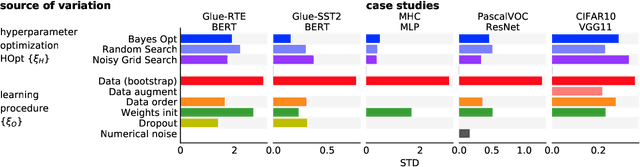
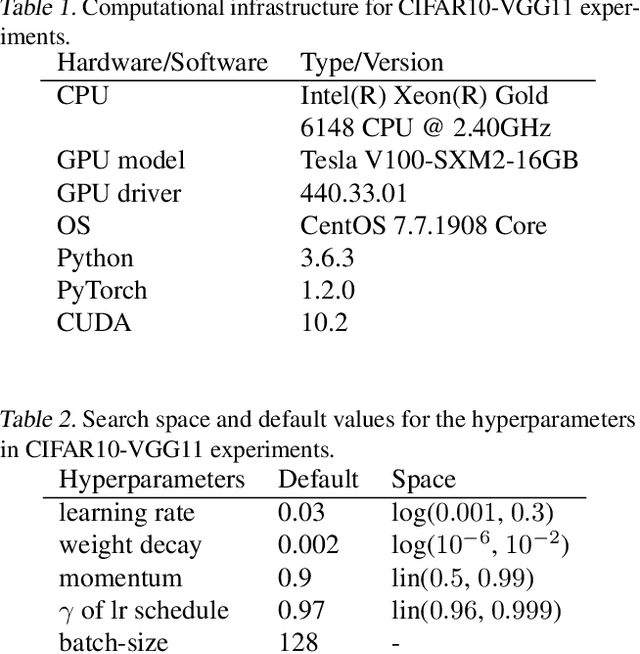
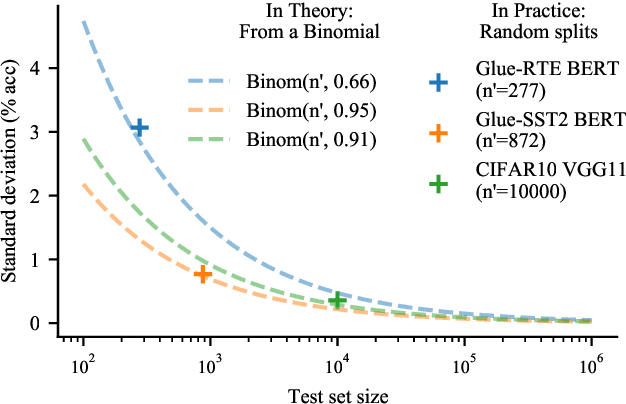
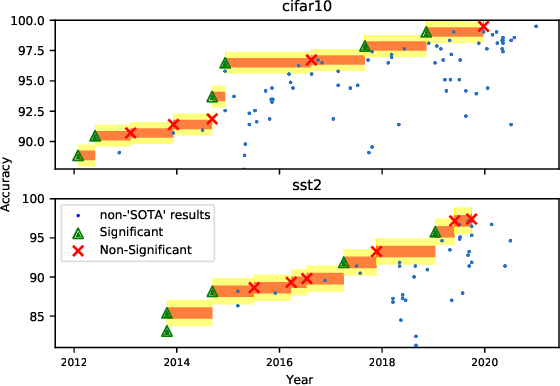
Strong empirical evidence that one machine-learning algorithm A outperforms another one B ideally calls for multiple trials optimizing the learning pipeline over sources of variation such as data sampling, data augmentation, parameter initialization, and hyperparameters choices. This is prohibitively expensive, and corners are cut to reach conclusions. We model the whole benchmarking process, revealing that variance due to data sampling, parameter initialization and hyperparameter choice impact markedly the results. We analyze the predominant comparison methods used today in the light of this variance. We show a counter-intuitive result that adding more sources of variation to an imperfect estimator approaches better the ideal estimator at a 51 times reduction in compute cost. Building on these results, we study the error rate of detecting improvements, on five different deep-learning tasks/architectures. This study leads us to propose recommendations for performance comparisons.
Unsupervised adversarial domain adaptation for acoustic scene classification
Aug 17, 2018


A general problem in acoustic scene classification task is the mismatched conditions between training and testing data, which significantly reduces the performance of the developed methods on classification accuracy. As a countermeasure, we present the first method of unsupervised adversarial domain adaptation for acoustic scene classification. We employ a model pre-trained on data from one set of conditions and by using data from other set of conditions, we adapt the model in order that its output cannot be used for classifying the set of conditions that input data belong to. We use a freely available dataset from the DCASE 2018 challenge Task 1, subtask B, that contains data from mismatched recording devices. We consider the scenario where the annotations are available for the data recorded from one device, but not for the rest. Our results show that with our model agnostic method we can achieve $\sim 10\%$ increase at the accuracy on an unseen and unlabeled dataset, while keeping almost the same performance on the labeled dataset.
Twin Regularization for online speech recognition
Jun 12, 2018


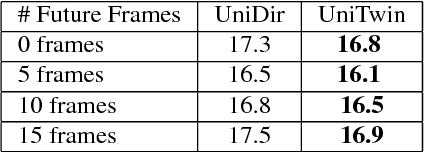
Online speech recognition is crucial for developing natural human-machine interfaces. This modality, however, is significantly more challenging than off-line ASR, since real-time/low-latency constraints inevitably hinder the use of future information, that is known to be very helpful to perform robust predictions. A popular solution to mitigate this issue consists of feeding neural acoustic models with context windows that gather some future frames. This introduces a latency which depends on the number of employed look-ahead features. This paper explores a different approach, based on estimating the future rather than waiting for it. Our technique encourages the hidden representations of a unidirectional recurrent network to embed some useful information about the future. Inspired by a recently proposed technique called Twin Networks, we add a regularization term that forces forward hidden states to be as close as possible to cotemporal backward ones, computed by a "twin" neural network running backwards in time. The experiments, conducted on a number of datasets, recurrent architectures, input features, and acoustic conditions, have shown the effectiveness of this approach. One important advantage is that our method does not introduce any additional computation at test time if compared to standard unidirectional recurrent networks.
Fortified Networks: Improving the Robustness of Deep Networks by Modeling the Manifold of Hidden Representations
Apr 07, 2018

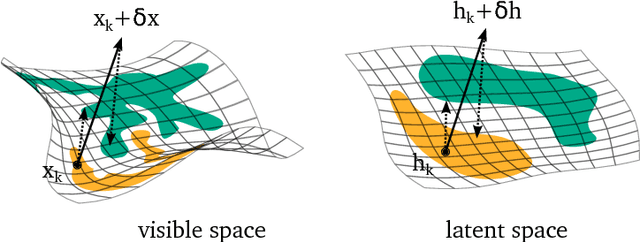

Deep networks have achieved impressive results across a variety of important tasks. However a known weakness is a failure to perform well when evaluated on data which differ from the training distribution, even if these differences are very small, as is the case with adversarial examples. We propose Fortified Networks, a simple transformation of existing networks, which fortifies the hidden layers in a deep network by identifying when the hidden states are off of the data manifold, and maps these hidden states back to parts of the data manifold where the network performs well. Our principal contribution is to show that fortifying these hidden states improves the robustness of deep networks and our experiments (i) demonstrate improved robustness to standard adversarial attacks in both black-box and white-box threat models; (ii) suggest that our improvements are not primarily due to the gradient masking problem and (iii) show the advantage of doing this fortification in the hidden layers instead of the input space.