 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAudio-visual fine-tuning of audio-only ASR models
Paper and Code
Dec 14, 2023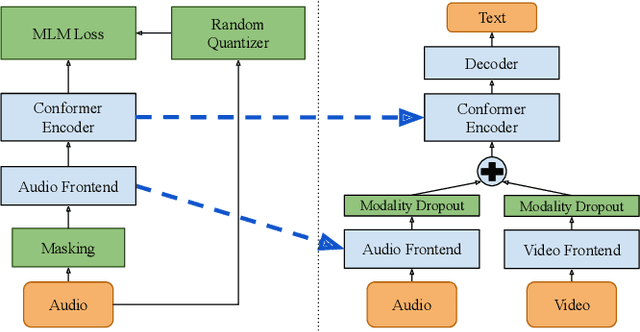
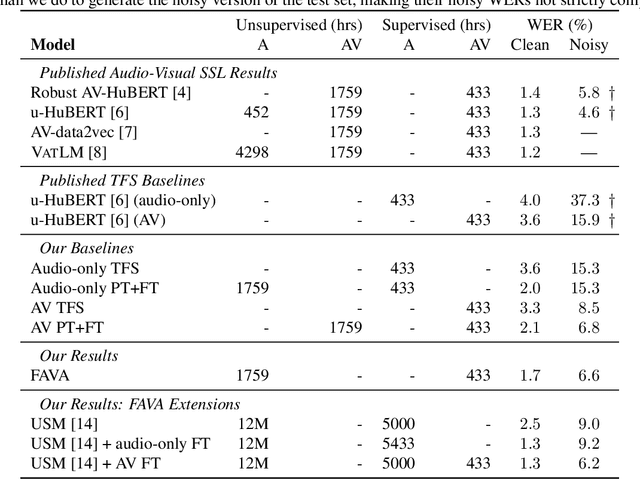

Audio-visual automatic speech recognition (AV-ASR) models are very effective at reducing word error rates on noisy speech, but require large amounts of transcribed AV training data. Recently, audio-visual self-supervised learning (SSL) approaches have been developed to reduce this dependence on transcribed AV data, but these methods are quite complex and computationally expensive. In this work, we propose replacing these expensive AV-SSL methods with a simple and fast \textit{audio-only} SSL method, and then performing AV supervised fine-tuning. We show that this approach is competitive with state-of-the-art (SOTA) AV-SSL methods on the LRS3-TED benchmark task (within 0.5% absolute WER), while being dramatically simpler and more efficient (12-30x faster to pre-train). Furthermore, we show we can extend this approach to convert a SOTA audio-only ASR model into an AV model. By doing so, we match SOTA AV-SSL results, even though no AV data was used during pre-training.