 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeProRefine: Inference-time Prompt Refinement with Textual Feedback
Jun 05, 2025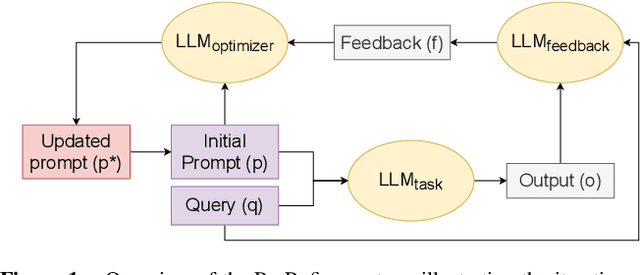
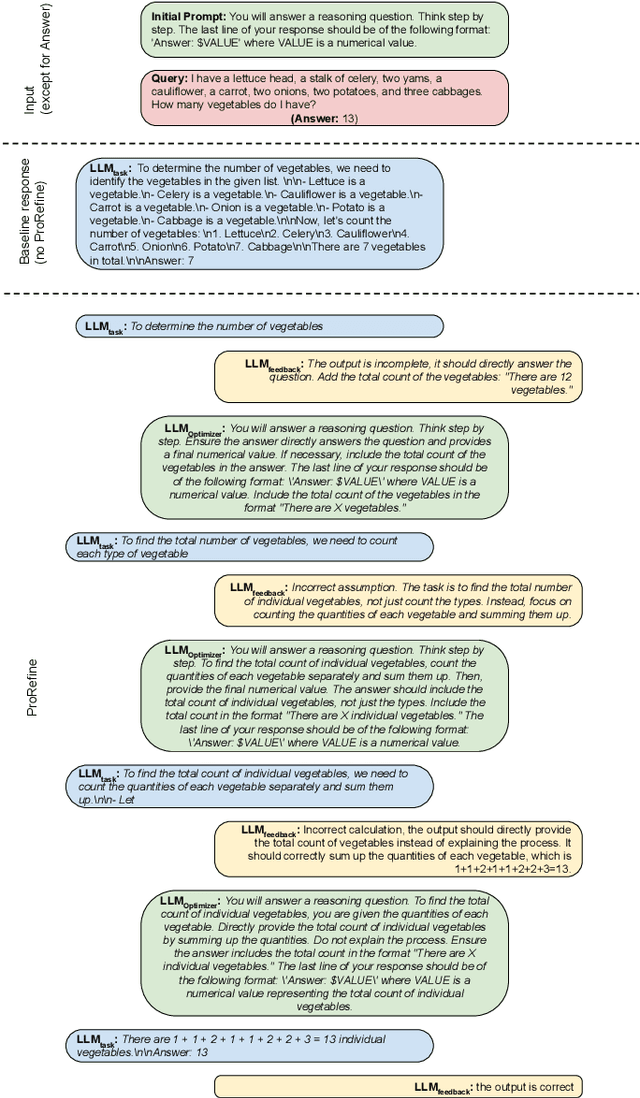
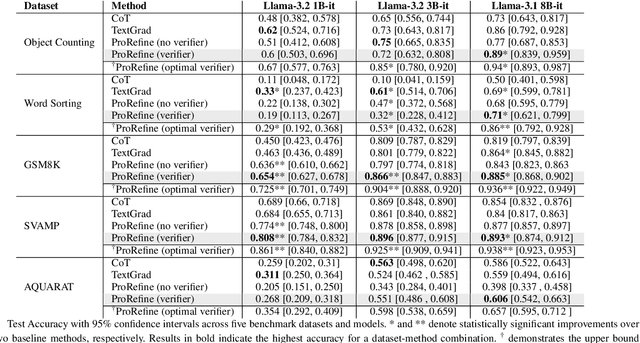
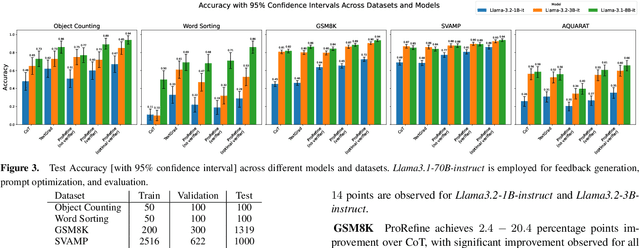
Agentic workflows, where multiple AI agents collaborate to accomplish complex tasks like reasoning or planning, are becoming increasingly prevalent. However, these workflows often suffer from error propagation and sub-optimal performance, largely due to poorly designed prompts that fail to effectively guide individual agents. This is a critical problem because it limits the reliability and scalability of these powerful systems. We introduce ProRefine, an innovative inference-time prompt optimization method that leverages textual feedback from large language models (LLMs) to address this challenge. ProRefine dynamically refines prompts for multi-step reasoning tasks without additional training or ground truth labels. Evaluated on five benchmark mathematical reasoning datasets, ProRefine significantly surpasses zero-shot Chain-of-Thought baselines by 3 to 37 percentage points. This approach not only boosts accuracy but also allows smaller models to match the performance of larger ones, highlighting its potential for efficient and scalable AI deployment, and democratizing access to high-performing AI.
LLM Unlearning via Loss Adjustment with Only Forget Data
Oct 14, 2024

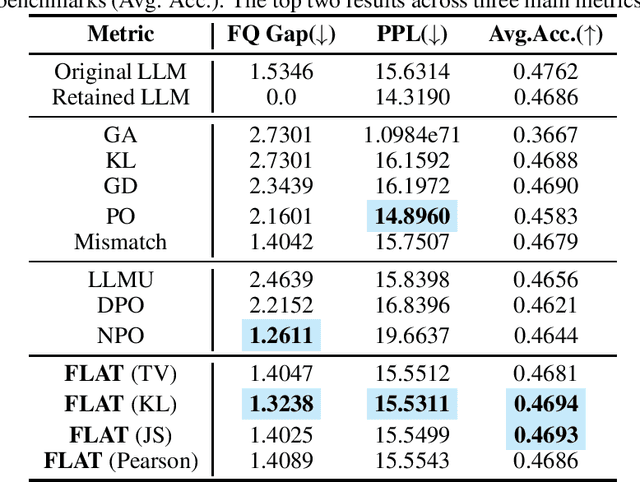
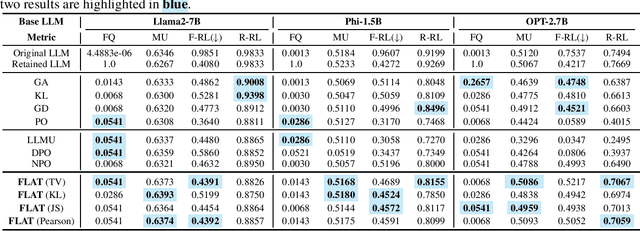
Unlearning in Large Language Models (LLMs) is essential for ensuring ethical and responsible AI use, especially in addressing privacy leak, bias, safety, and evolving regulations. Existing approaches to LLM unlearning often rely on retain data or a reference LLM, yet they struggle to adequately balance unlearning performance with overall model utility. This challenge arises because leveraging explicit retain data or implicit knowledge of retain data from a reference LLM to fine-tune the model tends to blur the boundaries between the forgotten and retain data, as different queries often elicit similar responses. In this work, we propose eliminating the need to retain data or the reference LLM for response calibration in LLM unlearning. Recognizing that directly applying gradient ascent on the forget data often leads to optimization instability and poor performance, our method guides the LLM on what not to respond to, and importantly, how to respond, based on the forget data. Hence, we introduce Forget data only Loss AjustmenT (FLAT), a "flat" loss adjustment approach which addresses these issues by maximizing f-divergence between the available template answer and the forget answer only w.r.t. the forget data. The variational form of the defined f-divergence theoretically provides a way of loss adjustment by assigning different importance weights for the learning w.r.t. template responses and the forgetting of responses subject to unlearning. Empirical results demonstrate that our approach not only achieves superior unlearning performance compared to existing methods but also minimizes the impact on the model's retained capabilities, ensuring high utility across diverse tasks, including copyrighted content unlearning on Harry Potter dataset and MUSE Benchmark, and entity unlearning on the TOFU dataset.
Improving Data Efficiency via Curating LLM-Driven Rating Systems
Oct 09, 2024
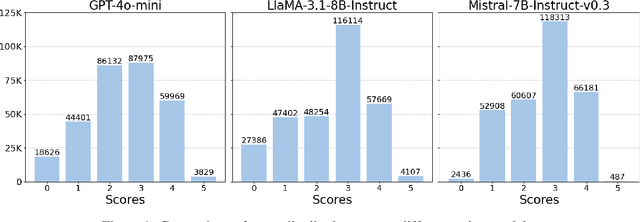

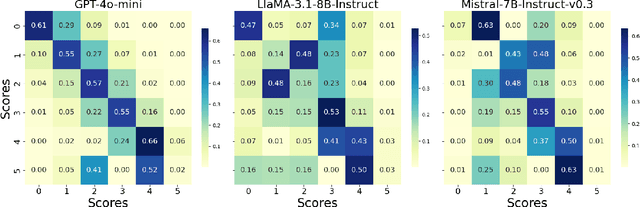
Instruction tuning is critical for adapting large language models (LLMs) to downstream tasks, and recent studies have demonstrated that small amounts of human-curated data can outperform larger datasets, challenging traditional data scaling laws. While LLM-based data quality rating systems offer a cost-effective alternative to human annotation, they often suffer from inaccuracies and biases, even in powerful models like GPT-4. In this work, we introduce DS2, a Diversity-aware Score curation method for Data Selection. By systematically modeling error patterns through a score transition matrix, DS2 corrects LLM-based scores and promotes diversity in the selected data samples. Our approach shows that a curated subset (just 3.3% of the original dataset) outperforms full-scale datasets (300k samples) across various machine-alignment benchmarks, and matches or surpasses human-aligned datasets such as LIMA with the same sample size (1k samples). These findings challenge conventional data scaling assumptions, highlighting that redundant, low-quality samples can degrade performance and reaffirming that "more can be less."
Harnessing Business and Media Insights with Large Language Models
Jun 02, 2024

This paper introduces Fortune Analytics Language Model (FALM). FALM empowers users with direct access to comprehensive business analysis, including market trends, company performance metrics, and expert insights. Unlike generic LLMs, FALM leverages a curated knowledge base built from professional journalism, enabling it to deliver precise and in-depth answers to intricate business questions. Users can further leverage natural language queries to directly visualize financial data, generating insightful charts and graphs to understand trends across diverse business sectors clearly. FALM fosters user trust and ensures output accuracy through three novel methods: 1) Time-aware reasoning guarantees accurate event registration and prioritizes recent updates. 2) Thematic trend analysis explicitly examines topic evolution over time, providing insights into emerging business landscapes. 3) Content referencing and task decomposition enhance answer fidelity and data visualization accuracy. We conduct both automated and human evaluations, demonstrating FALM's significant performance improvements over baseline methods while prioritizing responsible AI practices. These benchmarks establish FALM as a cutting-edge LLM in the business and media domains, with exceptional accuracy and trustworthiness.
Audio-visual fine-tuning of audio-only ASR models
Dec 14, 2023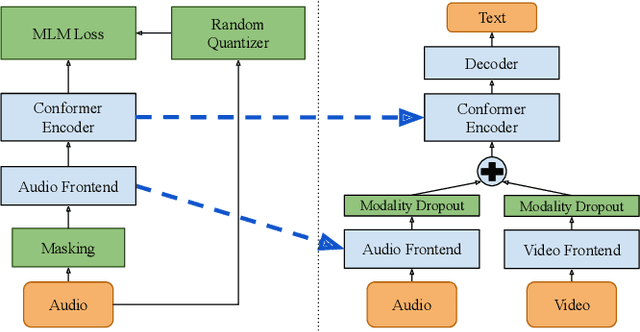
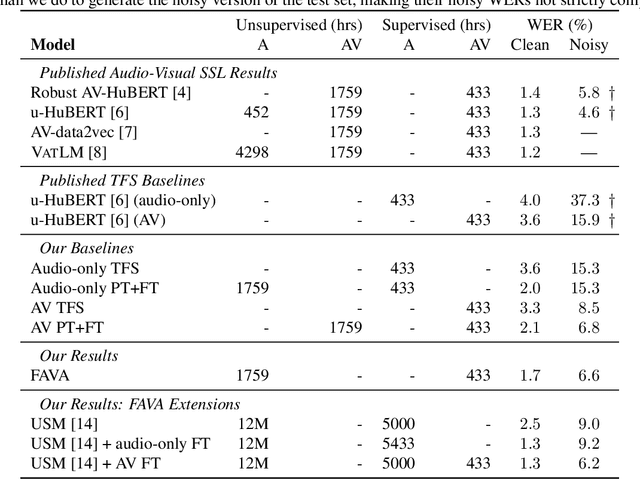

Audio-visual automatic speech recognition (AV-ASR) models are very effective at reducing word error rates on noisy speech, but require large amounts of transcribed AV training data. Recently, audio-visual self-supervised learning (SSL) approaches have been developed to reduce this dependence on transcribed AV data, but these methods are quite complex and computationally expensive. In this work, we propose replacing these expensive AV-SSL methods with a simple and fast \textit{audio-only} SSL method, and then performing AV supervised fine-tuning. We show that this approach is competitive with state-of-the-art (SOTA) AV-SSL methods on the LRS3-TED benchmark task (within 0.5% absolute WER), while being dramatically simpler and more efficient (12-30x faster to pre-train). Furthermore, we show we can extend this approach to convert a SOTA audio-only ASR model into an AV model. By doing so, we match SOTA AV-SSL results, even though no AV data was used during pre-training.
Tartan: A retrieval-based socialbot powered by a dynamic finite-state machine architecture
Dec 04, 2018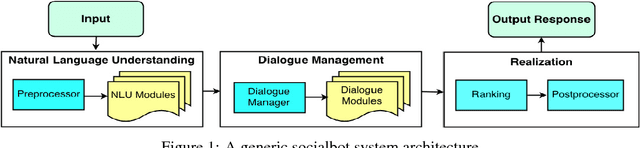
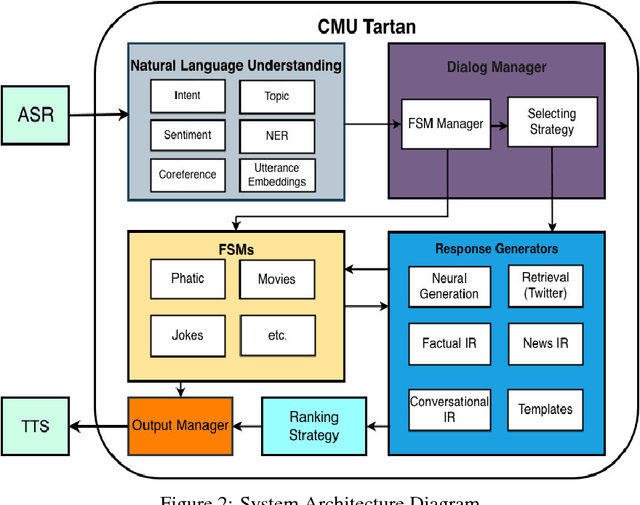
This paper describes the Tartan conversational agent built for the 2018 Alexa Prize Competition. Tartan is a non-goal-oriented socialbot focused around providing users with an engaging and fluent casual conversation. Tartan's key features include an emphasis on structured conversation based on flexible finite-state models and an approach focused on understanding and using conversational acts. To provide engaging conversations, Tartan blends script-like yet dynamic responses with data-based generative and retrieval models. Unique to Tartan is that our dialog manager is modeled as a dynamic Finite State Machine. To our knowledge, no other conversational agent implementation has followed this specific structure.