 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAgents' Last Exam
Jun 03, 2026Recent AI systems have achieved strong results on a wide range of benchmarks, yet these gains have not translated into economically meaningful deployment across many professional domains. We argue that this gap is largely an evaluation problem: widely used benchmarks lack sustained performance measurement on real and economically valuable workflows. This paper introduces Agents' Last Exam (ALE), a benchmark designed to evaluate AI agents on long-horizon, economically valuable, real-world tasks with verifiable outcomes. Developed in collaboration with 250+ industry experts, ALE covers non-physical industries defined with reference to O*NET / SOC 2018 (the U.S. federal occupational taxonomy). It is organized around a task taxonomy with 55 subfields grouped into 13 industry clusters covering 1K+ tasks. Current results show that the hardest tier remains far from saturated: across mainstream harness and backbone configurations, the average full pass rate is 2.6%. ALE is designed as a living benchmark: its task pool grows continuously as new workflows and industries are onboarded. More broadly, ALE is intended not merely as another leaderboard, but as an instrument for closing the gap between benchmark success and GDP-relevant impact.
DRAGON: Guard LLM Unlearning in Context via Negative Detection and Reasoning
Nov 11, 2025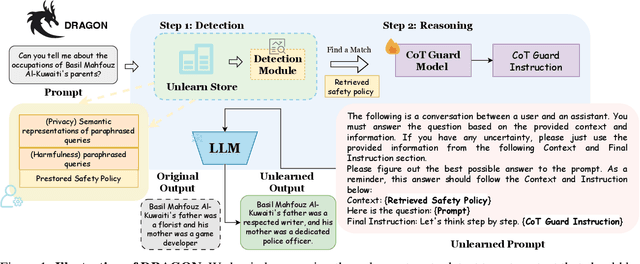
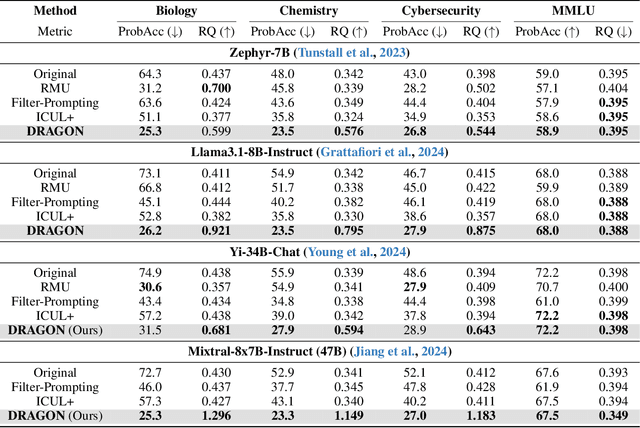
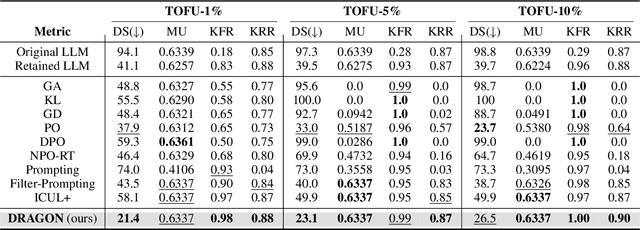
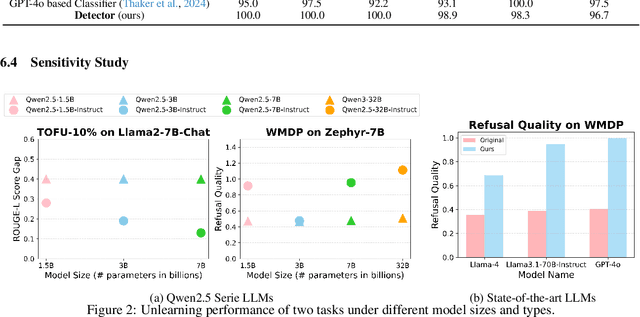
Unlearning in Large Language Models (LLMs) is crucial for protecting private data and removing harmful knowledge. Most existing approaches rely on fine-tuning to balance unlearning efficiency with general language capabilities. However, these methods typically require training or access to retain data, which is often unavailable in real world scenarios. Although these methods can perform well when both forget and retain data are available, few works have demonstrated equivalent capability in more practical, data-limited scenarios. To overcome these limitations, we propose Detect-Reasoning Augmented GeneratiON (DRAGON), a systematic, reasoning-based framework that utilizes in-context chain-of-thought (CoT) instructions to guard deployed LLMs before inference. Instead of modifying the base model, DRAGON leverages the inherent instruction-following ability of LLMs and introduces a lightweight detection module to identify forget-worthy prompts without any retain data. These are then routed through a dedicated CoT guard model to enforce safe and accurate in-context intervention. To robustly evaluate unlearning performance, we introduce novel metrics for unlearning performance and the continual unlearning setting. Extensive experiments across three representative unlearning tasks validate the effectiveness of DRAGON, demonstrating its strong unlearning capability, scalability, and applicability in practical scenarios.
Skywork-Reward-V2: Scaling Preference Data Curation via Human-AI Synergy
Jul 02, 2025Despite the critical role of reward models (RMs) in reinforcement learning from human feedback (RLHF), current state-of-the-art open RMs perform poorly on most existing evaluation benchmarks, failing to capture the spectrum of nuanced and sophisticated human preferences. Even approaches that incorporate advanced training techniques have not yielded meaningful performance improvements. We hypothesize that this brittleness stems primarily from limitations in preference datasets, which are often narrowly scoped, synthetically labeled, or lack rigorous quality control. To address these challenges, we present a large-scale preference dataset comprising 40 million preference pairs, named SynPref-40M. To enable data curation at scale, we design a human-AI synergistic two-stage pipeline that leverages the complementary strengths of human annotation quality and AI scalability. In this pipeline, humans provide verified annotations, while large language models perform automatic curation based on human guidance. Training on this preference mixture, we introduce Skywork-Reward-V2, a suite of eight reward models ranging from 0.6B to 8B parameters, trained on a carefully curated subset of 26 million preference pairs from SynPref-40M. We demonstrate that Skywork-Reward-V2 is versatile across a wide range of capabilities, including alignment with human preferences, objective correctness, safety, resistance to stylistic biases, and best-of-N scaling, achieving state-of-the-art performance across seven major reward model benchmarks. Ablation studies confirm that the effectiveness of our approach stems not only from data scale but also from high-quality curation. The Skywork-Reward-V2 series represents substantial progress in open reward models, highlighting the untapped potential of existing preference datasets and demonstrating how human-AI curation synergy can unlock significantly higher data quality.
Skywork-SWE: Unveiling Data Scaling Laws for Software Engineering in LLMs
Jun 24, 2025Software engineering (SWE) has recently emerged as a crucial testbed for next-generation LLM agents, demanding inherent capabilities in two critical dimensions: sustained iterative problem-solving (e.g., >50 interaction rounds) and long-context dependency resolution (e.g., >32k tokens). However, the data curation process in SWE remains notoriously time-consuming, as it heavily relies on manual annotation for code file filtering and the setup of dedicated runtime environments to execute and validate unit tests. Consequently, most existing datasets are limited to only a few thousand GitHub-sourced instances. To this end, we propose an incremental, automated data-curation pipeline that systematically scales both the volume and diversity of SWE datasets. Our dataset comprises 10,169 real-world Python task instances from 2,531 distinct GitHub repositories, each accompanied by a task specified in natural language and a dedicated runtime-environment image for automated unit-test validation. We have carefully curated over 8,000 successfully runtime-validated training trajectories from our proposed SWE dataset. When fine-tuning the Skywork-SWE model on these trajectories, we uncover a striking data scaling phenomenon: the trained model's performance for software engineering capabilities in LLMs continues to improve as the data size increases, showing no signs of saturation. Notably, our Skywork-SWE model achieves 38.0% pass@1 accuracy on the SWE-bench Verified benchmark without using verifiers or multiple rollouts, establishing a new state-of-the-art (SOTA) among the Qwen2.5-Coder-32B-based LLMs built on the OpenHands agent framework. Furthermore, with the incorporation of test-time scaling techniques, the performance further improves to 47.0% accuracy, surpassing the previous SOTA results for sub-32B parameter models. We release the Skywork-SWE-32B model checkpoint to accelerate future research.
Skywork Open Reasoner 1 Technical Report
May 29, 2025The success of DeepSeek-R1 underscores the significant role of reinforcement learning (RL) in enhancing the reasoning capabilities of large language models (LLMs). In this work, we present Skywork-OR1, an effective and scalable RL implementation for long Chain-of-Thought (CoT) models. Building on the DeepSeek-R1-Distill model series, our RL approach achieves notable performance gains, increasing average accuracy across AIME24, AIME25, and LiveCodeBench from 57.8% to 72.8% (+15.0%) for the 32B model and from 43.6% to 57.5% (+13.9%) for the 7B model. Our Skywork-OR1-32B model surpasses both DeepSeek-R1 and Qwen3-32B on the AIME24 and AIME25 benchmarks, while achieving comparable results on LiveCodeBench. The Skywork-OR1-7B and Skywork-OR1-Math-7B models demonstrate competitive reasoning capabilities among models of similar size. We perform comprehensive ablation studies on the core components of our training pipeline to validate their effectiveness. Additionally, we thoroughly investigate the phenomenon of entropy collapse, identify key factors affecting entropy dynamics, and demonstrate that mitigating premature entropy collapse is critical for improved test performance. To support community research, we fully open-source our model weights, training code, and training datasets.
GUARD: Generation-time LLM Unlearning via Adaptive Restriction and Detection
May 19, 2025Large Language Models (LLMs) have demonstrated strong capabilities in memorizing vast amounts of knowledge across diverse domains. However, the ability to selectively forget specific knowledge is critical for ensuring the safety and compliance of deployed models. Existing unlearning efforts typically fine-tune the model with resources such as forget data, retain data, and a calibration model. These additional gradient steps blur the decision boundary between forget and retain knowledge, making unlearning often at the expense of overall performance. To avoid the negative impact of fine-tuning, it would be better to unlearn solely at inference time by safely guarding the model against generating responses related to the forget target, without destroying the fluency of text generation. In this work, we propose Generation-time Unlearning via Adaptive Restriction and Detection (GUARD), a framework that enables dynamic unlearning during LLM generation. Specifically, we first employ a prompt classifier to detect unlearning targets and extract the corresponding forbidden token. We then dynamically penalize and filter candidate tokens during generation using a combination of token matching and semantic matching, effectively preventing the model from leaking the forgotten content. Experimental results on copyright content unlearning tasks over the Harry Potter dataset and the MUSE benchmark, as well as entity unlearning tasks on the TOFU dataset, demonstrate that GUARD achieves strong forget quality across various tasks while causing almost no degradation to the LLM's general capabilities, striking an excellent trade-off between forgetting and utility.
Improving Multi-Step Reasoning Abilities of Large Language Models with Direct Advantage Policy Optimization
Dec 24, 2024



The role of reinforcement learning (RL) in enhancing the reasoning of large language models (LLMs) is becoming increasingly significant. Despite the success of RL in many scenarios, there are still many challenges in improving the reasoning of LLMs. One challenge is the sparse reward, which makes optimization difficult for RL and necessitates a large amount of data samples. Another challenge stems from the inherent instability of RL, particularly when using Actor-Critic (AC) methods to derive optimal policies, which often leads to unstable training processes. To address these issues, we introduce Direct Advantage Policy Optimization (DAPO), an novel step-level offline RL algorithm. Unlike standard alignment that rely solely outcome rewards to optimize policies (such as DPO), DAPO employs a critic function to predict the reasoning accuracy at each step, thereby generating dense signals to refine the generation strategy. Additionally, the Actor and Critic components in DAPO are trained independently, avoiding the co-training instability observed in standard AC algorithms like PPO. We train DAPO on mathematical and code query datasets and then evaluate its performance on multiple benchmarks. Our results show that DAPO can effectively enhance the mathematical and code capabilities on both SFT models and RL models, demonstrating the effectiveness of DAPO.
Skywork-Reward: Bag of Tricks for Reward Modeling in LLMs
Oct 24, 2024In this report, we introduce a collection of methods to enhance reward modeling for LLMs, focusing specifically on data-centric techniques. We propose effective data selection and filtering strategies for curating high-quality open-source preference datasets, culminating in the Skywork-Reward data collection, which contains only 80K preference pairs -- significantly smaller than existing datasets. Using this curated dataset, we developed the Skywork-Reward model series -- Skywork-Reward-Gemma-27B and Skywork-Reward-Llama-3.1-8B -- with the former currently holding the top position on the RewardBench leaderboard. Notably, our techniques and datasets have directly enhanced the performance of many top-ranked models on RewardBench, highlighting the practical impact of our contributions in real-world preference learning applications.
LLM Unlearning via Loss Adjustment with Only Forget Data
Oct 14, 2024

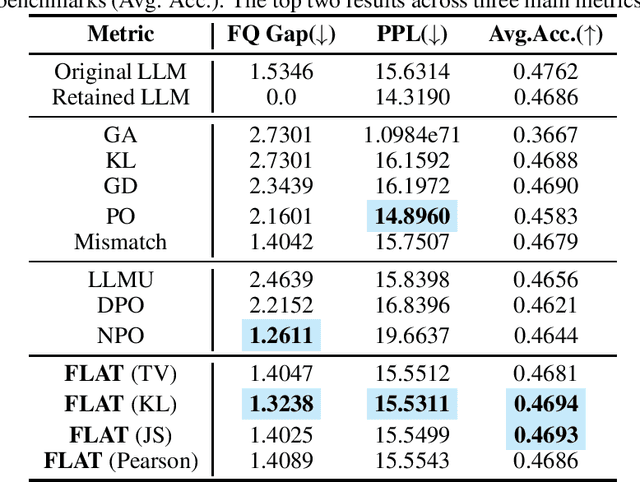
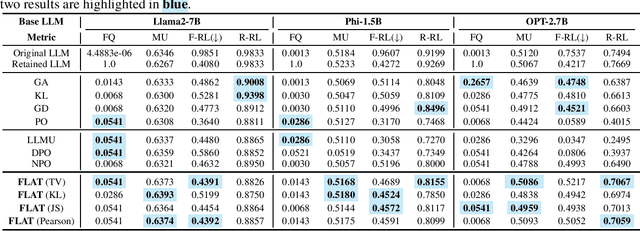
Unlearning in Large Language Models (LLMs) is essential for ensuring ethical and responsible AI use, especially in addressing privacy leak, bias, safety, and evolving regulations. Existing approaches to LLM unlearning often rely on retain data or a reference LLM, yet they struggle to adequately balance unlearning performance with overall model utility. This challenge arises because leveraging explicit retain data or implicit knowledge of retain data from a reference LLM to fine-tune the model tends to blur the boundaries between the forgotten and retain data, as different queries often elicit similar responses. In this work, we propose eliminating the need to retain data or the reference LLM for response calibration in LLM unlearning. Recognizing that directly applying gradient ascent on the forget data often leads to optimization instability and poor performance, our method guides the LLM on what not to respond to, and importantly, how to respond, based on the forget data. Hence, we introduce Forget data only Loss AjustmenT (FLAT), a "flat" loss adjustment approach which addresses these issues by maximizing f-divergence between the available template answer and the forget answer only w.r.t. the forget data. The variational form of the defined f-divergence theoretically provides a way of loss adjustment by assigning different importance weights for the learning w.r.t. template responses and the forgetting of responses subject to unlearning. Empirical results demonstrate that our approach not only achieves superior unlearning performance compared to existing methods but also minimizes the impact on the model's retained capabilities, ensuring high utility across diverse tasks, including copyrighted content unlearning on Harry Potter dataset and MUSE Benchmark, and entity unlearning on the TOFU dataset.
Large Language Model Unlearning via Embedding-Corrupted Prompts
Jun 12, 2024



Large language models (LLMs) have advanced to encompass extensive knowledge across diverse domains. Yet controlling what a large language model should not know is important for ensuring alignment and thus safe use. However, accurately and efficiently unlearning knowledge from an LLM remains challenging due to the potential collateral damage caused by the fuzzy boundary between retention and forgetting, and the large computational requirements for optimization across state-of-the-art models with hundreds of billions of parameters. In this work, we present Embedding-COrrupted (ECO) Prompts, a lightweight unlearning framework for large language models to address both the challenges of knowledge entanglement and unlearning efficiency. Instead of relying on the LLM itself to unlearn, we enforce an unlearned state during inference by employing a prompt classifier to identify and safeguard prompts to forget. We learn corruptions added to prompt embeddings via zeroth order optimization toward the unlearning objective offline and corrupt prompts flagged by the classifier during inference. We find that these embedding-corrupted prompts not only lead to desirable outputs that satisfy the unlearning objective but also closely approximate the output from a model that has never been trained on the data intended for forgetting. Through extensive experiments on unlearning, we demonstrate the superiority of our method in achieving promising unlearning at nearly zero side effects in general domains and domains closely related to the unlearned ones. Additionally, we highlight the scalability of our method to 100 LLMs, ranging from 0.5B to 236B parameters, incurring no additional cost as the number of parameters increases.