 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSkywork-Reward-V2: Scaling Preference Data Curation via Human-AI Synergy
Jul 02, 2025Despite the critical role of reward models (RMs) in reinforcement learning from human feedback (RLHF), current state-of-the-art open RMs perform poorly on most existing evaluation benchmarks, failing to capture the spectrum of nuanced and sophisticated human preferences. Even approaches that incorporate advanced training techniques have not yielded meaningful performance improvements. We hypothesize that this brittleness stems primarily from limitations in preference datasets, which are often narrowly scoped, synthetically labeled, or lack rigorous quality control. To address these challenges, we present a large-scale preference dataset comprising 40 million preference pairs, named SynPref-40M. To enable data curation at scale, we design a human-AI synergistic two-stage pipeline that leverages the complementary strengths of human annotation quality and AI scalability. In this pipeline, humans provide verified annotations, while large language models perform automatic curation based on human guidance. Training on this preference mixture, we introduce Skywork-Reward-V2, a suite of eight reward models ranging from 0.6B to 8B parameters, trained on a carefully curated subset of 26 million preference pairs from SynPref-40M. We demonstrate that Skywork-Reward-V2 is versatile across a wide range of capabilities, including alignment with human preferences, objective correctness, safety, resistance to stylistic biases, and best-of-N scaling, achieving state-of-the-art performance across seven major reward model benchmarks. Ablation studies confirm that the effectiveness of our approach stems not only from data scale but also from high-quality curation. The Skywork-Reward-V2 series represents substantial progress in open reward models, highlighting the untapped potential of existing preference datasets and demonstrating how human-AI curation synergy can unlock significantly higher data quality.
Skywork-SWE: Unveiling Data Scaling Laws for Software Engineering in LLMs
Jun 24, 2025Software engineering (SWE) has recently emerged as a crucial testbed for next-generation LLM agents, demanding inherent capabilities in two critical dimensions: sustained iterative problem-solving (e.g., >50 interaction rounds) and long-context dependency resolution (e.g., >32k tokens). However, the data curation process in SWE remains notoriously time-consuming, as it heavily relies on manual annotation for code file filtering and the setup of dedicated runtime environments to execute and validate unit tests. Consequently, most existing datasets are limited to only a few thousand GitHub-sourced instances. To this end, we propose an incremental, automated data-curation pipeline that systematically scales both the volume and diversity of SWE datasets. Our dataset comprises 10,169 real-world Python task instances from 2,531 distinct GitHub repositories, each accompanied by a task specified in natural language and a dedicated runtime-environment image for automated unit-test validation. We have carefully curated over 8,000 successfully runtime-validated training trajectories from our proposed SWE dataset. When fine-tuning the Skywork-SWE model on these trajectories, we uncover a striking data scaling phenomenon: the trained model's performance for software engineering capabilities in LLMs continues to improve as the data size increases, showing no signs of saturation. Notably, our Skywork-SWE model achieves 38.0% pass@1 accuracy on the SWE-bench Verified benchmark without using verifiers or multiple rollouts, establishing a new state-of-the-art (SOTA) among the Qwen2.5-Coder-32B-based LLMs built on the OpenHands agent framework. Furthermore, with the incorporation of test-time scaling techniques, the performance further improves to 47.0% accuracy, surpassing the previous SOTA results for sub-32B parameter models. We release the Skywork-SWE-32B model checkpoint to accelerate future research.
Skywork Open Reasoner 1 Technical Report
May 29, 2025The success of DeepSeek-R1 underscores the significant role of reinforcement learning (RL) in enhancing the reasoning capabilities of large language models (LLMs). In this work, we present Skywork-OR1, an effective and scalable RL implementation for long Chain-of-Thought (CoT) models. Building on the DeepSeek-R1-Distill model series, our RL approach achieves notable performance gains, increasing average accuracy across AIME24, AIME25, and LiveCodeBench from 57.8% to 72.8% (+15.0%) for the 32B model and from 43.6% to 57.5% (+13.9%) for the 7B model. Our Skywork-OR1-32B model surpasses both DeepSeek-R1 and Qwen3-32B on the AIME24 and AIME25 benchmarks, while achieving comparable results on LiveCodeBench. The Skywork-OR1-7B and Skywork-OR1-Math-7B models demonstrate competitive reasoning capabilities among models of similar size. We perform comprehensive ablation studies on the core components of our training pipeline to validate their effectiveness. Additionally, we thoroughly investigate the phenomenon of entropy collapse, identify key factors affecting entropy dynamics, and demonstrate that mitigating premature entropy collapse is critical for improved test performance. To support community research, we fully open-source our model weights, training code, and training datasets.
Skywork-Reward: Bag of Tricks for Reward Modeling in LLMs
Oct 24, 2024In this report, we introduce a collection of methods to enhance reward modeling for LLMs, focusing specifically on data-centric techniques. We propose effective data selection and filtering strategies for curating high-quality open-source preference datasets, culminating in the Skywork-Reward data collection, which contains only 80K preference pairs -- significantly smaller than existing datasets. Using this curated dataset, we developed the Skywork-Reward model series -- Skywork-Reward-Gemma-27B and Skywork-Reward-Llama-3.1-8B -- with the former currently holding the top position on the RewardBench leaderboard. Notably, our techniques and datasets have directly enhanced the performance of many top-ranked models on RewardBench, highlighting the practical impact of our contributions in real-world preference learning applications.
Skywork-Math: Data Scaling Laws for Mathematical Reasoning in Large Language Models -- The Story Goes On
Jul 11, 2024



In this paper, we investigate the underlying factors that potentially enhance the mathematical reasoning capabilities of large language models (LLMs). We argue that the data scaling law for math reasoning capabilities in modern LLMs is far from being saturated, highlighting how the model's quality improves with increases in data quantity. To support this claim, we introduce the Skywork-Math model series, supervised fine-tuned (SFT) on common 7B LLMs using our proposed 2.5M-instance Skywork-MathQA dataset. Skywork-Math 7B has achieved impressive accuracies of 51.2% on the competition-level MATH benchmark and 83.9% on the GSM8K benchmark using only SFT data, outperforming an early version of GPT-4 on MATH. The superior performance of Skywork-Math models contributes to our novel two-stage data synthesis and model SFT pipelines, which include three different augmentation methods and a diverse seed problem set, ensuring both the quantity and quality of Skywork-MathQA dataset across varying difficulty levels. Most importantly, we provide several practical takeaways to enhance math reasoning abilities in LLMs for both research and industry applications.
SCC: an efficient deep reinforcement learning agent mastering the game of StarCraft II
Dec 24, 2020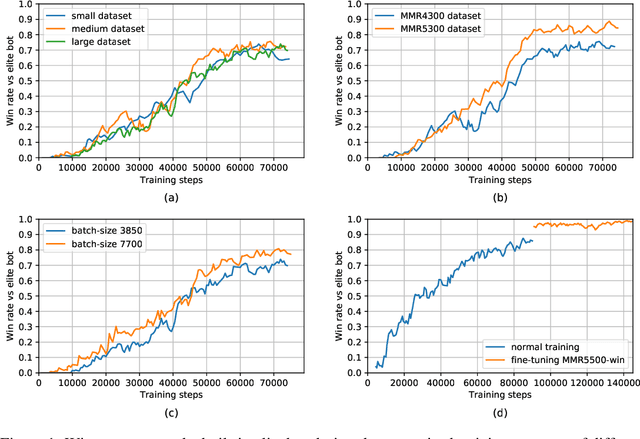
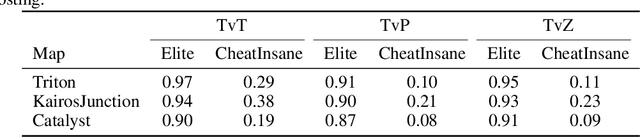
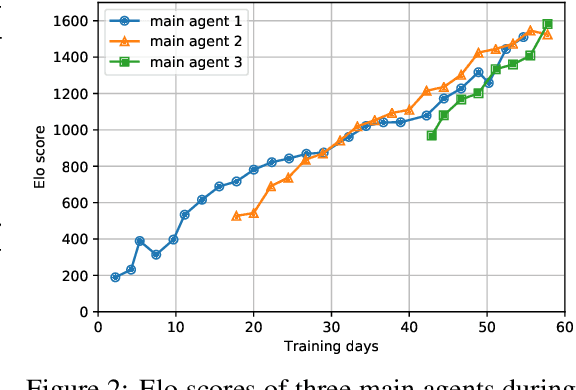
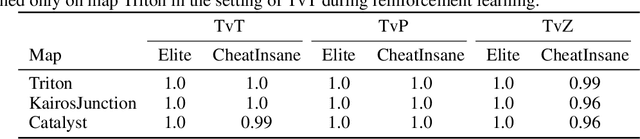
AlphaStar, the AI that reaches GrandMaster level in StarCraft II, is a remarkable milestone demonstrating what deep reinforcement learning can achieve in complex Real-Time Strategy (RTS) games. However, the complexities of the game, algorithms and systems, and especially the tremendous amount of computation needed are big obstacles for the community to conduct further research in this direction. We propose a deep reinforcement learning agent, StarCraft Commander (SCC). With order of magnitude less computation, it demonstrates top human performance defeating GrandMaster players in test matches and top professional players in a live event. Moreover, it shows strong robustness to various human strategies and discovers novel strategies unseen from human plays. In this paper, we will share the key insights and optimizations on efficient imitation learning and reinforcement learning for StarCraft II full game.