 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeRethinking the Trust Region in LLM Reinforcement Learning
Feb 04, 2026Reinforcement learning (RL) has become a cornerstone for fine-tuning Large Language Models (LLMs), with Proximal Policy Optimization (PPO) serving as the de facto standard algorithm. Despite its ubiquity, we argue that the core ratio clipping mechanism in PPO is structurally ill-suited for the large vocabularies inherent to LLMs. PPO constrains policy updates based on the probability ratio of sampled tokens, which serves as a noisy single-sample Monte Carlo estimate of the true policy divergence. This creates a sub-optimal learning dynamic: updates to low-probability tokens are aggressively over-penalized, while potentially catastrophic shifts in high-probability tokens are under-constrained, leading to training inefficiency and instability. To address this, we propose Divergence Proximal Policy Optimization (DPPO), which substitutes heuristic clipping with a more principled constraint based on a direct estimate of policy divergence (e.g., Total Variation or KL). To avoid huge memory footprint, we introduce the efficient Binary and Top-K approximations to capture the essential divergence with negligible overhead. Extensive empirical evaluations demonstrate that DPPO achieves superior training stability and efficiency compared to existing methods, offering a more robust foundation for RL-based LLM fine-tuning.
Revisiting Parameter Server in LLM Post-Training
Jan 27, 2026Modern data parallel (DP) training favors collective communication over parameter servers (PS) for its simplicity and efficiency under balanced workloads. However, the balanced workload assumption no longer holds in large language model (LLM) post-training due to the high variance in sequence lengths. Under imbalanced workloads, collective communication creates synchronization barriers, leading to under-utilization of devices with smaller workloads. This change in training dynamics calls for a revisit of the PS paradigm for its robustness to such imbalance. We propose \textbf{On-Demand Communication (ODC)}, which adapts PS into Fully Sharded Data Parallel (FSDP) by replacing collective all-gather and reduce-scatter with direct point-to-point communication. Compared to FSDP, ODC reduces the synchronization barrier from once per layer to once per minibatch and decouples the workload on each device so that faster workers are not stalled. It also enables simpler and more effective load balancing at the minibatch level. Across diverse LLM post-training tasks, ODC consistently improves device utilization and training throughput, achieving up to a 36\% speedup over standard FSDP. These results demonstrate that ODC is a superior fit for the prevalent imbalanced workloads in LLM post-training. Our implementation of ODC and integration with FSDP is open-sourced at https://github.com/sail-sg/odc.
Defeating the Training-Inference Mismatch via FP16
Oct 30, 2025Reinforcement learning (RL) fine-tuning of large language models (LLMs) often suffers from instability due to the numerical mismatch between the training and inference policies. While prior work has attempted to mitigate this issue through algorithmic corrections or engineering alignments, we show that its root cause lies in the floating point precision itself. The widely adopted BF16, despite its large dynamic range, introduces large rounding errors that breaks the consistency between training and inference. In this work, we demonstrate that simply reverting to \textbf{FP16} effectively eliminates this mismatch. The change is simple, fully supported by modern frameworks with only a few lines of code change, and requires no modification to the model architecture or learning algorithm. Our results suggest that using FP16 uniformly yields more stable optimization, faster convergence, and stronger performance across diverse tasks, algorithms and frameworks. We hope these findings motivate a broader reconsideration of precision trade-offs in RL fine-tuning.
Optimizing Anytime Reasoning via Budget Relative Policy Optimization
May 19, 2025



Scaling test-time compute is crucial for enhancing the reasoning capabilities of large language models (LLMs). Existing approaches typically employ reinforcement learning (RL) to maximize a verifiable reward obtained at the end of reasoning traces. However, such methods optimize only the final performance under a large and fixed token budget, which hinders efficiency in both training and deployment. In this work, we present a novel framework, AnytimeReasoner, to optimize anytime reasoning performance, which aims to improve token efficiency and the flexibility of reasoning under varying token budget constraints. To achieve this, we truncate the complete thinking process to fit within sampled token budgets from a prior distribution, compelling the model to summarize the optimal answer for each truncated thinking for verification. This introduces verifiable dense rewards into the reasoning process, facilitating more effective credit assignment in RL optimization. We then optimize the thinking and summary policies in a decoupled manner to maximize the cumulative reward. Additionally, we introduce a novel variance reduction technique, Budget Relative Policy Optimization (BRPO), to enhance the robustness and efficiency of the learning process when reinforcing the thinking policy. Empirical results in mathematical reasoning tasks demonstrate that our method consistently outperforms GRPO across all thinking budgets under various prior distributions, enhancing both training and token efficiency.
Understanding R1-Zero-Like Training: A Critical Perspective
Mar 26, 2025



DeepSeek-R1-Zero has shown that reinforcement learning (RL) at scale can directly enhance the reasoning capabilities of LLMs without supervised fine-tuning. In this work, we critically examine R1-Zero-like training by analyzing its two core components: base models and RL. We investigate a wide range of base models, including DeepSeek-V3-Base, to understand how pretraining characteristics influence RL performance. Our analysis reveals that DeepSeek-V3-Base already exhibit ''Aha moment'', while Qwen2.5 base models demonstrate strong reasoning capabilities even without prompt templates, suggesting potential pretraining biases. Additionally, we identify an optimization bias in Group Relative Policy Optimization (GRPO), which artificially increases response length (especially for incorrect outputs) during training. To address this, we introduce Dr. GRPO, an unbiased optimization method that improves token efficiency while maintaining reasoning performance. Leveraging these insights, we present a minimalist R1-Zero recipe that achieves 43.3% accuracy on AIME 2024 with a 7B base model, establishing a new state-of-the-art. Our code is available at https://github.com/sail-sg/understand-r1-zero.
PipeOffload: Improving Scalability of Pipeline Parallelism with Memory Optimization
Mar 03, 2025



Pipeline parallelism (PP) is widely used for training large language models (LLMs), yet its scalability is often constrained by high activation memory consumption as the number of in-flight microbatches grows with the degree of PP. In this paper, we focus on addressing this challenge by leveraging the under-explored memory offload strategy in PP. With empirical study, we discover that in the majority of standard configurations, at least half, and potentially all, of the activations can be offloaded with negligible overhead. In the cases where full overload is not possible, we introduce a novel selective offload strategy that decreases peak activation memory in a better-than-linear manner. Furthermore, we integrate memory offload with other techniques to jointly consider overall throughput and memory limitation. Our experiments proves that the per-device activation memory effectively reduces with the total number of stages, making PP a stronger alternative than TP, offering up to a 19\% acceleration with even lower memory consumption. The implementation is open-sourced at \href{https://github.com/sail-sg/zero-bubble-pipeline-parallelism}{this url}.
Pipeline Parallelism with Controllable Memory
May 24, 2024Pipeline parallelism has been widely explored, but most existing schedules lack a systematic methodology. In this paper, we propose a framework to decompose pipeline schedules as repeating a building block and we show that the lifespan of the building block decides the peak activation memory of the pipeline schedule. Guided by the observations, we find that almost all existing pipeline schedules, to the best of our knowledge, are memory inefficient. To address this, we introduce a family of memory efficient building blocks with controllable activation memory, which can reduce the peak activation memory to 1/2 of 1F1B without sacrificing efficiency, and even to 1/3 with comparable throughput. We can also achieve almost zero pipeline bubbles while maintaining the same activation memory as 1F1B. Our evaluations demonstrate that in pure pipeline parallelism settings, our methods outperform 1F1B by from 7% to 55% in terms of throughput. When employing a grid search over hybrid parallelism hyperparameters in practical scenarios, our proposed methods demonstrate a 16% throughput improvement over the 1F1B baseline for large language models.
SCC: an efficient deep reinforcement learning agent mastering the game of StarCraft II
Dec 24, 2020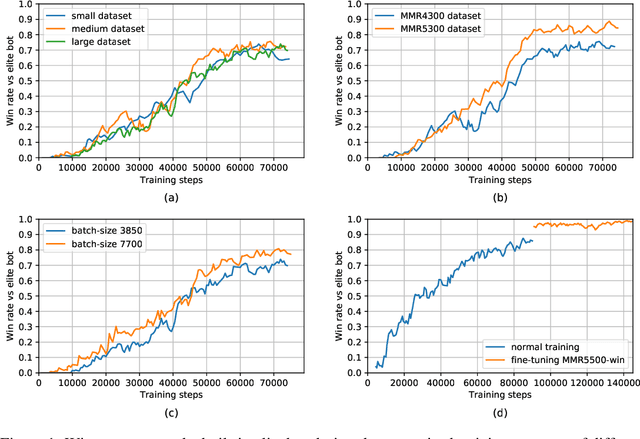
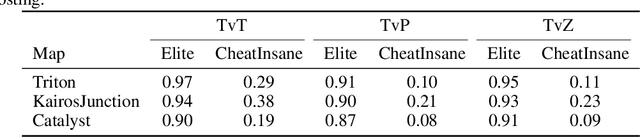
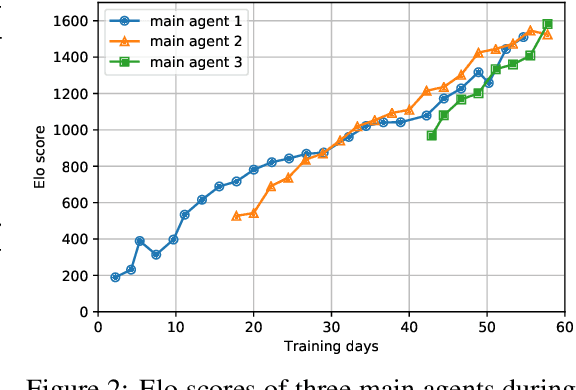
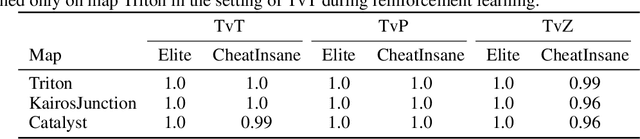
AlphaStar, the AI that reaches GrandMaster level in StarCraft II, is a remarkable milestone demonstrating what deep reinforcement learning can achieve in complex Real-Time Strategy (RTS) games. However, the complexities of the game, algorithms and systems, and especially the tremendous amount of computation needed are big obstacles for the community to conduct further research in this direction. We propose a deep reinforcement learning agent, StarCraft Commander (SCC). With order of magnitude less computation, it demonstrates top human performance defeating GrandMaster players in test matches and top professional players in a live event. Moreover, it shows strong robustness to various human strategies and discovers novel strategies unseen from human plays. In this paper, we will share the key insights and optimizations on efficient imitation learning and reinforcement learning for StarCraft II full game.
Artificial Intelligence for Prosthetics - challenge solutions
Feb 07, 2019
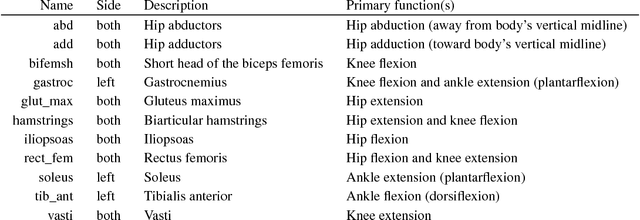
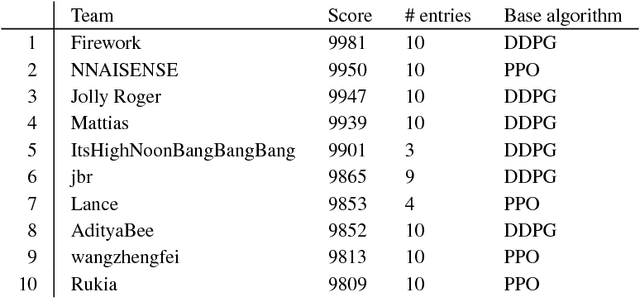

In the NeurIPS 2018 Artificial Intelligence for Prosthetics challenge, participants were tasked with building a controller for a musculoskeletal model with a goal of matching a given time-varying velocity vector. Top participants were invited to describe their algorithms. In this work, we describe the challenge and present thirteen solutions that used deep reinforcement learning approaches. Many solutions use similar relaxations and heuristics, such as reward shaping, frame skipping, discretization of the action space, symmetry, and policy blending. However, each team implemented different modifications of the known algorithms by, for example, dividing the task into subtasks, learning low-level control, or by incorporating expert knowledge and using imitation learning.