 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeGym-V: A Unified Vision Environment System for Agentic Vision Research
Mar 17, 2026As agentic systems increasingly rely on reinforcement learning from verifiable rewards, standardized ``gym'' infrastructure has become essential for rapid iteration, reproducibility, and fair comparison. Vision agents lack such infrastructure, limiting systematic study of what drives their learning and where current models fall short. We introduce \textbf{Gym-V}, a unified platform of 179 procedurally generated visual environments across 10 domains with controllable difficulty, enabling controlled experiments that were previously infeasible across fragmented toolkits. Using it, we find that observation scaffolding is more decisive for training success than the choice of RL algorithm, with captions and game rules determining whether learning succeeds at all. Cross-domain transfer experiments further show that training on diverse task categories generalizes broadly while narrow training can cause negative transfer, with multi-turn interaction amplifying all of these effects. Gym-V is released as a convenient foundation for training environments and evaluation toolkits, aiming to accelerate future research on agentic VLMs.
RetroAgent: From Solving to Evolving via Retrospective Dual Intrinsic Feedback
Mar 12, 2026Standard reinforcement learning (RL) for large language model (LLM)-based agents typically optimizes extrinsic task-success rewards, prioritizing one-off task solving over continual adaptation. As a result, agents may converge to suboptimal policies due to limited exploration, and accumulated experience remains implicitly stored in model parameters, hindering efficient experiential learning. Inspired by humans' capacity for retrospective self-improvement, we introduce RetroAgent, an online RL framework that enables agents to master complex interactive environments not only by solving, but also by evolving under the joint guidance of extrinsic task-success rewards and retrospective dual intrinsic feedback. Concretely, RetroAgent features a hindsight self-reflection mechanism that produces: (1) intrinsic numerical feedback, which tracks incremental subtask completion relative to prior attempts to reward promising exploration; and (2) intrinsic language feedback, which distills reusable lessons into a memory buffer retrieved via our proposed Similarity & Utility-Aware Upper Confidence Bound (SimUtil-UCB) strategy, jointly balancing relevance, utility, and exploration. Extensive experiments across four challenging agentic tasks show that RetroAgent achieves state-of-the-art (SOTA) performance, substantially outperforming RL fine-tuning, memory-augmented RL, exploration-guided RL, and meta-RL methods -- e.g., exceeding Group Relative Policy Optimization (GRPO)-trained agents by +18.3% on ALFWorld, +15.4% on WebShop, +27.1% on Sokoban, and +8.9% on MineSweeper -- while maintaining strong test-time adaptation and out-of-distribution generalization.
Rethinking the Trust Region in LLM Reinforcement Learning
Feb 04, 2026Reinforcement learning (RL) has become a cornerstone for fine-tuning Large Language Models (LLMs), with Proximal Policy Optimization (PPO) serving as the de facto standard algorithm. Despite its ubiquity, we argue that the core ratio clipping mechanism in PPO is structurally ill-suited for the large vocabularies inherent to LLMs. PPO constrains policy updates based on the probability ratio of sampled tokens, which serves as a noisy single-sample Monte Carlo estimate of the true policy divergence. This creates a sub-optimal learning dynamic: updates to low-probability tokens are aggressively over-penalized, while potentially catastrophic shifts in high-probability tokens are under-constrained, leading to training inefficiency and instability. To address this, we propose Divergence Proximal Policy Optimization (DPPO), which substitutes heuristic clipping with a more principled constraint based on a direct estimate of policy divergence (e.g., Total Variation or KL). To avoid huge memory footprint, we introduce the efficient Binary and Top-K approximations to capture the essential divergence with negligible overhead. Extensive empirical evaluations demonstrate that DPPO achieves superior training stability and efficiency compared to existing methods, offering a more robust foundation for RL-based LLM fine-tuning.
A DVL Aided Loosely Coupled Inertial Navigation Strategy for AUVs with Attitude Error Modeling and Variance Propagation
Jan 27, 2026In underwater navigation systems, strap-down inertial navigation system/Doppler velocity log (SINS/DVL)-based loosely coupled architectures are widely adopted. Conventional approaches project DVL velocities from the body coordinate system to the navigation coordinate system using SINS-derived attitude; however, accumulated attitude estimation errors introduce biases into velocity projection and degrade navigation performance during long-term operation. To address this issue, two complementary improvements are introduced. First, a vehicle attitude error-aware DVL velocity transformation model is formulated by incorporating attitude error terms into the observation equation to reduce projection-induced velocity bias. Second, a covariance matrix-based variance propagation method is developed to transform DVL measurement uncertainty across coordinate systems, introducing an expectation-based attitude error compensation term to achieve statistically consistent noise modeling. Simulation and field experiment results demonstrate that both improvements individually enhance navigation accuracy and confirm that accumulated attitude errors affect both projected velocity measurements and their associated uncertainty. When jointly applied, long-term error divergence is effectively suppressed. Field experimental results show that the proposed approach achieves a 78.3% improvement in 3D position RMSE and a 71.8% reduction in the maximum component-wise position error compared with the baseline IMU+DVL method, providing a robust solution for improving long-term SINS/DVL navigation performance.
RollArt: Scaling Agentic RL Training via Disaggregated Infrastructure
Dec 27, 2025Agentic Reinforcement Learning (RL) enables Large Language Models (LLMs) to perform autonomous decision-making and long-term planning. Unlike standard LLM post-training, agentic RL workloads are highly heterogeneous, combining compute-intensive prefill phases, bandwidth-bound decoding, and stateful, CPU-heavy environment simulations. We argue that efficient agentic RL training requires disaggregated infrastructure to leverage specialized, best-fit hardware. However, naive disaggregation introduces substantial synchronization overhead and resource underutilization due to the complex dependencies between stages. We present RollArc, a distributed system designed to maximize throughput for multi-task agentic RL on disaggregated infrastructure. RollArc is built on three core principles: (1) hardware-affinity workload mapping, which routes compute-bound and bandwidth-bound tasks to bestfit GPU devices, (2) fine-grained asynchrony, which manages execution at the trajectory level to mitigate resource bubbles, and (3) statefulness-aware computation, which offloads stateless components (e.g., reward models) to serverless infrastructure for elastic scaling. Our results demonstrate that RollArc effectively improves training throughput and achieves 1.35-2.05\(\times\) end-to-end training time reduction compared to monolithic and synchronous baselines. We also evaluate RollArc by training a hundreds-of-billions-parameter MoE model for Qoder product on an Alibaba cluster with more than 3,000 GPUs, further demonstrating RollArc scalability and robustness. The code is available at https://github.com/alibaba/ROLL.
Defeating the Training-Inference Mismatch via FP16
Oct 30, 2025Reinforcement learning (RL) fine-tuning of large language models (LLMs) often suffers from instability due to the numerical mismatch between the training and inference policies. While prior work has attempted to mitigate this issue through algorithmic corrections or engineering alignments, we show that its root cause lies in the floating point precision itself. The widely adopted BF16, despite its large dynamic range, introduces large rounding errors that breaks the consistency between training and inference. In this work, we demonstrate that simply reverting to \textbf{FP16} effectively eliminates this mismatch. The change is simple, fully supported by modern frameworks with only a few lines of code change, and requires no modification to the model architecture or learning algorithm. Our results suggest that using FP16 uniformly yields more stable optimization, faster convergence, and stronger performance across diverse tasks, algorithms and frameworks. We hope these findings motivate a broader reconsideration of precision trade-offs in RL fine-tuning.
BinCtx: Multi-Modal Representation Learning for Robust Android App Behavior Detection
Oct 16, 2025Mobile app markets host millions of apps, yet undesired behaviors (e.g., disruptive ads, illegal redirection, payment deception) remain hard to catch because they often do not rely on permission-protected APIs and can be easily camouflaged via UI or metadata edits. We present BINCTX, a learning approach that builds multi-modal representations of an app from (i) a global bytecode-as-image view that captures code-level semantics and family-style patterns, (ii) a contextual view (manifested actions, components, declared permissions, URL/IP constants) indicating how behaviors are triggered, and (iii) a third-party-library usage view summarizing invocation frequencies along inter-component call paths. The three views are embedded and fused to train a contextual-aware classifier. On real-world malware and benign apps, BINCTX attains a macro F1 of 94.73%, outperforming strong baselines by at least 14.92%. It remains robust under commercial obfuscation (F1 84% post-obfuscation) and is more resistant to adversarial samples than state-of-the-art bytecode-only systems.
Language Models Can Learn from Verbal Feedback Without Scalar Rewards
Sep 26, 2025
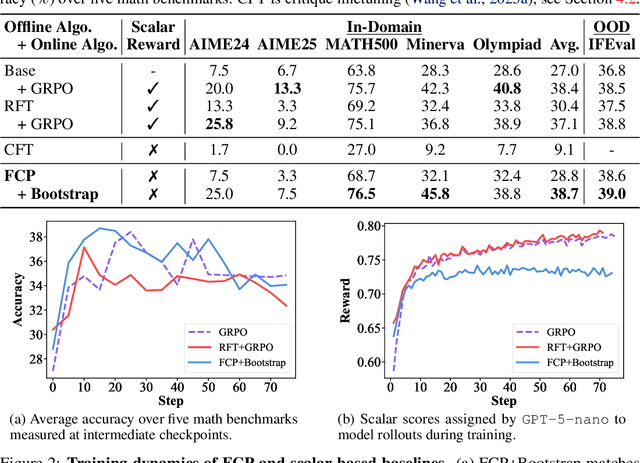
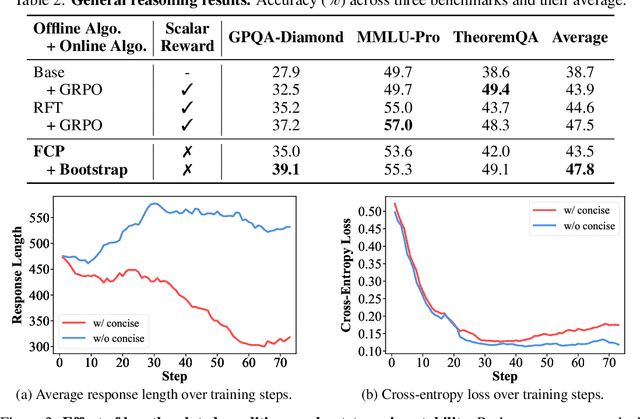
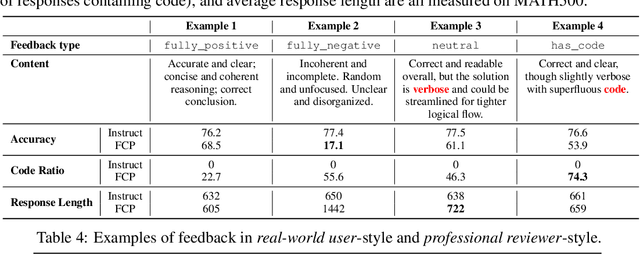
LLMs are often trained with RL from human or AI feedback, yet such methods typically compress nuanced feedback into scalar rewards, discarding much of their richness and inducing scale imbalance. We propose treating verbal feedback as a conditioning signal. Inspired by language priors in text-to-image generation, which enable novel outputs from unseen prompts, we introduce the feedback-conditional policy (FCP). FCP learns directly from response-feedback pairs, approximating the feedback-conditional posterior through maximum likelihood training on offline data. We further develop an online bootstrapping stage where the policy generates under positive conditions and receives fresh feedback to refine itself. This reframes feedback-driven learning as conditional generation rather than reward optimization, offering a more expressive way for LLMs to directly learn from verbal feedback. Our code is available at https://github.com/sail-sg/feedback-conditional-policy.
Variational Reasoning for Language Models
Sep 26, 2025



We introduce a variational reasoning framework for language models that treats thinking traces as latent variables and optimizes them through variational inference. Starting from the evidence lower bound (ELBO), we extend it to a multi-trace objective for tighter bounds and propose a forward-KL formulation that stabilizes the training of the variational posterior. We further show that rejection sampling finetuning and binary-reward RL, including GRPO, can be interpreted as local forward-KL objectives, where an implicit weighting by model accuracy naturally arises from the derivation and reveals a previously unnoticed bias toward easier questions. We empirically validate our method on the Qwen 2.5 and Qwen 3 model families across a wide range of reasoning tasks. Overall, our work provides a principled probabilistic perspective that unifies variational inference with RL-style methods and yields stable objectives for improving the reasoning ability of language models. Our code is available at https://github.com/sail-sg/variational-reasoning.
Hallucination at a Glance: Controlled Visual Edits and Fine-Grained Multimodal Learning
Jun 08, 2025Multimodal large language models (MLLMs) have achieved strong performance on vision-language tasks but still struggle with fine-grained visual differences, leading to hallucinations or missed semantic shifts. We attribute this to limitations in both training data and learning objectives. To address these issues, we propose a controlled data generation pipeline that produces minimally edited image pairs with semantically aligned captions. Using this pipeline, we construct the Micro Edit Dataset (MED), containing over 50K image-text pairs spanning 11 fine-grained edit categories, including attribute, count, position, and object presence changes. Building on MED, we introduce a supervised fine-tuning (SFT) framework with a feature-level consistency loss that promotes stable visual embeddings under small edits. We evaluate our approach on the Micro Edit Detection benchmark, which includes carefully balanced evaluation pairs designed to test sensitivity to subtle visual variations across the same edit categories. Our method improves difference detection accuracy and reduces hallucinations compared to strong baselines, including GPT-4o. Moreover, it yields consistent gains on standard vision-language tasks such as image captioning and visual question answering. These results demonstrate the effectiveness of combining targeted data and alignment objectives for enhancing fine-grained visual reasoning in MLLMs.