 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeQUEST: Training Frontier Deep Research Agents with Fully Synthetic Tasks
May 22, 2026Deep research agents extend the role of search engines from retrieving keyword-matched pages to synthesizing knowledge, fundamentally changing how humans interact with information. However, frontier systems remain proprietary, while existing open agents often generalize poorly across different task types, leaving unclear how to train a broadly capable deep research agent. We release QUEST, a family of open models (ranging from 2B to 35B) that serve as general-purpose deep research agents designed to handle a wide range of long-horizon search tasks, with strong capabilities in fact seeking, citation grounding, and report synthesis. To build QUEST, we propose an effective training recipe combining mid-training, supervised fine-tuning, and reinforcement learning. Central to this recipe is a curated data synthesis pipeline based on unified rubric trees, which applies to different task types and enables synthesizing training data with verifiable rewards without human annotation. In addition, QUEST incorporates a built-in context management mechanism that enables effective long-horizon reasoning and knowledge synthesis. Using only 8K synthesized tasks, QUEST approaches or even surpasses frontier closed-source agents across eight deep research benchmarks spanning diverse task types, and achieves the best overall performance among recent open-weight agents. We released everything: models, data, and training scripts.
Recursive Agent Optimization
May 07, 2026We introduce Recursive Agent Optimization (RAO), a reinforcement learning approach for training recursive agents: agents that can spawn and delegate sub-tasks to new instantiations of themselves recursively. Recursive agents implement an inference-time scaling algorithm that naturally allows agents to scale to longer contexts and generalize to more difficult problems via divide-and-conquer. RAO provides a method to train models to best take advantage of such recursive inference, teaching agents when and how to delegate and communicate. We find that recursive agents trained in this way enjoy better training efficiency, can scale to tasks that go beyond the model's context window, generalize to tasks much harder than the ones the agent was trained on, and can enjoy reduced wall-clock time compared to single-agent systems.
Residual-loss Anomaly Analysis of Physics-Informed Neural Networks: An Inverse Method for Change-point Detection in Nonlinear Dynamical Systems with Regime Switching
Apr 28, 2026Nonlinear dynamical systems with regime transitions are typically described by ordinary differential equations with jumping parameters parameters. Traditional methods often treat change-point detection and parameter estimation as separate tasks, ignoring the inherent coupling between them. To address this, we propose residual-loss anomaly analysis of physics-informed neural networks, a unified framework that leverages dynamical consistency within the physics-informed learning paradigm. This approach jointly infers piecewise parameters and transition points under a single set of constraints. The method follows a two-stage strategy: First, local physical residuals are analyzed through overlapping subinterval decomposition. When a subinterval spans a true transition point, the residual exhibits a distinct structural elevation in noise-free conditions, which has a non-zero lower bound, enabling effective localization of potential transition intervals. Second, within our framework, change-point locations and piecewise parameters are integrated into a unified physical loss function for joint optimization, enabling simultaneous identification. Experiments on benchmark nonlinear dynamical systems, including Malthusian and logistic growth models, Van der Pol oscillator, Lotka-Volterra model and Lorenz system, demonstrate that the proposed method outperforms traditional decoupled approaches in both change-point localization and parameter estimation accuracy. This study provides an efficient, unified solution for structurally coupled inverse problems in nonlinear dynamical systems with regime switching.
Parameters Inference for Nonlinear Wave Equations with Markovian Switching
Aug 12, 2024Traditional partial differential equations with constant coefficients often struggle to capture abrupt changes in real-world phenomena, leading to the development of variable coefficient PDEs and Markovian switching models. Recently, research has introduced the concept of PDEs with Markov switching models, established their well-posedness and presented numerical methods. However, there has been limited discussion on parameter estimation for the jump coefficients in these models. This paper addresses this gap by focusing on parameter inference for the wave equation with Markovian switching. We propose a Bayesian statistical framework using discrete sparse Bayesian learning to establish its convergence and a uniform error bound. Our method requires fewer assumptions and enables independent parameter inference for each segment by allowing different underlying structures for the parameter estimation problem within each segmented time interval. The effectiveness of our approach is demonstrated through three numerical cases, which involve noisy spatiotemporal data from different wave equations with Markovian switching. The results show strong performance in parameter estimation for variable coefficient PDEs.
Machine Learning for Complex Systems with Abnormal Pattern by Exception Maximization Outlier Detection Method
Jul 05, 2024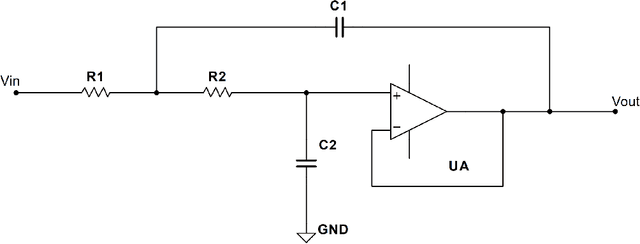
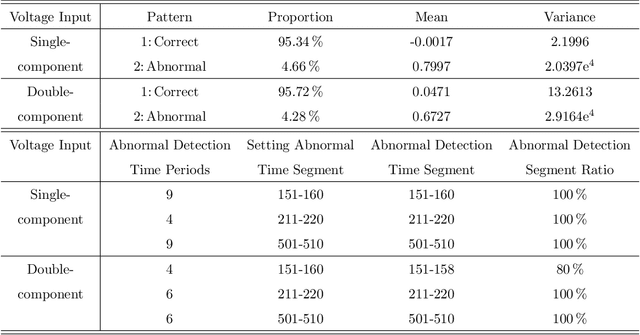
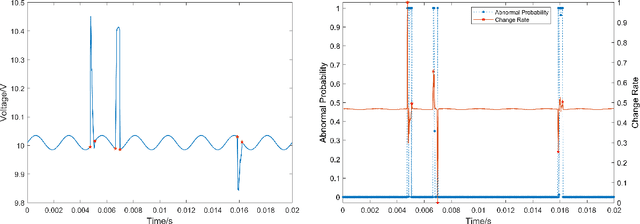

This paper proposes a novel fast online methodology for outlier detection called the exception maximization outlier detection method(EMODM), which employs probabilistic models and statistical algorithms to detect abnormal patterns from the outputs of complex systems. The EMODM is based on a two-state Gaussian mixture model and demonstrates strong performance in probability anomaly detection working on real-time raw data rather than using special prior distribution information. We confirm this using the synthetic data from two numerical cases. For the real-world data, we have detected the short circuit pattern of the circuit system using EMODM by the current and voltage output of a three-phase inverter. The EMODM also found an abnormal period due to COVID-19 in the insured unemployment data of 53 regions in the United States from 2000 to 2024. The application of EMODM to these two real-life datasets demonstrated the effectiveness and accuracy of our algorithm.
Entity Divider with Language Grounding in Multi-Agent Reinforcement Learning
Oct 25, 2022We investigate the use of natural language to drive the generalization of policies in multi-agent settings. Unlike single-agent settings, the generalization of policies should also consider the influence of other agents. Besides, with the increasing number of entities in multi-agent settings, more agent-entity interactions are needed for language grounding, and the enormous search space could impede the learning process. Moreover, given a simple general instruction,e.g., beating all enemies, agents are required to decompose it into multiple subgoals and figure out the right one to focus on. Inspired by previous work, we try to address these issues at the entity level and propose a novel framework for language grounding in multi-agent reinforcement learning, entity divider (EnDi). EnDi enables agents to independently learn subgoal division at the entity level and act in the environment based on the associated entities. The subgoal division is regularized by opponent modeling to avoid subgoal conflicts and promote coordinated strategies. Empirically, EnDi demonstrates the strong generalization ability to unseen games with new dynamics and expresses the superiority over existing methods.
WILD-SCAV: Benchmarking FPS Gaming AI on Unity3D-based Environments
Oct 14, 2022
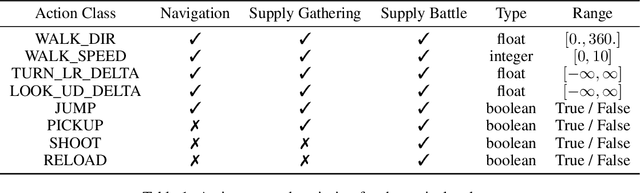

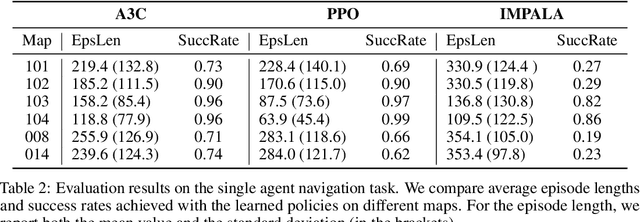
Recent advances in deep reinforcement learning (RL) have demonstrated complex decision-making capabilities in simulation environments such as Arcade Learning Environment, MuJoCo, and ViZDoom. However, they are hardly extensible to more complicated problems, mainly due to the lack of complexity and variations in the environments they are trained and tested on. Furthermore, they are not extensible to an open-world environment to facilitate long-term exploration research. To learn realistic task-solving capabilities, we need to develop an environment with greater diversity and complexity. We developed WILD-SCAV, a powerful and extensible environment based on a 3D open-world FPS (First-Person Shooter) game to bridge the gap. It provides realistic 3D environments of variable complexity, various tasks, and multiple modes of interaction, where agents can learn to perceive 3D environments, navigate and plan, compete and cooperate in a human-like manner. WILD-SCAV also supports different complexities, such as configurable maps with different terrains, building structures and distributions, and multi-agent settings with cooperative and competitive tasks. The experimental results on configurable complexity, multi-tasking, and multi-agent scenarios demonstrate the effectiveness of WILD-SCAV in benchmarking various RL algorithms, as well as it is potential to give rise to intelligent agents with generalized task-solving abilities. The link to our open-sourced code can be found here https://github.com/inspirai/wilderness-scavenger.
MA2QL: A Minimalist Approach to Fully Decentralized Multi-Agent Reinforcement Learning
Sep 17, 2022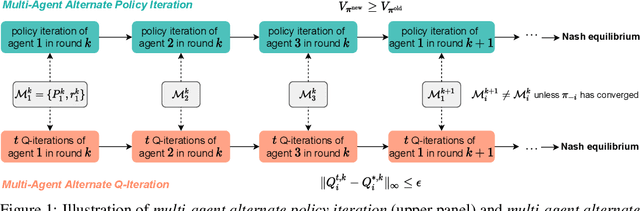
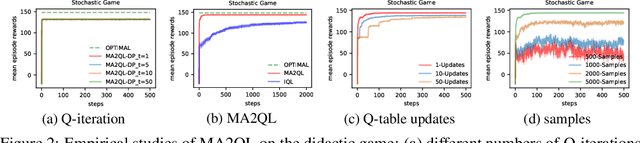
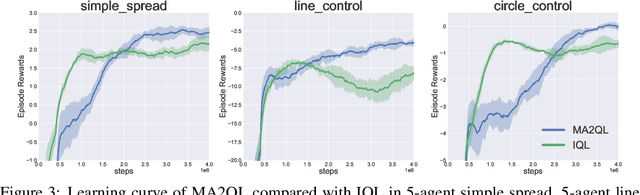
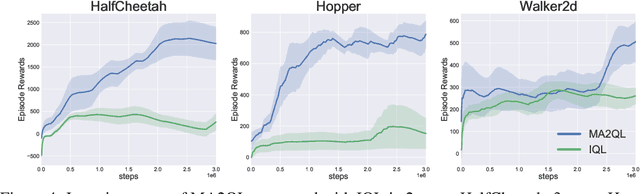
Decentralized learning has shown great promise for cooperative multi-agent reinforcement learning (MARL). However, non-stationarity remains a significant challenge in decentralized learning. In the paper, we tackle the non-stationarity problem in the simplest and fundamental way and propose \textit{multi-agent alternate Q-learning} (MA2QL), where agents take turns to update their Q-functions by Q-learning. MA2QL is a \textit{minimalist} approach to fully decentralized cooperative MARL but is theoretically grounded. We prove that when each agent guarantees a $\varepsilon$-convergence at each turn, their joint policy converges to a Nash equilibrium. In practice, MA2QL only requires minimal changes to independent Q-learning (IQL). We empirically evaluate MA2QL on a variety of cooperative multi-agent tasks. Results show MA2QL consistently outperforms IQL, which verifies the effectiveness of MA2QL, despite such minimal changes.
SCC: an efficient deep reinforcement learning agent mastering the game of StarCraft II
Dec 24, 2020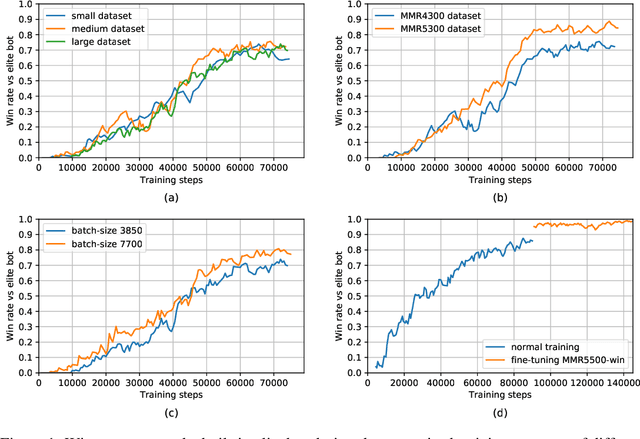
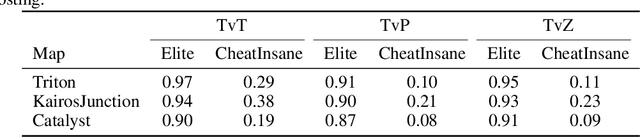
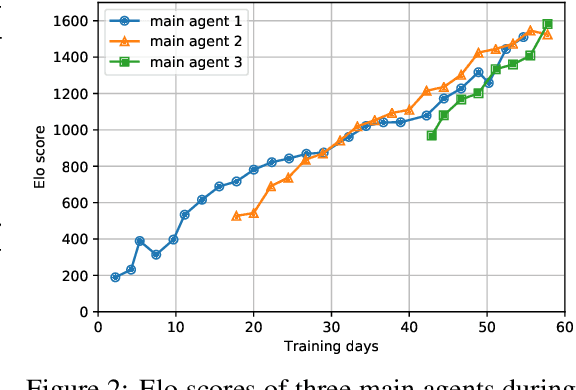
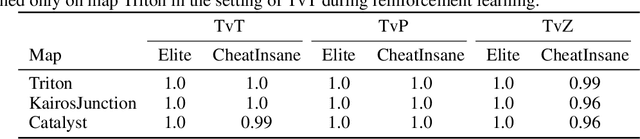
AlphaStar, the AI that reaches GrandMaster level in StarCraft II, is a remarkable milestone demonstrating what deep reinforcement learning can achieve in complex Real-Time Strategy (RTS) games. However, the complexities of the game, algorithms and systems, and especially the tremendous amount of computation needed are big obstacles for the community to conduct further research in this direction. We propose a deep reinforcement learning agent, StarCraft Commander (SCC). With order of magnitude less computation, it demonstrates top human performance defeating GrandMaster players in test matches and top professional players in a live event. Moreover, it shows strong robustness to various human strategies and discovers novel strategies unseen from human plays. In this paper, we will share the key insights and optimizations on efficient imitation learning and reinforcement learning for StarCraft II full game.
State estimation under non-Gaussian Levy noise: A modified Kalman filtering method
Mar 10, 2013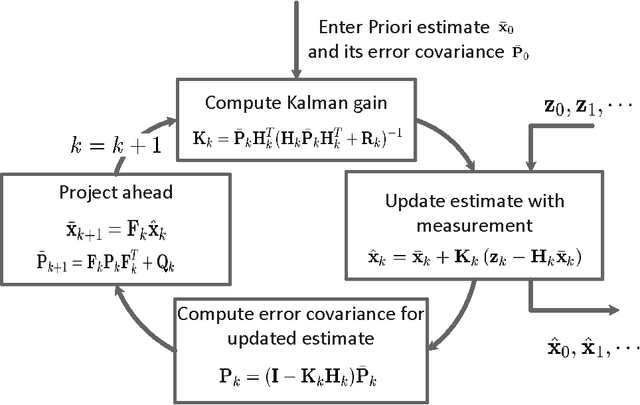
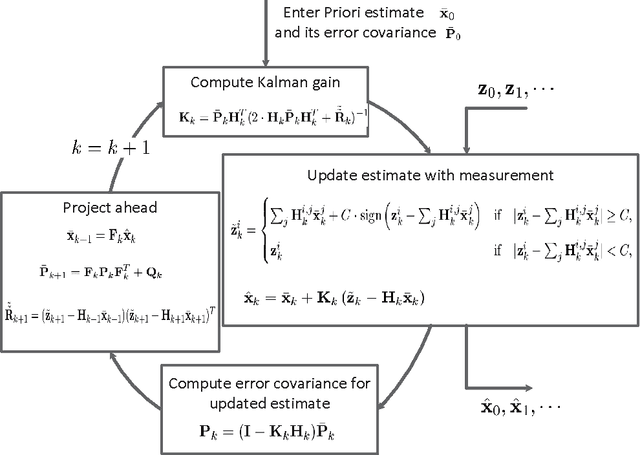
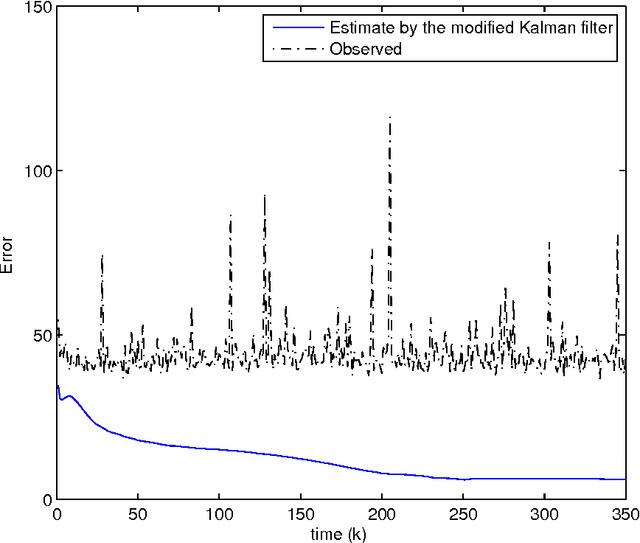
The Kalman filter is extensively used for state estimation for linear systems under Gaussian noise. When non-Gaussian L\'evy noise is present, the conventional Kalman filter may fail to be effective due to the fact that the non-Gaussian L\'evy noise may have infinite variance. A modified Kalman filter for linear systems with non-Gaussian L\'evy noise is devised. It works effectively with reasonable computational cost. Simulation results are presented to illustrate this non-Gaussian filtering method.