 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMA2QL: A Minimalist Approach to Fully Decentralized Multi-Agent Reinforcement Learning
Paper and Code
Sep 17, 2022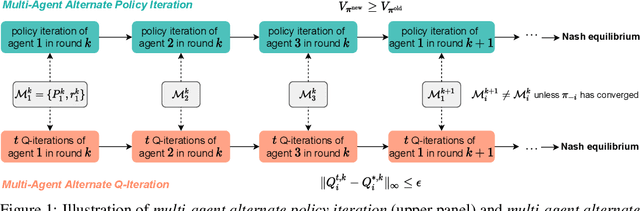
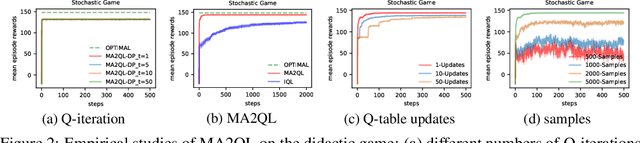
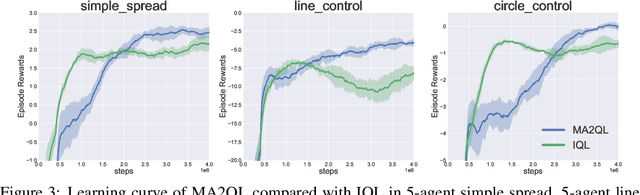
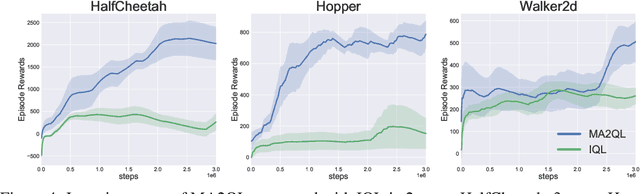
Decentralized learning has shown great promise for cooperative multi-agent reinforcement learning (MARL). However, non-stationarity remains a significant challenge in decentralized learning. In the paper, we tackle the non-stationarity problem in the simplest and fundamental way and propose \textit{multi-agent alternate Q-learning} (MA2QL), where agents take turns to update their Q-functions by Q-learning. MA2QL is a \textit{minimalist} approach to fully decentralized cooperative MARL but is theoretically grounded. We prove that when each agent guarantees a $\varepsilon$-convergence at each turn, their joint policy converges to a Nash equilibrium. In practice, MA2QL only requires minimal changes to independent Q-learning (IQL). We empirically evaluate MA2QL on a variety of cooperative multi-agent tasks. Results show MA2QL consistently outperforms IQL, which verifies the effectiveness of MA2QL, despite such minimal changes.