 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCORD: Generalizable Cooperation via Role Diversity
Jan 04, 2025



Cooperative multi-agent reinforcement learning (MARL) aims to develop agents that can collaborate effectively. However, most cooperative MARL methods overfit training agents, making learned policies not generalize well to unseen collaborators, which is a critical issue for real-world deployment. Some methods attempt to address the generalization problem but require prior knowledge or predefined policies of new teammates, limiting real-world applications. To this end, we propose a hierarchical MARL approach to enable generalizable cooperation via role diversity, namely CORD. CORD's high-level controller assigns roles to low-level agents by maximizing the role entropy with constraints. We show this constrained objective can be decomposed into causal influence in role that enables reasonable role assignment, and role heterogeneity that yields coherent, non-redundant role clusters. Evaluated on a variety of cooperative multi-agent tasks, CORD achieves better performance than baselines, especially in generalization tests. Ablation studies further demonstrate the efficacy of the constrained objective in generalizable cooperation.
AuctionNet: A Novel Benchmark for Decision-Making in Large-Scale Games
Dec 14, 2024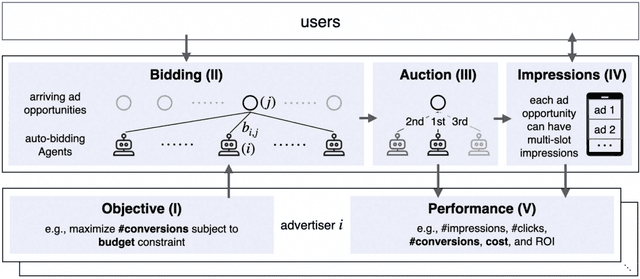
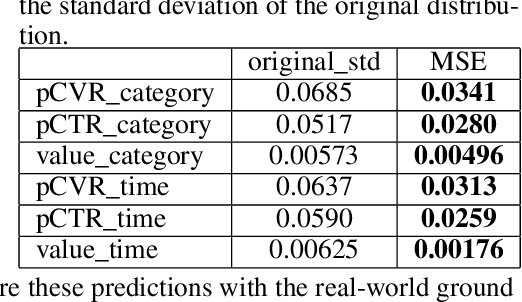
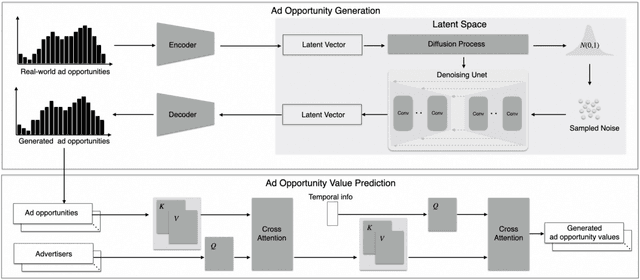

Decision-making in large-scale games is an essential research area in artificial intelligence (AI) with significant real-world impact. However, the limited access to realistic large-scale game environments has hindered research progress in this area. In this paper, we present \textbf{AuctionNet}, a benchmark for bid decision-making in large-scale ad auctions derived from a real-world online advertising platform. AuctionNet is composed of three parts: an ad auction environment, a pre-generated dataset based on the environment, and performance evaluations of several baseline bid decision-making algorithms. More specifically, the environment effectively replicates the integrity and complexity of real-world ad auctions through the interaction of several modules: the ad opportunity generation module employs deep generative models to bridge the gap between simulated and real-world data while mitigating the risk of sensitive data exposure; the bidding module implements diverse auto-bidding agents trained with different decision-making algorithms; and the auction module is anchored in the classic Generalized Second Price (GSP) auction but also allows for customization of auction mechanisms as needed. To facilitate research and provide insights into the game environment, we have also pre-generated a substantial dataset based on the environment. The dataset contains trajectories involving 48 diverse agents competing with each other, totaling over 500 million records and occupying 80GB of storage. Performance evaluations of baseline algorithms such as linear programming, reinforcement learning, and generative models for bid decision-making are also presented as part of AuctionNet. We note that AuctionNet is applicable not only to research on bid decision-making algorithms in ad auctions but also to the general area of decision-making in large-scale games.
Fully Decentralized Cooperative Multi-Agent Reinforcement Learning: A Survey
Jan 10, 2024Cooperative multi-agent reinforcement learning is a powerful tool to solve many real-world cooperative tasks, but restrictions of real-world applications may require training the agents in a fully decentralized manner. Due to the lack of information about other agents, it is challenging to derive algorithms that can converge to the optimal joint policy in a fully decentralized setting. Thus, this research area has not been thoroughly studied. In this paper, we seek to systematically review the fully decentralized methods in two settings: maximizing a shared reward of all agents and maximizing the sum of individual rewards of all agents, and discuss open questions and future research directions.
Decentralized Policy Optimization
Nov 06, 2022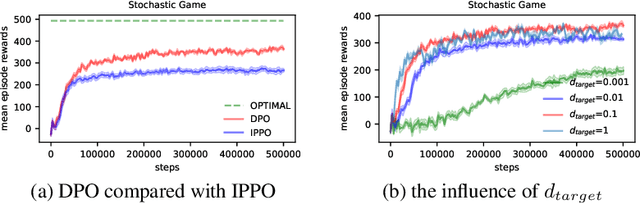
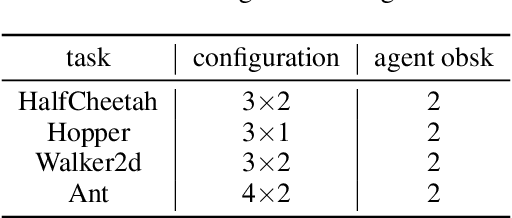
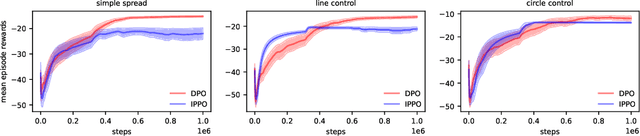
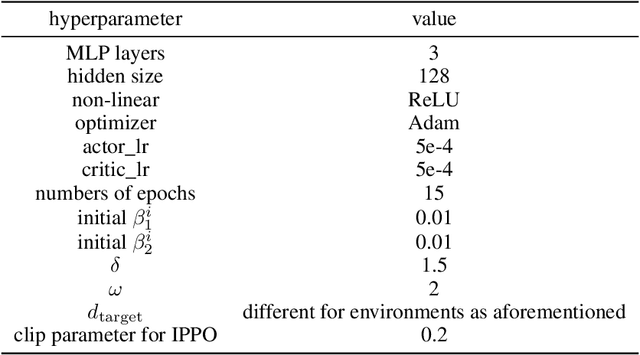
The study of decentralized learning or independent learning in cooperative multi-agent reinforcement learning has a history of decades. Recently empirical studies show that independent PPO (IPPO) can obtain good performance, close to or even better than the methods of centralized training with decentralized execution, in several benchmarks. However, decentralized actor-critic with convergence guarantee is still open. In this paper, we propose \textit{decentralized policy optimization} (DPO), a decentralized actor-critic algorithm with monotonic improvement and convergence guarantee. We derive a novel decentralized surrogate for policy optimization such that the monotonic improvement of joint policy can be guaranteed by each agent \textit{independently} optimizing the surrogate. In practice, this decentralized surrogate can be realized by two adaptive coefficients for policy optimization at each agent. Empirically, we compare DPO with IPPO in a variety of cooperative multi-agent tasks, covering discrete and continuous action spaces, and fully and partially observable environments. The results show DPO outperforms IPPO in most tasks, which can be the evidence for our theoretical results.
Multi-Agent Automated Machine Learning
Oct 17, 2022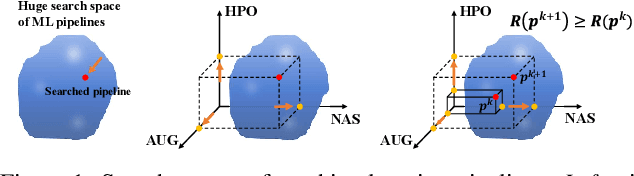
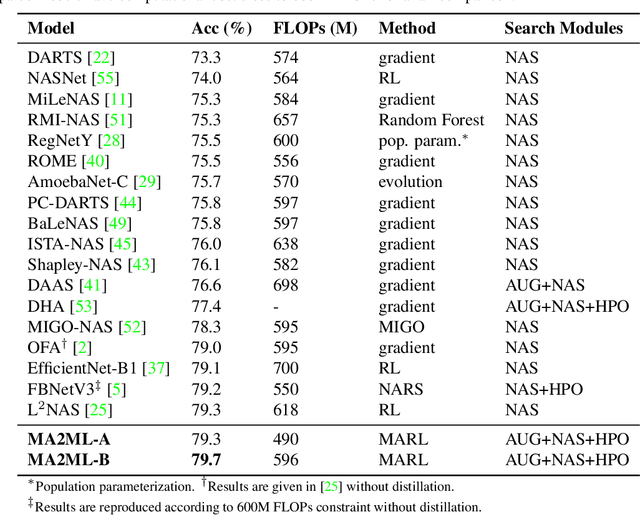
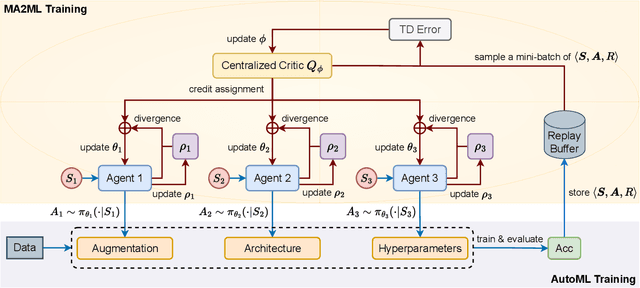
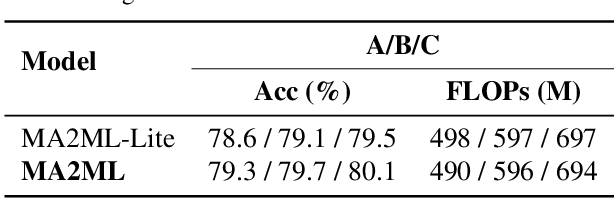
In this paper, we propose multi-agent automated machine learning (MA2ML) with the aim to effectively handle joint optimization of modules in automated machine learning (AutoML). MA2ML takes each machine learning module, such as data augmentation (AUG), neural architecture search (NAS), or hyper-parameters (HPO), as an agent and the final performance as the reward, to formulate a multi-agent reinforcement learning problem. MA2ML explicitly assigns credit to each agent according to its marginal contribution to enhance cooperation among modules, and incorporates off-policy learning to improve search efficiency. Theoretically, MA2ML guarantees monotonic improvement of joint optimization. Extensive experiments show that MA2ML yields the state-of-the-art top-1 accuracy on ImageNet under constraints of computational cost, e.g., $79.7\%/80.5\%$ with FLOPs fewer than 600M/800M. Extensive ablation studies verify the benefits of credit assignment and off-policy learning of MA2ML.
Multi-Agent Sequential Decision-Making via Communication
Sep 26, 2022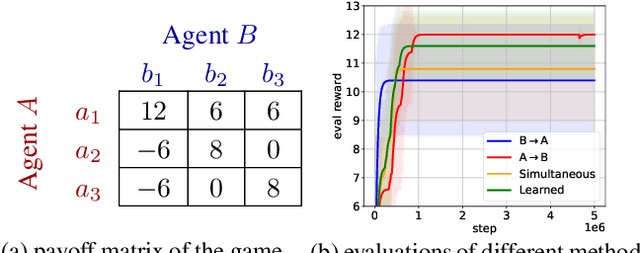

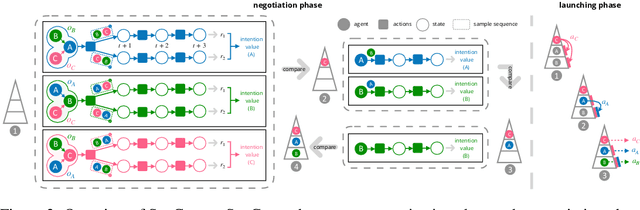

Communication helps agents to obtain information about others so that better coordinated behavior can be learned. Some existing work communicates predicted future trajectory with others, hoping to get clues about what others would do for better coordination. However, circular dependencies sometimes can occur when agents are treated synchronously so it is hard to coordinate decision-making. In this paper, we propose a novel communication scheme, Sequential Communication (SeqComm). SeqComm treats agents asynchronously (the upper-level agents make decisions before the lower-level ones) and has two communication phases. In negotiation phase, agents determine the priority of decision-making by communicating hidden states of observations and comparing the value of intention, which is obtained by modeling the environment dynamics. In launching phase, the upper-level agents take the lead in making decisions and communicate their actions with the lower-level agents. Theoretically, we prove the policies learned by SeqComm are guaranteed to improve monotonically and converge. Empirically, we show that SeqComm outperforms existing methods in various multi-agent cooperative tasks.
MA2QL: A Minimalist Approach to Fully Decentralized Multi-Agent Reinforcement Learning
Sep 17, 2022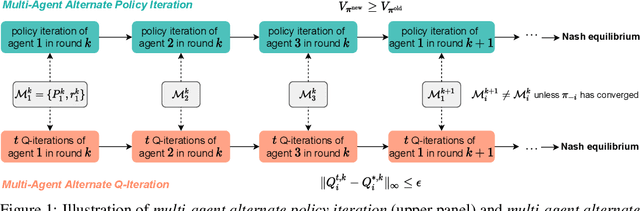
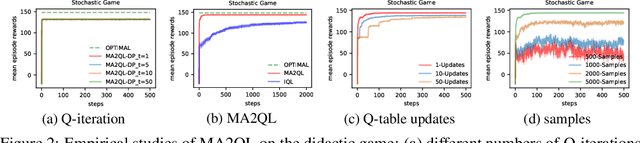
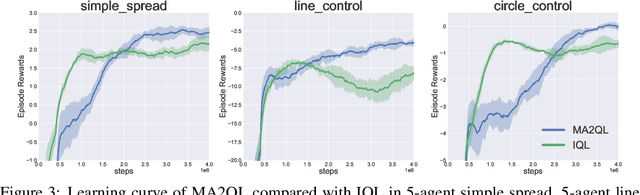
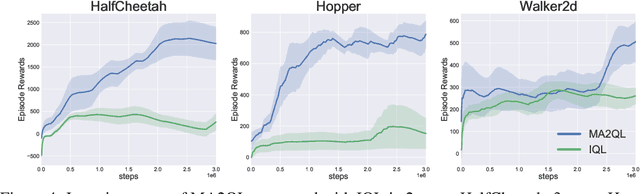
Decentralized learning has shown great promise for cooperative multi-agent reinforcement learning (MARL). However, non-stationarity remains a significant challenge in decentralized learning. In the paper, we tackle the non-stationarity problem in the simplest and fundamental way and propose \textit{multi-agent alternate Q-learning} (MA2QL), where agents take turns to update their Q-functions by Q-learning. MA2QL is a \textit{minimalist} approach to fully decentralized cooperative MARL but is theoretically grounded. We prove that when each agent guarantees a $\varepsilon$-convergence at each turn, their joint policy converges to a Nash equilibrium. In practice, MA2QL only requires minimal changes to independent Q-learning (IQL). We empirically evaluate MA2QL on a variety of cooperative multi-agent tasks. Results show MA2QL consistently outperforms IQL, which verifies the effectiveness of MA2QL, despite such minimal changes.
Divergence-Regularized Multi-Agent Actor-Critic
Oct 01, 2021
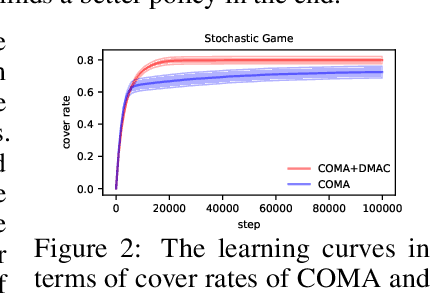
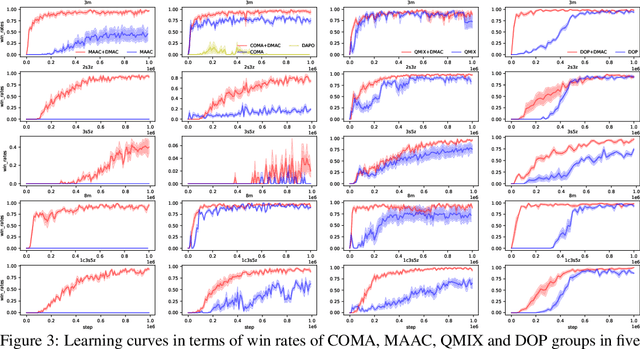
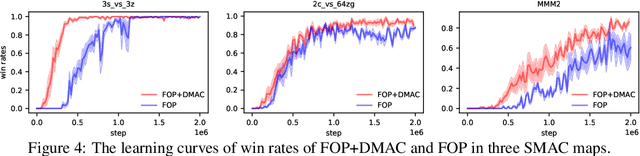
Entropy regularization is a popular method in reinforcement learning (RL). Although it has many advantages, it alters the RL objective and makes the converged policy deviate from the optimal policy of the original Markov Decision Process. Though divergence regularization has been proposed to settle this problem, it cannot be trivially applied to cooperative multi-agent reinforcement learning (MARL). In this paper, we investigate divergence regularization in cooperative MARL and propose a novel off-policy cooperative MARL framework, divergence-regularized multi-agent actor-critic (DMAC). Mathematically, we derive the update rule of DMAC which is naturally off-policy, guarantees a monotonic policy improvement and is not biased by the regularization. DMAC is a flexible framework and can be combined with many existing MARL algorithms. We evaluate DMAC in a didactic stochastic game and StarCraft Multi-Agent Challenge and empirically show that DMAC substantially improves the performance of existing MARL algorithms.