 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAuctionNet: A Novel Benchmark for Decision-Making in Large-Scale Games
Dec 14, 2024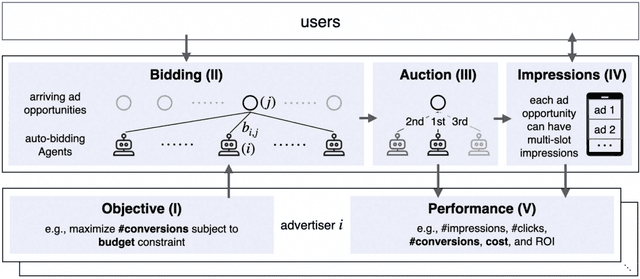
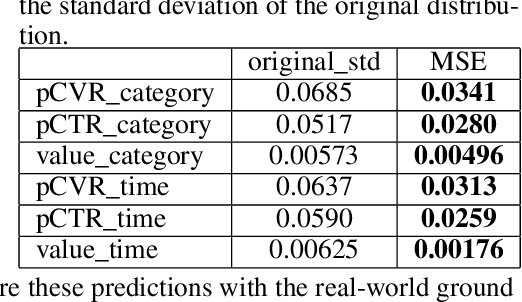
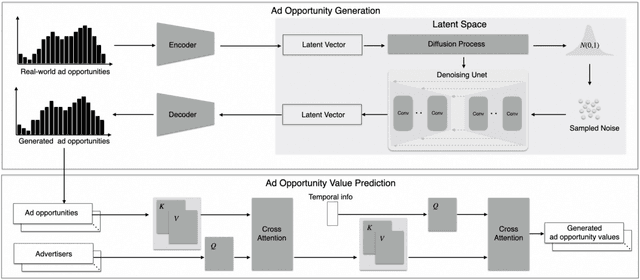

Decision-making in large-scale games is an essential research area in artificial intelligence (AI) with significant real-world impact. However, the limited access to realistic large-scale game environments has hindered research progress in this area. In this paper, we present \textbf{AuctionNet}, a benchmark for bid decision-making in large-scale ad auctions derived from a real-world online advertising platform. AuctionNet is composed of three parts: an ad auction environment, a pre-generated dataset based on the environment, and performance evaluations of several baseline bid decision-making algorithms. More specifically, the environment effectively replicates the integrity and complexity of real-world ad auctions through the interaction of several modules: the ad opportunity generation module employs deep generative models to bridge the gap between simulated and real-world data while mitigating the risk of sensitive data exposure; the bidding module implements diverse auto-bidding agents trained with different decision-making algorithms; and the auction module is anchored in the classic Generalized Second Price (GSP) auction but also allows for customization of auction mechanisms as needed. To facilitate research and provide insights into the game environment, we have also pre-generated a substantial dataset based on the environment. The dataset contains trajectories involving 48 diverse agents competing with each other, totaling over 500 million records and occupying 80GB of storage. Performance evaluations of baseline algorithms such as linear programming, reinforcement learning, and generative models for bid decision-making are also presented as part of AuctionNet. We note that AuctionNet is applicable not only to research on bid decision-making algorithms in ad auctions but also to the general area of decision-making in large-scale games.
Trajectory-wise Iterative Reinforcement Learning Framework for Auto-bidding
Feb 23, 2024



In online advertising, advertisers participate in ad auctions to acquire ad opportunities, often by utilizing auto-bidding tools provided by demand-side platforms (DSPs). The current auto-bidding algorithms typically employ reinforcement learning (RL). However, due to safety concerns, most RL-based auto-bidding policies are trained in simulation, leading to a performance degradation when deployed in online environments. To narrow this gap, we can deploy multiple auto-bidding agents in parallel to collect a large interaction dataset. Offline RL algorithms can then be utilized to train a new policy. The trained policy can subsequently be deployed for further data collection, resulting in an iterative training framework, which we refer to as iterative offline RL. In this work, we identify the performance bottleneck of this iterative offline RL framework, which originates from the ineffective exploration and exploitation caused by the inherent conservatism of offline RL algorithms. To overcome this bottleneck, we propose Trajectory-wise Exploration and Exploitation (TEE), which introduces a novel data collecting and data utilization method for iterative offline RL from a trajectory perspective. Furthermore, to ensure the safety of online exploration while preserving the dataset quality for TEE, we propose Safe Exploration by Adaptive Action Selection (SEAS). Both offline experiments and real-world experiments on Alibaba display advertising platform demonstrate the effectiveness of our proposed method.