 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeBreaking the Curse of Repulsion: Optimistic Distributionally Robust Policy Optimization for Off-Policy Generative Recommendation
Feb 11, 2026Policy-based Reinforcement Learning (RL) has established itself as the dominant paradigm in generative recommendation for optimizing sequential user interactions. However, when applied to offline historical logs, these methods suffer a critical failure: the dominance of low-quality data induces severe model collapse. We first establish the Divergence Theory of Repulsive Optimization, revealing that negative gradient updates inherently trigger exponential intensity explosion during off-policy training. This theory elucidates the inherent dilemma of existing methods, exposing their inability to reconcile variance reduction and noise imitation. To break this curse, we argue that the solution lies in rigorously identifying the latent high-quality distribution entangled within the noisy behavior policy. Accordingly, we reformulate the objective as an Optimistic Distributionally Robust Optimization (DRO) problem. Guided by this formulation, we propose Distributionally Robust Policy Optimization (DRPO). We prove that hard filtering is the exact solution to this DRO objective, enabling DRPO to optimally recover high-quality behaviors while strictly discarding divergence-inducing noise. Extensive experiments demonstrate that DRPO achieves state-of-the-art performance on mixed-quality recommendation benchmarks.
DARA: Few-shot Budget Allocation in Online Advertising via In-Context Decision Making with RL-Finetuned LLMs
Jan 21, 2026Optimizing the advertiser's cumulative value of winning impressions under budget constraints poses a complex challenge in online advertising, under the paradigm of AI-Generated Bidding (AIGB). Advertisers often have personalized objectives but limited historical interaction data, resulting in few-shot scenarios where traditional reinforcement learning (RL) methods struggle to perform effectively. Large Language Models (LLMs) offer a promising alternative for AIGB by leveraging their in-context learning capabilities to generalize from limited data. However, they lack the numerical precision required for fine-grained optimization. To address this limitation, we introduce GRPO-Adaptive, an efficient LLM post-training strategy that enhances both reasoning and numerical precision by dynamically updating the reference policy during training. Built upon this foundation, we further propose DARA, a novel dual-phase framework that decomposes the decision-making process into two stages: a few-shot reasoner that generates initial plans via in-context prompting, and a fine-grained optimizer that refines these plans using feedback-driven reasoning. This separation allows DARA to combine LLMs' in-context learning strengths with precise adaptability required by AIGB tasks. Extensive experiments on both real-world and synthetic data environments demonstrate that our approach consistently outperforms existing baselines in terms of cumulative advertiser value under budget constraints.
DecisionLLM: Large Language Models for Long Sequence Decision Exploration
Jan 15, 2026Long-sequence decision-making, which is usually addressed through reinforcement learning (RL), is a critical component for optimizing strategic operations in dynamic environments, such as real-time bidding in computational advertising. The Decision Transformer (DT) introduced a powerful paradigm by framing RL as an autoregressive sequence modeling problem. Concurrently, Large Language Models (LLMs) have demonstrated remarkable success in complex reasoning and planning tasks. This inspires us whether LLMs, which share the same Transformer foundation, but operate at a much larger scale, can unlock new levels of performance in long-horizon sequential decision-making problem. This work investigates the application of LLMs to offline decision making tasks. A fundamental challenge in this domain is the LLMs' inherent inability to interpret continuous values, as they lack a native understanding of numerical magnitude and order when values are represented as text strings. To address this, we propose treating trajectories as a distinct modality. By learning to align trajectory data with natural language task descriptions, our model can autoregressively predict future decisions within a cohesive framework we term DecisionLLM. We establish a set of scaling laws governing this paradigm, demonstrating that performance hinges on three factors: model scale, data volume, and data quality. In offline experimental benchmarks and bidding scenarios, DecisionLLM achieves strong performance. Specifically, DecisionLLM-3B outperforms the traditional Decision Transformer (DT) by 69.4 on Maze2D umaze-v1 and by 0.085 on AuctionNet. It extends the AIGB paradigm and points to promising directions for future exploration in online bidding.
AuctionNet: A Novel Benchmark for Decision-Making in Large-Scale Games
Dec 14, 2024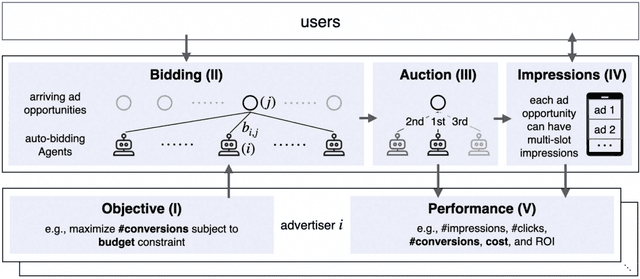
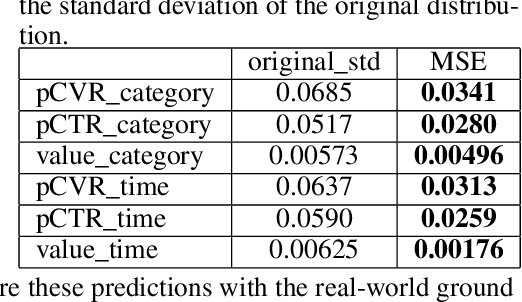
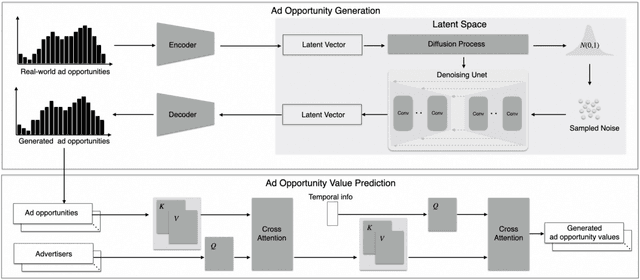

Decision-making in large-scale games is an essential research area in artificial intelligence (AI) with significant real-world impact. However, the limited access to realistic large-scale game environments has hindered research progress in this area. In this paper, we present \textbf{AuctionNet}, a benchmark for bid decision-making in large-scale ad auctions derived from a real-world online advertising platform. AuctionNet is composed of three parts: an ad auction environment, a pre-generated dataset based on the environment, and performance evaluations of several baseline bid decision-making algorithms. More specifically, the environment effectively replicates the integrity and complexity of real-world ad auctions through the interaction of several modules: the ad opportunity generation module employs deep generative models to bridge the gap between simulated and real-world data while mitigating the risk of sensitive data exposure; the bidding module implements diverse auto-bidding agents trained with different decision-making algorithms; and the auction module is anchored in the classic Generalized Second Price (GSP) auction but also allows for customization of auction mechanisms as needed. To facilitate research and provide insights into the game environment, we have also pre-generated a substantial dataset based on the environment. The dataset contains trajectories involving 48 diverse agents competing with each other, totaling over 500 million records and occupying 80GB of storage. Performance evaluations of baseline algorithms such as linear programming, reinforcement learning, and generative models for bid decision-making are also presented as part of AuctionNet. We note that AuctionNet is applicable not only to research on bid decision-making algorithms in ad auctions but also to the general area of decision-making in large-scale games.
AIGB: Generative Auto-bidding via Diffusion Modeling
May 25, 2024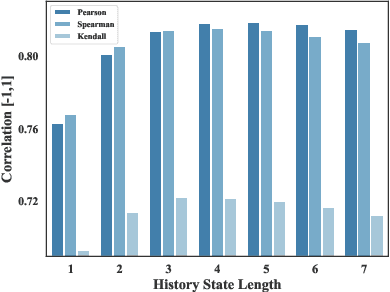
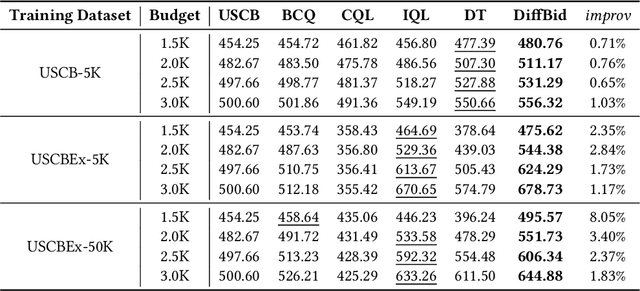
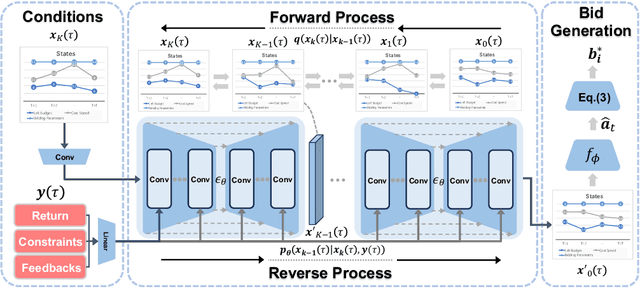
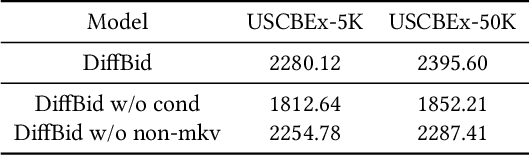
Auto-bidding plays a crucial role in facilitating online advertising by automatically providing bids for advertisers. Reinforcement learning (RL) has gained popularity for auto-bidding. However, most current RL auto-bidding methods are modeled through the Markovian Decision Process (MDP), which assumes the Markovian state transition. This assumption restricts the ability to perform in long horizon scenarios and makes the model unstable when dealing with highly random online advertising environments. To tackle this issue, this paper introduces AI-Generated Bidding (AIGB), a novel paradigm for auto-bidding through generative modeling. In this paradigm, we propose DiffBid, a conditional diffusion modeling approach for bid generation. DiffBid directly models the correlation between the return and the entire trajectory, effectively avoiding error propagation across time steps in long horizons. Additionally, DiffBid offers a versatile approach for generating trajectories that maximize given targets while adhering to specific constraints. Extensive experiments conducted on the real-world dataset and online A/B test on Alibaba advertising platform demonstrate the effectiveness of DiffBid, achieving 2.81% increase in GMV and 3.36% increase in ROI.
Trajectory-wise Iterative Reinforcement Learning Framework for Auto-bidding
Feb 23, 2024



In online advertising, advertisers participate in ad auctions to acquire ad opportunities, often by utilizing auto-bidding tools provided by demand-side platforms (DSPs). The current auto-bidding algorithms typically employ reinforcement learning (RL). However, due to safety concerns, most RL-based auto-bidding policies are trained in simulation, leading to a performance degradation when deployed in online environments. To narrow this gap, we can deploy multiple auto-bidding agents in parallel to collect a large interaction dataset. Offline RL algorithms can then be utilized to train a new policy. The trained policy can subsequently be deployed for further data collection, resulting in an iterative training framework, which we refer to as iterative offline RL. In this work, we identify the performance bottleneck of this iterative offline RL framework, which originates from the ineffective exploration and exploitation caused by the inherent conservatism of offline RL algorithms. To overcome this bottleneck, we propose Trajectory-wise Exploration and Exploitation (TEE), which introduces a novel data collecting and data utilization method for iterative offline RL from a trajectory perspective. Furthermore, to ensure the safety of online exploration while preserving the dataset quality for TEE, we propose Safe Exploration by Adaptive Action Selection (SEAS). Both offline experiments and real-world experiments on Alibaba display advertising platform demonstrate the effectiveness of our proposed method.
Sustainable Online Reinforcement Learning for Auto-bidding
Oct 13, 2022
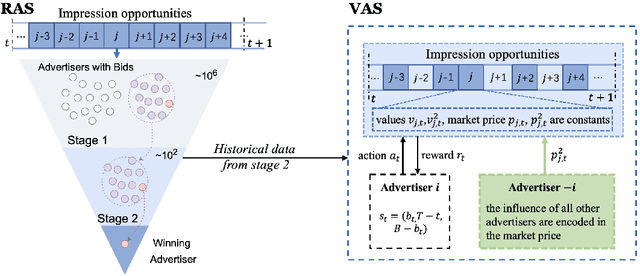

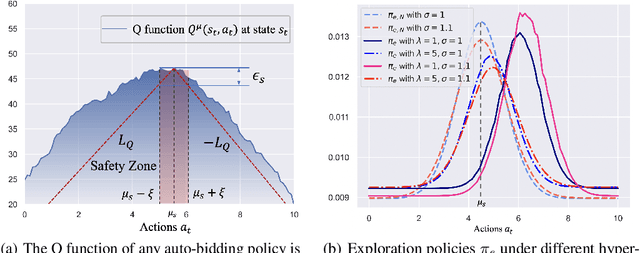
Recently, auto-bidding technique has become an essential tool to increase the revenue of advertisers. Facing the complex and ever-changing bidding environments in the real-world advertising system (RAS), state-of-the-art auto-bidding policies usually leverage reinforcement learning (RL) algorithms to generate real-time bids on behalf of the advertisers. Due to safety concerns, it was believed that the RL training process can only be carried out in an offline virtual advertising system (VAS) that is built based on the historical data generated in the RAS. In this paper, we argue that there exists significant gaps between the VAS and RAS, making the RL training process suffer from the problem of inconsistency between online and offline (IBOO). Firstly, we formally define the IBOO and systematically analyze its causes and influences. Then, to avoid the IBOO, we propose a sustainable online RL (SORL) framework that trains the auto-bidding policy by directly interacting with the RAS, instead of learning in the VAS. Specifically, based on our proof of the Lipschitz smooth property of the Q function, we design a safe and efficient online exploration (SER) policy for continuously collecting data from the RAS. Meanwhile, we derive the theoretical lower bound on the safety of the SER policy. We also develop a variance-suppressed conservative Q-learning (V-CQL) method to effectively and stably learn the auto-bidding policy with the collected data. Finally, extensive simulated and real-world experiments validate the superiority of our approach over the state-of-the-art auto-bidding algorithm.
DeepThermal: Combustion Optimization for Thermal Power Generating Units Using Offline Reinforcement Learning
Feb 24, 2021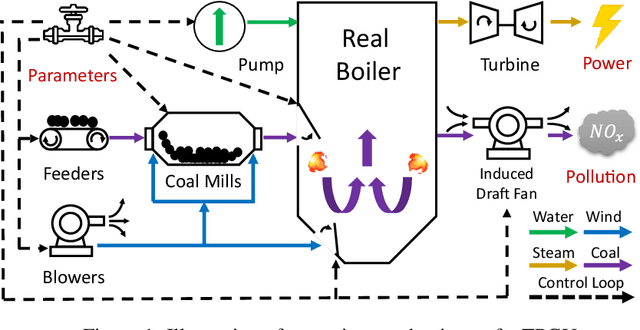

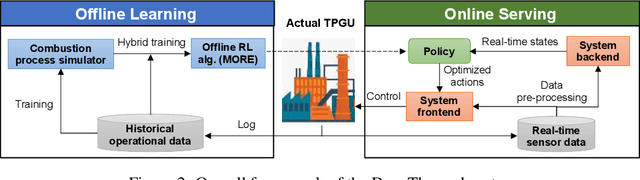

Thermal power generation plays a dominant role in the world's electricity supply. It consumes large amounts of coal worldwide, and causes serious air pollution. Optimizing the combustion efficiency of a thermal power generating unit (TPGU) is a highly challenging and critical task in the energy industry. We develop a new data-driven AI system, namely DeepThermal, to optimize the combustion control strategy for TPGUs. At its core, is a new model-based offline reinforcement learning (RL) framework, called MORE, which leverages logged historical operational data of a TPGU to solve a highly complex constrained Markov decision process problem via purely offline training. MORE aims at simultaneously improving the long-term reward (increase combustion efficiency and reduce pollutant emission) and controlling operational risks (safety constraints satisfaction). In DeepThermal, we first learn a data-driven combustion process simulator from the offline dataset. The RL agent of MORE is then trained by combining real historical data as well as carefully filtered and processed simulation data through a novel restrictive exploration scheme. DeepThermal has been successfully deployed in four large coal-fired thermal power plants in China. Real-world experiments show that DeepThermal effectively improves the combustion efficiency of a TPGU. We also report and demonstrate the superior performance of MORE by comparing with the state-of-the-art algorithms on the standard offline RL benchmarks. To the best knowledge of the authors, DeepThermal is the first AI application that has been used to solve real-world complex mission-critical control tasks using the offline RL approach.
Tensor-based Cooperative Control for Large Scale Multi-intersection Traffic Signal Using Deep Reinforcement Learning and Imitation Learning
Sep 30, 2019
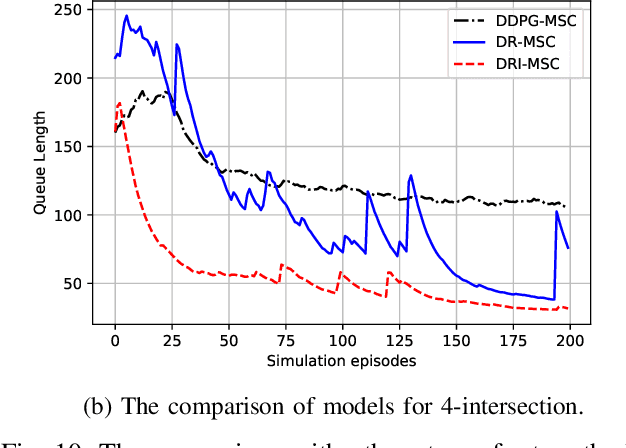

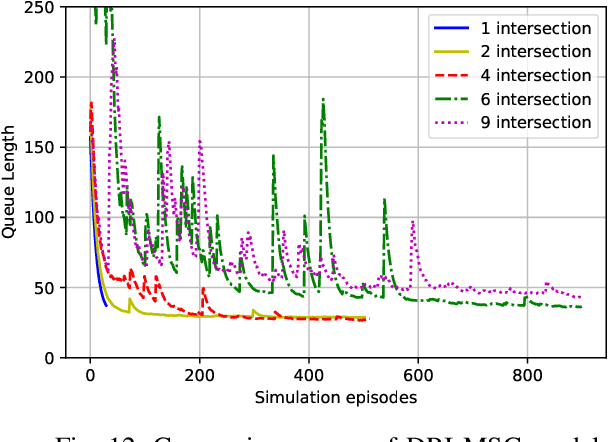
Traffic signal control has long been considered as a critical topic in intelligent transportation systems. Most existing learning methods mainly focus on isolated intersections and suffer from inefficient training. This paper aims at the cooperative control for large scale multi-intersection traffic signal, in which a novel end-to-end learning based model is established and the efficient training method is proposed correspondingly. In the proposed model, the input traffic status in multi-intersections is represented by a tensor, which not only significantly reduces dimensionality than using a single matrix but also avoids information loss. For the output, a multidimensional boolean vector is employed for the control policy to indicate whether the signal state changes or not, which simplifies the representation and abides the practical phase changing rules. In the proposed model, a multi-task learning structure is used to get the cooperative policy by learning. Instead of only using the reinforcement learning to train the model, we employ imitation learning to integrate a rule based model with neural networks to do the pre-training, which provides a reliable and satisfactory stage solution and greatly accelerates the convergence. Afterwards, the reinforcement learning method is adopted to continue the fine training, where proximal policy optimization algorithm is incorporated to solve the policy collapse problem in multi-dimensional output situation. In numerical experiments, the advantages of the proposed model are demonstrated with comparison to the related state-of-the-art methods.