 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEnhancing Generative Auto-bidding with Offline Reward Evaluation and Policy Search
Sep 19, 2025Auto-bidding is an essential tool for advertisers to enhance their advertising performance. Recent progress has shown that AI-Generated Bidding (AIGB), which formulates the auto-bidding as a trajectory generation task and trains a conditional diffusion-based planner on offline data, achieves superior and stable performance compared to typical offline reinforcement learning (RL)-based auto-bidding methods. However, existing AIGB methods still encounter a performance bottleneck due to their neglect of fine-grained generation quality evaluation and inability to explore beyond static datasets. To address this, we propose AIGB-Pearl (\emph{Planning with EvAluator via RL}), a novel method that integrates generative planning and policy optimization. The key to AIGB-Pearl is to construct a non-bootstrapped \emph{trajectory evaluator} to assign rewards and guide policy search, enabling the planner to optimize its generation quality iteratively through interaction. Furthermore, to enhance trajectory evaluator accuracy in offline settings, we incorporate three key techniques: (i) a Large Language Model (LLM)-based architecture for better representational capacity, (ii) hybrid point-wise and pair-wise losses for better score learning, and (iii) adaptive integration of expert feedback for better generalization ability. Extensive experiments on both simulated and real-world advertising systems demonstrate the state-of-the-art performance of our approach.
Nash Equilibrium Constrained Auto-bidding With Bi-level Reinforcement Learning
Mar 13, 2025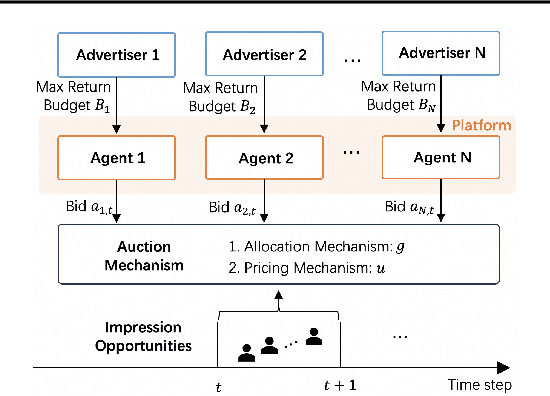
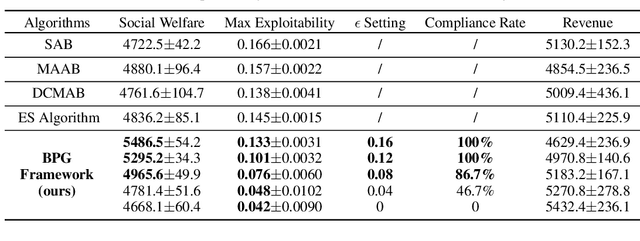


Many online advertising platforms provide advertisers with auto-bidding services to enhance their advertising performance. However, most existing auto-bidding algorithms fail to accurately capture the auto-bidding problem formulation that the platform truly faces, let alone solve it. Actually, we argue that the platform should try to help optimize each advertiser's performance to the greatest extent -- which makes $\epsilon$-Nash Equilibrium ($\epsilon$-NE) a necessary solution concept -- while maximizing the social welfare of all the advertisers for the platform's long-term value. Based on this, we introduce the \emph{Nash-Equilibrium Constrained Bidding} (NCB), a new formulation of the auto-bidding problem from the platform's perspective. Specifically, it aims to maximize the social welfare of all advertisers under the $\epsilon$-NE constraint. However, the NCB problem presents significant challenges due to its constrained bi-level structure and the typically large number of advertisers involved. To address these challenges, we propose a \emph{Bi-level Policy Gradient} (BPG) framework with theoretical guarantees. Notably, its computational complexity is independent of the number of advertisers, and the associated gradients are straightforward to compute. Extensive simulated and real-world experiments validate the effectiveness of the BPG framework.
MEBS: Multi-task End-to-end Bid Shading for Multi-slot Display Advertising
Mar 05, 2024



Online bidding and auction are crucial aspects of the online advertising industry. Conventionally, there is only one slot for ad display and most current studies focus on it. Nowadays, multi-slot display advertising is gradually becoming popular where many ads could be displayed in a list and shown as a whole to users. However, multi-slot display advertising leads to different cost-effectiveness. Advertisers have the incentive to adjust bid prices so as to win the most economical ad positions. In this study, we introduce bid shading into multi-slot display advertising for bid price adjustment with a Multi-task End-to-end Bid Shading(MEBS) method. We prove the optimality of our method theoretically and examine its performance experimentally. Through extensive offline and online experiments, we demonstrate the effectiveness and efficiency of our method, and we obtain a 7.01% lift in Gross Merchandise Volume, a 7.42% lift in Return on Investment, and a 3.26% lift in ad buy count.
Sustainable Online Reinforcement Learning for Auto-bidding
Oct 13, 2022
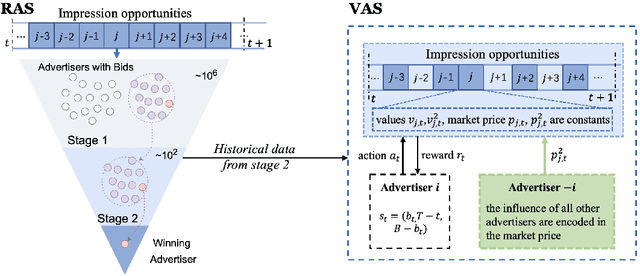

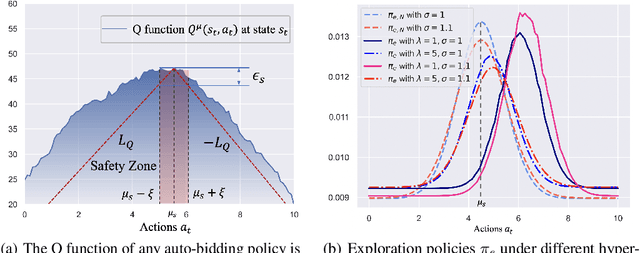
Recently, auto-bidding technique has become an essential tool to increase the revenue of advertisers. Facing the complex and ever-changing bidding environments in the real-world advertising system (RAS), state-of-the-art auto-bidding policies usually leverage reinforcement learning (RL) algorithms to generate real-time bids on behalf of the advertisers. Due to safety concerns, it was believed that the RL training process can only be carried out in an offline virtual advertising system (VAS) that is built based on the historical data generated in the RAS. In this paper, we argue that there exists significant gaps between the VAS and RAS, making the RL training process suffer from the problem of inconsistency between online and offline (IBOO). Firstly, we formally define the IBOO and systematically analyze its causes and influences. Then, to avoid the IBOO, we propose a sustainable online RL (SORL) framework that trains the auto-bidding policy by directly interacting with the RAS, instead of learning in the VAS. Specifically, based on our proof of the Lipschitz smooth property of the Q function, we design a safe and efficient online exploration (SER) policy for continuously collecting data from the RAS. Meanwhile, we derive the theoretical lower bound on the safety of the SER policy. We also develop a variance-suppressed conservative Q-learning (V-CQL) method to effectively and stably learn the auto-bidding policy with the collected data. Finally, extensive simulated and real-world experiments validate the superiority of our approach over the state-of-the-art auto-bidding algorithm.
Dynamic Knapsack Optimization Towards Efficient Multi-Channel Sequential Advertising
Jun 29, 2020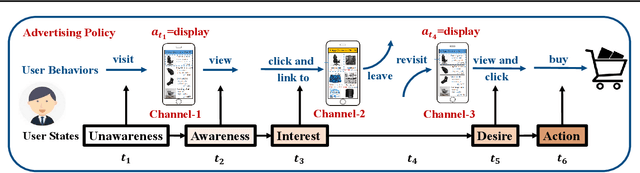
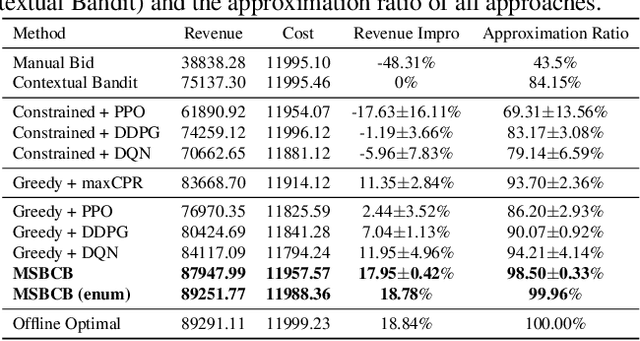
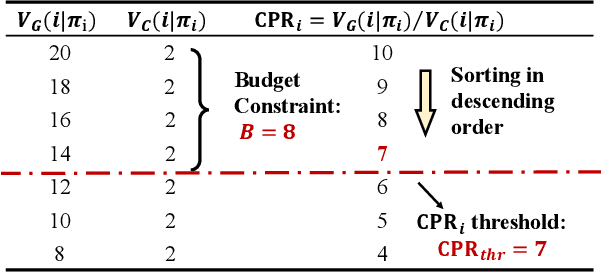
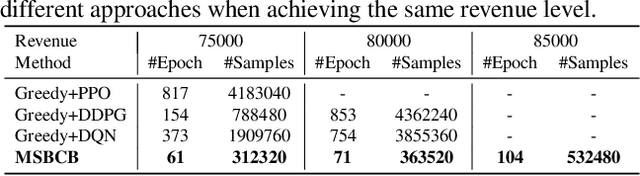
In E-commerce, advertising is essential for merchants to reach their target users. The typical objective is to maximize the advertiser's cumulative revenue over a period of time under a budget constraint. In real applications, an advertisement (ad) usually needs to be exposed to the same user multiple times until the user finally contributes revenue (e.g., places an order). However, existing advertising systems mainly focus on the immediate revenue with single ad exposures, ignoring the contribution of each exposure to the final conversion, thus usually falls into suboptimal solutions. In this paper, we formulate the sequential advertising strategy optimization as a dynamic knapsack problem. We propose a theoretically guaranteed bilevel optimization framework, which significantly reduces the solution space of the original optimization space while ensuring the solution quality. To improve the exploration efficiency of reinforcement learning, we also devise an effective action space reduction approach. Extensive offline and online experiments show the superior performance of our approaches over state-of-the-art baselines in terms of cumulative revenue.