 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDiscriminator-Weighted Offline Imitation Learning from Suboptimal Demonstrations
Jul 20, 2022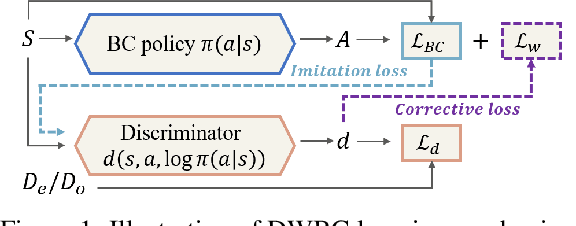
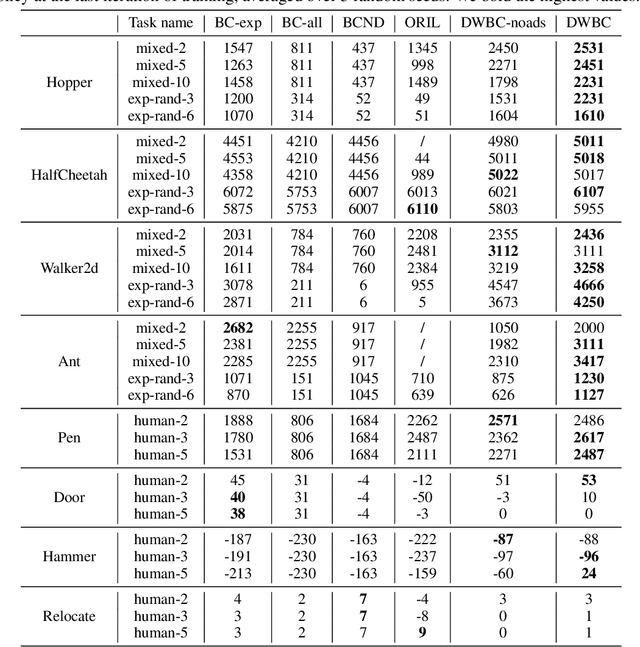
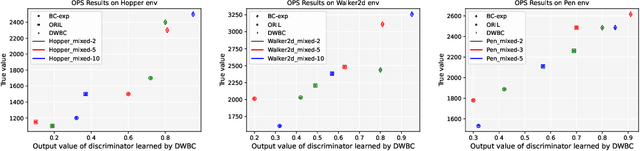
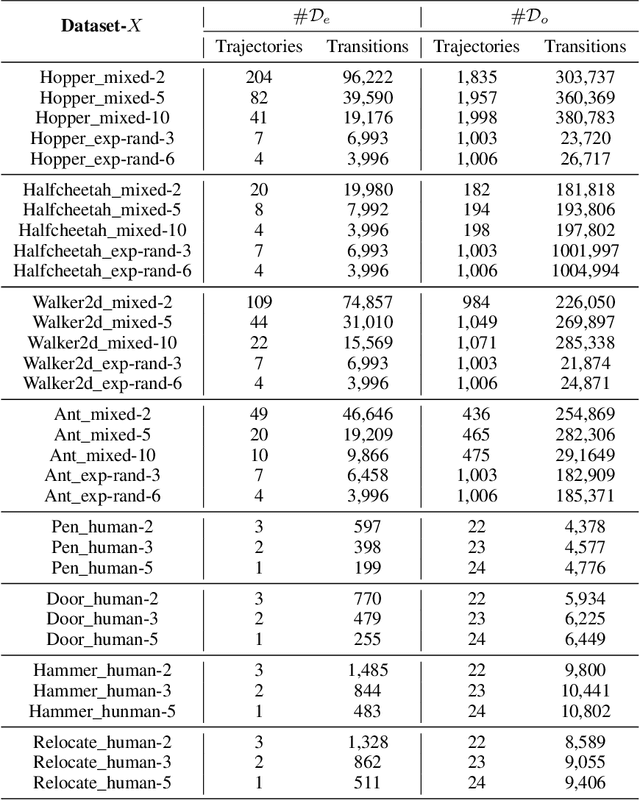
We study the problem of offline Imitation Learning (IL) where an agent aims to learn an optimal expert behavior policy without additional online environment interactions. Instead, the agent is provided with a supplementary offline dataset from suboptimal behaviors. Prior works that address this problem either require that expert data occupies the majority proportion of the offline dataset, or need to learn a reward function and perform offline reinforcement learning (RL) afterwards. In this paper, we aim to address the problem without additional steps of reward learning and offline RL training for the case when demonstrations contain a large proportion of suboptimal data. Built upon behavioral cloning (BC), we introduce an additional discriminator to distinguish expert and non-expert data. We propose a cooperation framework to boost the learning of both tasks, Based on this framework, we design a new IL algorithm, where the outputs of discriminator serve as the weights of the BC loss. Experimental results show that our proposed algorithm achieves higher returns and faster training speed compared to baseline algorithms.
Offline Reinforcement Learning with Soft Behavior Regularization
Oct 14, 2021
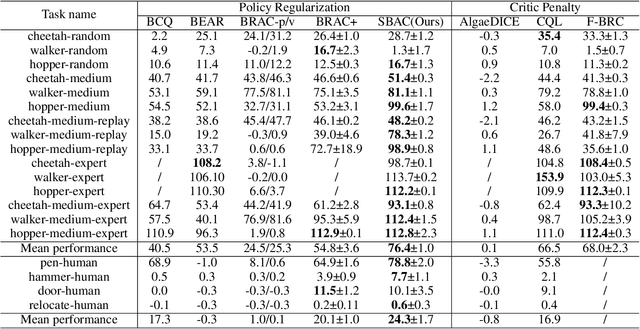
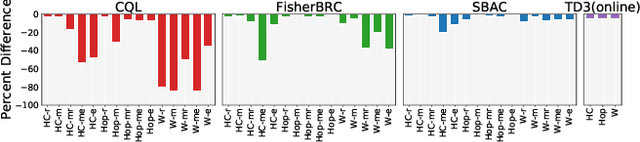
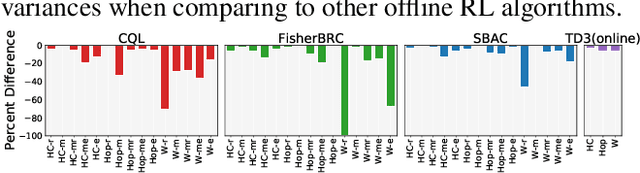
Most prior approaches to offline reinforcement learning (RL) utilize \textit{behavior regularization}, typically augmenting existing off-policy actor critic algorithms with a penalty measuring divergence between the policy and the offline data. However, these approaches lack guaranteed performance improvement over the behavior policy. In this work, we start from the performance difference between the learned policy and the behavior policy, we derive a new policy learning objective that can be used in the offline setting, which corresponds to the advantage function value of the behavior policy, multiplying by a state-marginal density ratio. We propose a practical way to compute the density ratio and demonstrate its equivalence to a state-dependent behavior regularization. Unlike state-independent regularization used in prior approaches, this \textit{soft} regularization allows more freedom of policy deviation at high confidence states, leading to better performance and stability. We thus term our resulting algorithm Soft Behavior-regularized Actor Critic (SBAC). Our experimental results show that SBAC matches or outperforms the state-of-the-art on a set of continuous control locomotion and manipulation tasks.
DeepThermal: Combustion Optimization for Thermal Power Generating Units Using Offline Reinforcement Learning
Feb 24, 2021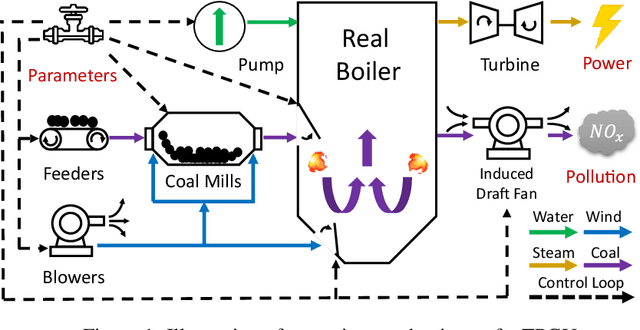

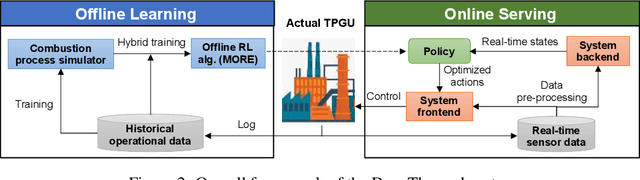

Thermal power generation plays a dominant role in the world's electricity supply. It consumes large amounts of coal worldwide, and causes serious air pollution. Optimizing the combustion efficiency of a thermal power generating unit (TPGU) is a highly challenging and critical task in the energy industry. We develop a new data-driven AI system, namely DeepThermal, to optimize the combustion control strategy for TPGUs. At its core, is a new model-based offline reinforcement learning (RL) framework, called MORE, which leverages logged historical operational data of a TPGU to solve a highly complex constrained Markov decision process problem via purely offline training. MORE aims at simultaneously improving the long-term reward (increase combustion efficiency and reduce pollutant emission) and controlling operational risks (safety constraints satisfaction). In DeepThermal, we first learn a data-driven combustion process simulator from the offline dataset. The RL agent of MORE is then trained by combining real historical data as well as carefully filtered and processed simulation data through a novel restrictive exploration scheme. DeepThermal has been successfully deployed in four large coal-fired thermal power plants in China. Real-world experiments show that DeepThermal effectively improves the combustion efficiency of a TPGU. We also report and demonstrate the superior performance of MORE by comparing with the state-of-the-art algorithms on the standard offline RL benchmarks. To the best knowledge of the authors, DeepThermal is the first AI application that has been used to solve real-world complex mission-critical control tasks using the offline RL approach.