 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeBrainstorming Brings Power to Large Language Models of Knowledge Reasoning
Jun 02, 2024



Large Language Models (LLMs) have demonstrated amazing capabilities in language generation, text comprehension, and knowledge reasoning. While a single powerful model can already handle multiple tasks, relying on a single perspective can lead to biased and unstable results. Recent studies have further improved the model's reasoning ability on a wide range of tasks by introducing multi-model collaboration. However, models with different capabilities may produce conflicting answers on the same problem, and how to reasonably obtain the correct answer from multiple candidate models has become a challenging problem. In this paper, we propose the multi-model brainstorming based on prompt. It incorporates different models into a group for brainstorming, and after multiple rounds of reasoning elaboration and re-inference, a consensus answer is reached within the group. We conducted experiments on three different types of datasets, and demonstrate that the brainstorming can significantly improve the effectiveness in logical reasoning and fact extraction. Furthermore, we find that two small-parameter models can achieve accuracy approximating that of larger-parameter models through brainstorming, which provides a new solution for distributed deployment of LLMs.
FlexSSL : A Generic and Efficient Framework for Semi-Supervised Learning
Dec 28, 2023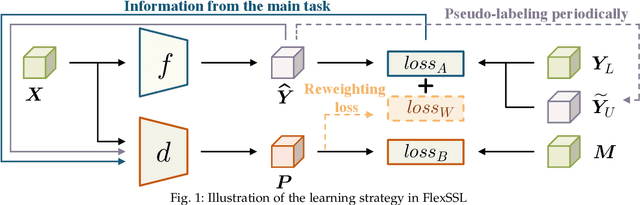


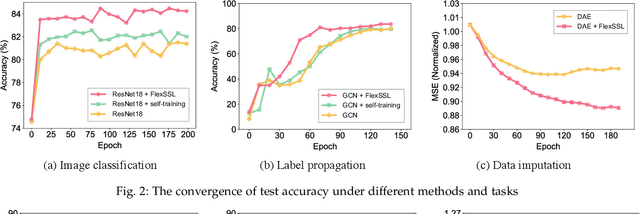
Semi-supervised learning holds great promise for many real-world applications, due to its ability to leverage both unlabeled and expensive labeled data. However, most semi-supervised learning algorithms still heavily rely on the limited labeled data to infer and utilize the hidden information from unlabeled data. We note that any semi-supervised learning task under the self-training paradigm also hides an auxiliary task of discriminating label observability. Jointly solving these two tasks allows full utilization of information from both labeled and unlabeled data, thus alleviating the problem of over-reliance on labeled data. This naturally leads to a new generic and efficient learning framework without the reliance on any domain-specific information, which we call FlexSSL. The key idea of FlexSSL is to construct a semi-cooperative "game", which forges cooperation between a main self-interested semi-supervised learning task and a companion task that infers label observability to facilitate main task training. We show with theoretical derivation of its connection to loss re-weighting on noisy labels. Through evaluations on a diverse range of tasks, we demonstrate that FlexSSL can consistently enhance the performance of semi-supervised learning algorithms.
InstructBio: A Large-scale Semi-supervised Learning Paradigm for Biochemical Problems
Apr 14, 2023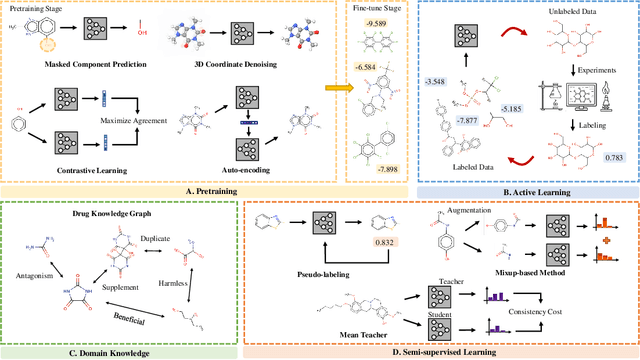
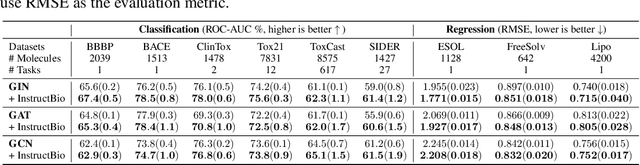
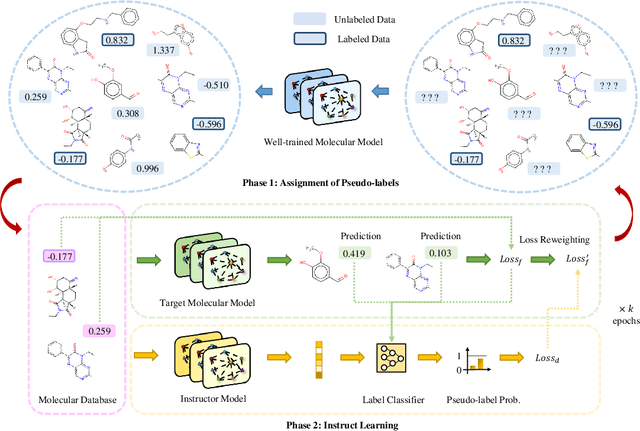
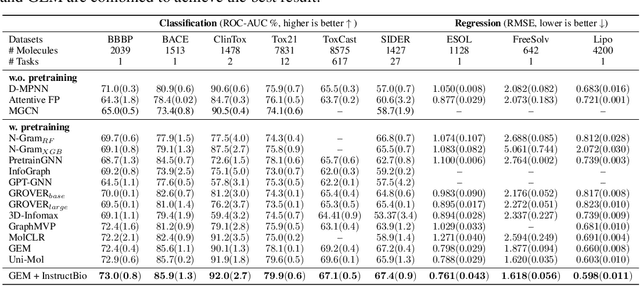
In the field of artificial intelligence for science, it is consistently an essential challenge to face a limited amount of labeled data for real-world problems. The prevailing approach is to pretrain a powerful task-agnostic model on a large unlabeled corpus but may struggle to transfer knowledge to downstream tasks. In this study, we propose InstructMol, a semi-supervised learning algorithm, to take better advantage of unlabeled examples. It introduces an instructor model to provide the confidence ratios as the measurement of pseudo-labels' reliability. These confidence scores then guide the target model to pay distinct attention to different data points, avoiding the over-reliance on labeled data and the negative influence of incorrect pseudo-annotations. Comprehensive experiments show that InstructBio substantially improves the generalization ability of molecular models, in not only molecular property predictions but also activity cliff estimations, demonstrating the superiority of the proposed method. Furthermore, our evidence indicates that InstructBio can be equipped with cutting-edge pretraining methods and used to establish large-scale and task-specific pseudo-labeled molecular datasets, which reduces the predictive errors and shortens the training process. Our work provides strong evidence that semi-supervised learning can be a promising tool to overcome the data scarcity limitation and advance molecular representation learning.
Discriminator-Weighted Offline Imitation Learning from Suboptimal Demonstrations
Jul 20, 2022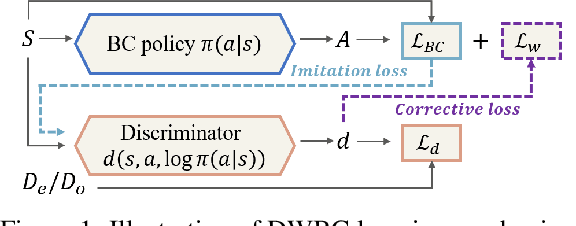
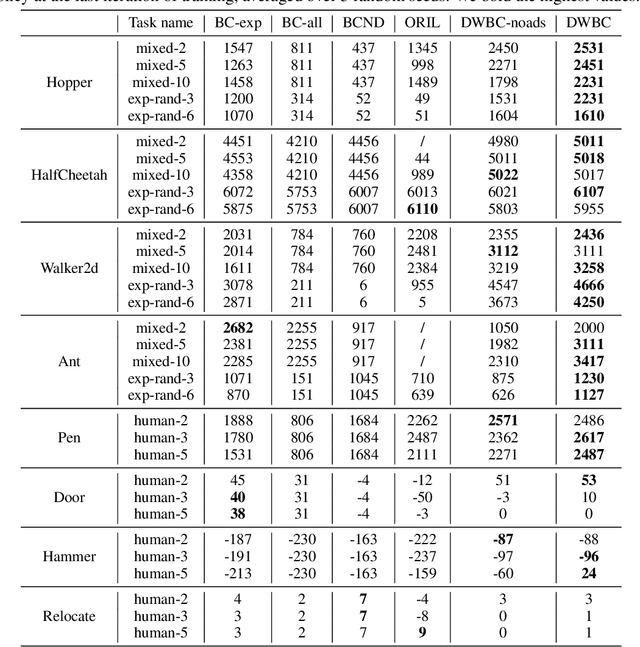
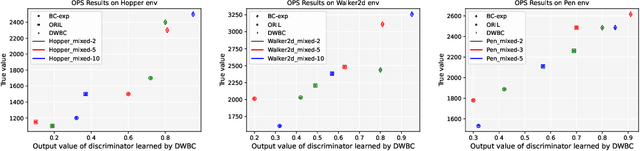
We study the problem of offline Imitation Learning (IL) where an agent aims to learn an optimal expert behavior policy without additional online environment interactions. Instead, the agent is provided with a supplementary offline dataset from suboptimal behaviors. Prior works that address this problem either require that expert data occupies the majority proportion of the offline dataset, or need to learn a reward function and perform offline reinforcement learning (RL) afterwards. In this paper, we aim to address the problem without additional steps of reward learning and offline RL training for the case when demonstrations contain a large proportion of suboptimal data. Built upon behavioral cloning (BC), we introduce an additional discriminator to distinguish expert and non-expert data. We propose a cooperation framework to boost the learning of both tasks, Based on this framework, we design a new IL algorithm, where the outputs of discriminator serve as the weights of the BC loss. Experimental results show that our proposed algorithm achieves higher returns and faster training speed compared to baseline algorithms.
CSCAD: Correlation Structure-based Collective Anomaly Detection in Complex System
May 30, 2021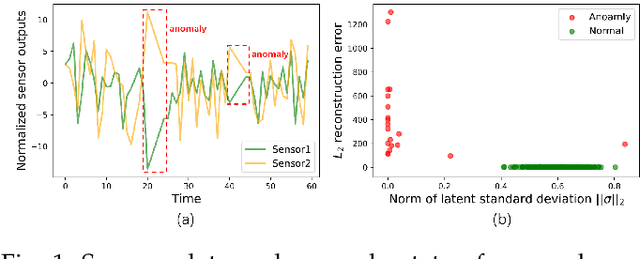
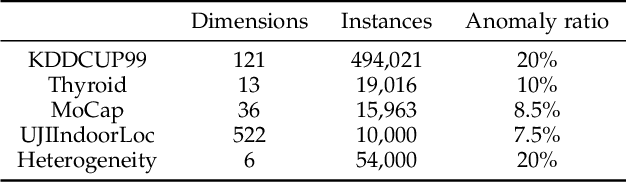
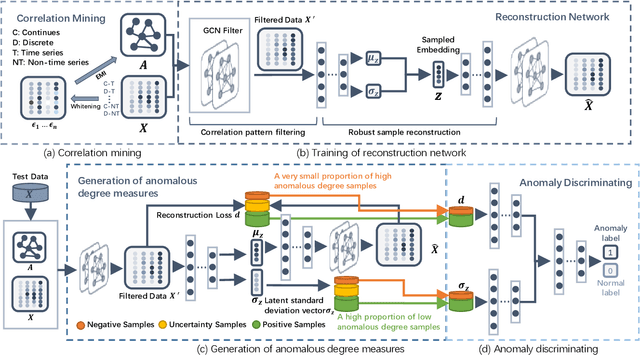
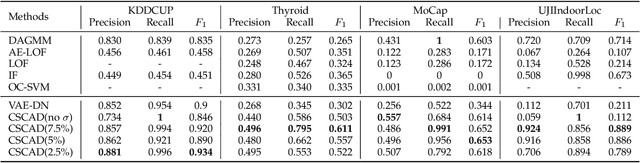
Detecting anomalies in large complex systems is a critical and challenging task. The difficulties arise from several aspects. First, collecting ground truth labels or prior knowledge for anomalies is hard in real-world systems, which often lead to limited or no anomaly labels in the dataset. Second, anomalies in large systems usually occur in a collective manner due to the underlying dependency structure among devices or sensors. Lastly, real-time anomaly detection for high-dimensional data requires efficient algorithms that are capable of handling different types of data (i.e. continuous and discrete). We propose a correlation structure-based collective anomaly detection (CSCAD) model for high-dimensional anomaly detection problem in large systems, which is also generalizable to semi-supervised or supervised settings. Our framework utilize graph convolutional network combining a variational autoencoder to jointly exploit the feature space correlation and reconstruction deficiency of samples to perform anomaly detection. We propose an extended mutual information (EMI) metric to mine the internal correlation structure among different data features, which enhances the data reconstruction capability of CSCAD. The reconstruction loss and latent standard deviation vector of a sample obtained from reconstruction network can be perceived as two natural anomalous degree measures. An anomaly discriminating network can then be trained using low anomalous degree samples as positive samples, and high anomalous degree samples as negative samples. Experimental results on five public datasets demonstrate that our approach consistently outperforms all the competing baselines.