 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeA Tri-Dynamic Preprocessing Framework for UGC Video Compression
Dec 18, 2025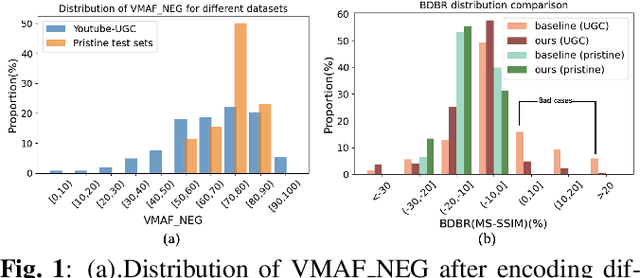
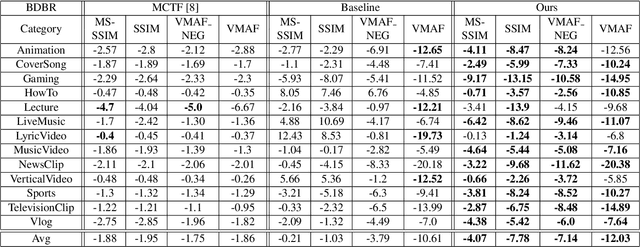
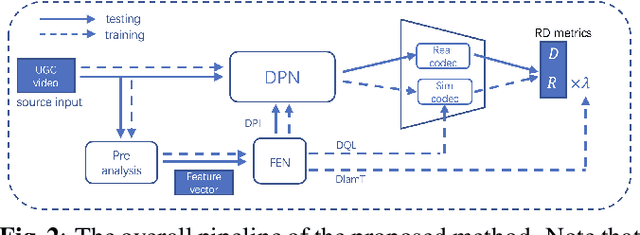
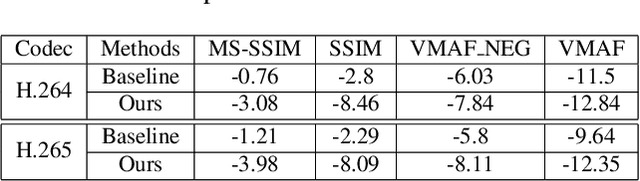
In recent years, user generated content (UGC) has become the dominant force in internet traffic. However, UGC videos exhibit a higher degree of variability and diverse characteristics compared to traditional encoding test videos. This variance challenges the effectiveness of data-driven machine learning algorithms for optimizing encoding in the broader context of UGC scenarios. To address this issue, we propose a Tri-Dynamic Preprocessing framework for UGC. Firstly, we employ an adaptive factor to regulate preprocessing intensity. Secondly, an adaptive quantization level is employed to fine-tune the codec simulator. Thirdly, we utilize an adaptive lambda tradeoff to adjust the rate-distortion loss function. Experimental results on large-scale test sets demonstrate that our method attains exceptional performance.
A Preprocessing Framework for Video Machine Vision under Compression
Dec 17, 2025
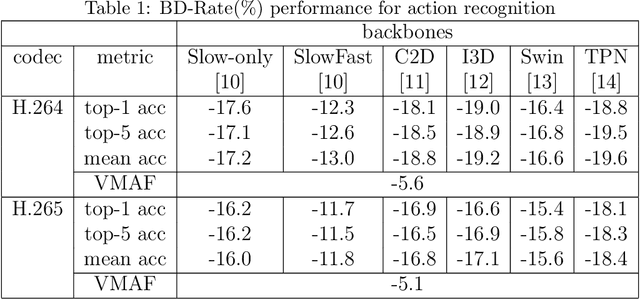
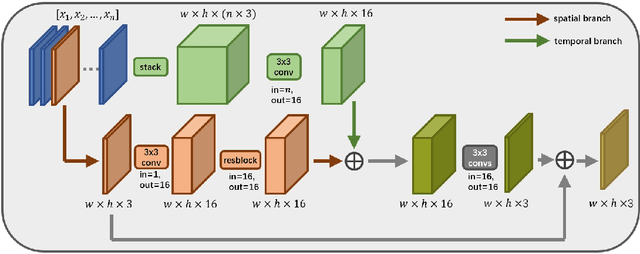
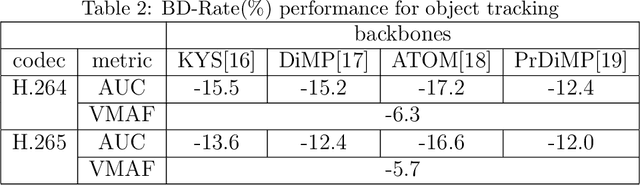
There has been a growing trend in compressing and transmitting videos from terminals for machine vision tasks. Nevertheless, most video coding optimization method focus on minimizing distortion according to human perceptual metrics, overlooking the heightened demands posed by machine vision systems. In this paper, we propose a video preprocessing framework tailored for machine vision tasks to address this challenge. The proposed method incorporates a neural preprocessor which retaining crucial information for subsequent tasks, resulting in the boosting of rate-accuracy performance. We further introduce a differentiable virtual codec to provide constraints on rate and distortion during the training stage. We directly apply widely used standard codecs for testing. Therefore, our solution can be easily applied to real-world scenarios. We conducted extensive experiments evaluating our compression method on two typical downstream tasks with various backbone networks. The experimental results indicate that our approach can save over 15% of bitrate compared to using only the standard codec anchor version.
FM-OV3D: Foundation Model-based Cross-modal Knowledge Blending for Open-Vocabulary 3D Detection
Dec 22, 2023



The superior performances of pre-trained foundation models in various visual tasks underscore their potential to enhance the 2D models' open-vocabulary ability. Existing methods explore analogous applications in the 3D space. However, most of them only center around knowledge extraction from singular foundation models, which limits the open-vocabulary ability of 3D models. We hypothesize that leveraging complementary pre-trained knowledge from various foundation models can improve knowledge transfer from 2D pre-trained visual language models to the 3D space. In this work, we propose FM-OV3D, a method of Foundation Model-based Cross-modal Knowledge Blending for Open-Vocabulary 3D Detection, which improves the open-vocabulary localization and recognition abilities of 3D model by blending knowledge from multiple pre-trained foundation models, achieving true open-vocabulary without facing constraints from original 3D datasets. Specifically, to learn the open-vocabulary 3D localization ability, we adopt the open-vocabulary localization knowledge of the Grounded-Segment-Anything model. For open-vocabulary 3D recognition ability, We leverage the knowledge of generative foundation models, including GPT-3 and Stable Diffusion models, and cross-modal discriminative models like CLIP. The experimental results on two popular benchmarks for open-vocabulary 3D object detection show that our model efficiently learns knowledge from multiple foundation models to enhance the open-vocabulary ability of the 3D model and successfully achieves state-of-the-art performance in open-vocabulary 3D object detection tasks. Code is released at https://github.com/dmzhang0425/FM-OV3D.git.
COLE: A Hierarchical Generation Framework for Graphic Design
Nov 28, 2023Graphic design, which has been evolving since the 15th century, plays a crucial role in advertising. The creation of high-quality designs demands creativity, innovation, and lateral thinking. This intricate task involves understanding the objective, crafting visual elements such as the background, decoration, font, color, and shape, formulating diverse professional layouts, and adhering to fundamental visual design principles. In this paper, we introduce COLE, a hierarchical generation framework designed to comprehensively address these challenges. This COLE system can transform a straightforward intention prompt into a high-quality graphic design, while also supporting flexible editing based on user input. Examples of such input might include directives like ``design a poster for Hisaishi's concert.'' The key insight is to dissect the complex task of text-to-design generation into a hierarchy of simpler sub-tasks, each addressed by specialized models working collaboratively. The results from these models are then consolidated to produce a cohesive final output. Our hierarchical task decomposition can streamline the complex process and significantly enhance generation reliability. Our COLE system consists of multiple fine-tuned Large Language Models (LLMs), Large Multimodal Models (LMMs), and Diffusion Models (DMs), each specifically tailored for a design-aware text or image generation task. Furthermore, we construct the DESIGNERINTENTION benchmark to highlight the superiority of our COLE over existing methods in generating high-quality graphic designs from user intent. We perceive our COLE as an important step towards addressing more complex visual design generation tasks in the future.
PM-DETR: Domain Adaptive Prompt Memory for Object Detection with Transformers
Jul 01, 2023The Transformer-based detectors (i.e., DETR) have demonstrated impressive performance on end-to-end object detection. However, transferring DETR to different data distributions may lead to a significant performance degradation. Existing adaptation techniques focus on model-based approaches, which aim to leverage feature alignment to narrow the distribution shift between different domains. In this study, we propose a hierarchical Prompt Domain Memory (PDM) for adapting detection transformers to different distributions. PDM comprehensively leverages the prompt memory to extract domain-specific knowledge and explicitly constructs a long-term memory space for the data distribution, which represents better domain diversity compared to existing methods. Specifically, each prompt and its corresponding distribution value are paired in the memory space, and we inject top M distribution-similar prompts into the input and multi-level embeddings of DETR. Additionally, we introduce the Prompt Memory Alignment (PMA) to reduce the discrepancy between the source and target domains by fully leveraging the domain-specific knowledge extracted from the prompt domain memory. Extensive experiments demonstrate that our method outperforms state-of-the-art domain adaptive object detection methods on three benchmarks, including scene, synthetic to real, and weather adaptation. Codes will be released.
Open-Vocabulary Point-Cloud Object Detection without 3D Annotation
Apr 03, 2023



The goal of open-vocabulary detection is to identify novel objects based on arbitrary textual descriptions. In this paper, we address open-vocabulary 3D point-cloud detection by a dividing-and-conquering strategy, which involves: 1) developing a point-cloud detector that can learn a general representation for localizing various objects, and 2) connecting textual and point-cloud representations to enable the detector to classify novel object categories based on text prompting. Specifically, we resort to rich image pre-trained models, by which the point-cloud detector learns localizing objects under the supervision of predicted 2D bounding boxes from 2D pre-trained detectors. Moreover, we propose a novel de-biased triplet cross-modal contrastive learning to connect the modalities of image, point-cloud and text, thereby enabling the point-cloud detector to benefit from vision-language pre-trained models,i.e.,CLIP. The novel use of image and vision-language pre-trained models for point-cloud detectors allows for open-vocabulary 3D object detection without the need for 3D annotations. Experiments demonstrate that the proposed method improves at least 3.03 points and 7.47 points over a wide range of baselines on the ScanNet and SUN RGB-D datasets, respectively. Furthermore, we provide a comprehensive analysis to explain why our approach works.
Towards Blind Watermarking: Combining Invertible and Non-invertible Mechanisms
Dec 24, 2022
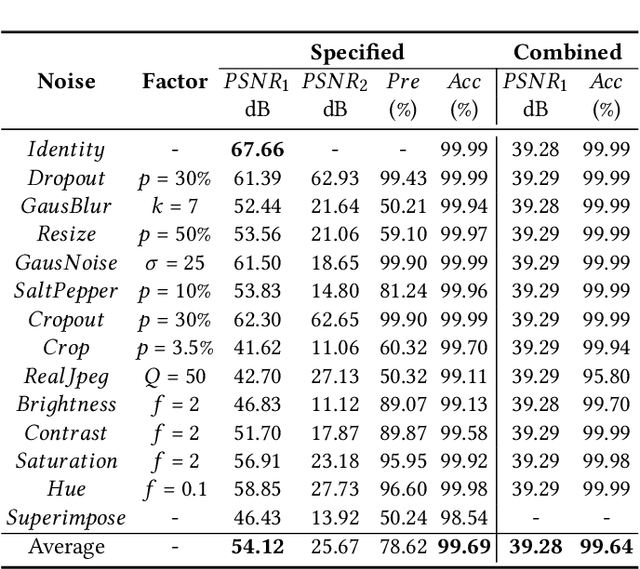
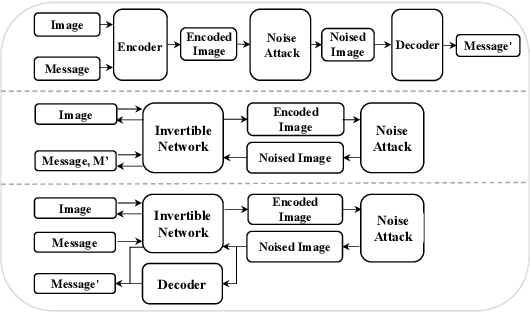
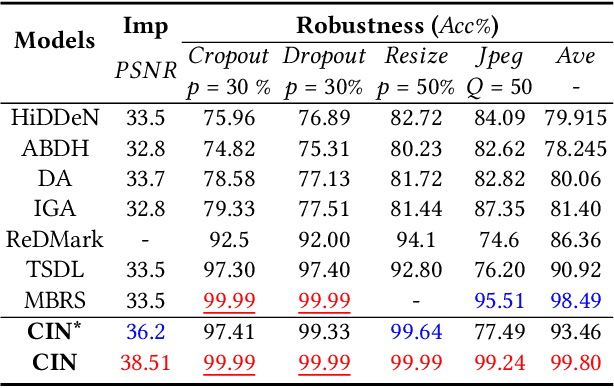
Blind watermarking provides powerful evidence for copyright protection, image authentication, and tampering identification. However, it remains a challenge to design a watermarking model with high imperceptibility and robustness against strong noise attacks. To resolve this issue, we present a framework Combining the Invertible and Non-invertible (CIN) mechanisms. The CIN is composed of the invertible part to achieve high imperceptibility and the non-invertible part to strengthen the robustness against strong noise attacks. For the invertible part, we develop a diffusion and extraction module (DEM) and a fusion and split module (FSM) to embed and extract watermarks symmetrically in an invertible way. For the non-invertible part, we introduce a non-invertible attention-based module (NIAM) and the noise-specific selection module (NSM) to solve the asymmetric extraction under a strong noise attack. Extensive experiments demonstrate that our framework outperforms the current state-of-the-art methods of imperceptibility and robustness significantly. Our framework can achieve an average of 99.99% accuracy and 67.66 dB PSNR under noise-free conditions, while 96.64% and 39.28 dB combined strong noise attacks. The code will be available in https://github.com/rmpku/CIN.
Multi-Agent Automated Machine Learning
Oct 17, 2022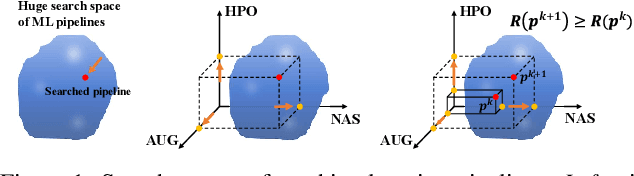
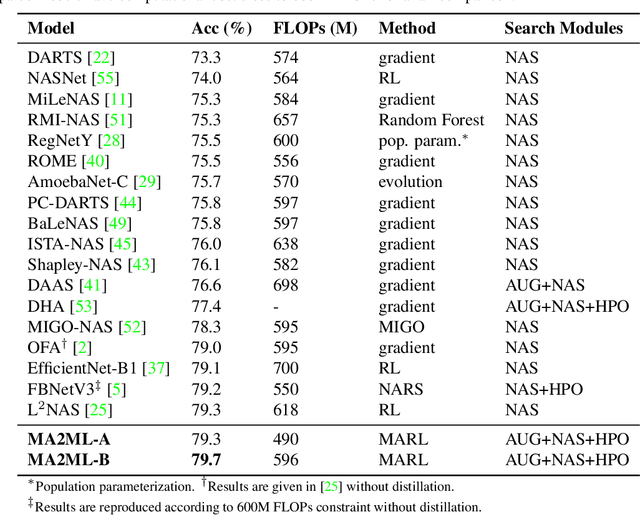
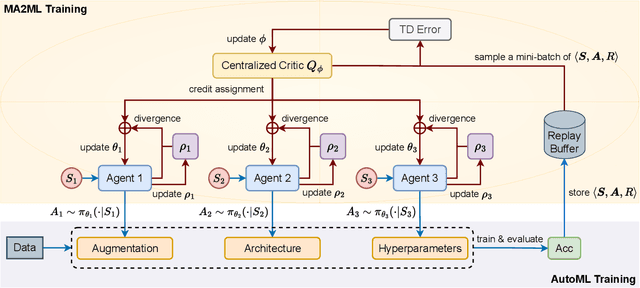
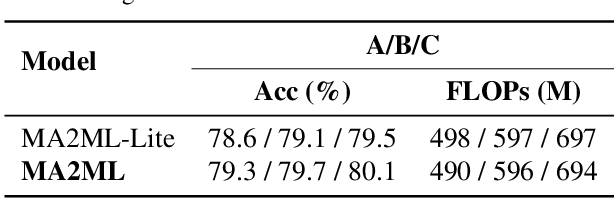
In this paper, we propose multi-agent automated machine learning (MA2ML) with the aim to effectively handle joint optimization of modules in automated machine learning (AutoML). MA2ML takes each machine learning module, such as data augmentation (AUG), neural architecture search (NAS), or hyper-parameters (HPO), as an agent and the final performance as the reward, to formulate a multi-agent reinforcement learning problem. MA2ML explicitly assigns credit to each agent according to its marginal contribution to enhance cooperation among modules, and incorporates off-policy learning to improve search efficiency. Theoretically, MA2ML guarantees monotonic improvement of joint optimization. Extensive experiments show that MA2ML yields the state-of-the-art top-1 accuracy on ImageNet under constraints of computational cost, e.g., $79.7\%/80.5\%$ with FLOPs fewer than 600M/800M. Extensive ablation studies verify the benefits of credit assignment and off-policy learning of MA2ML.
Open-Vocabulary 3D Detection via Image-level Class and Debiased Cross-modal Contrastive Learning
Jul 05, 2022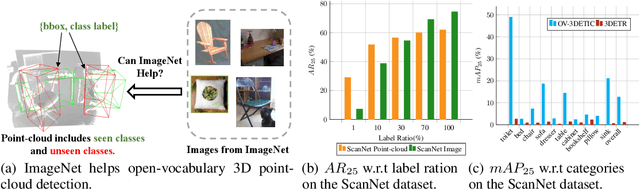
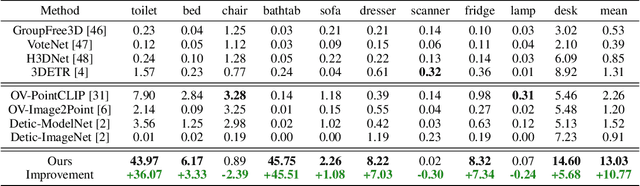
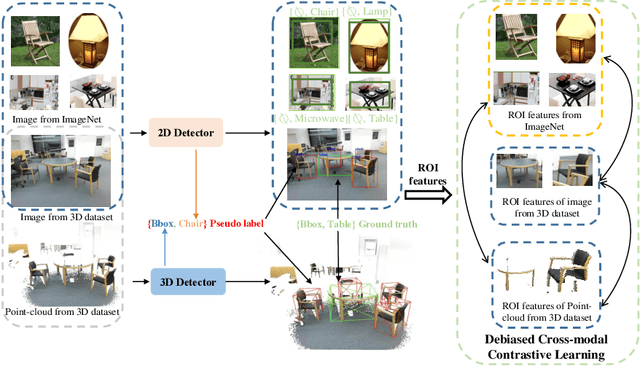
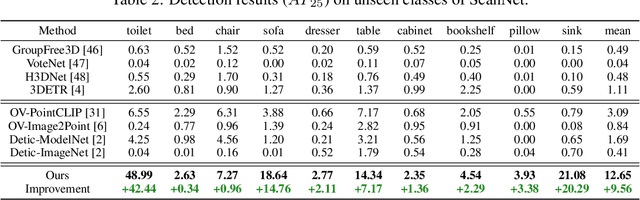
Current point-cloud detection methods have difficulty detecting the open-vocabulary objects in the real world, due to their limited generalization capability. Moreover, it is extremely laborious and expensive to collect and fully annotate a point-cloud detection dataset with numerous classes of objects, leading to the limited classes of existing point-cloud datasets and hindering the model to learn general representations to achieve open-vocabulary point-cloud detection. As far as we know, we are the first to study the problem of open-vocabulary 3D point-cloud detection. Instead of seeking a point-cloud dataset with full labels, we resort to ImageNet1K to broaden the vocabulary of the point-cloud detector. We propose OV-3DETIC, an Open-Vocabulary 3D DETector using Image-level Class supervision. Specifically, we take advantage of two modalities, the image modality for recognition and the point-cloud modality for localization, to generate pseudo labels for unseen classes. Then we propose a novel debiased cross-modal contrastive learning method to transfer the knowledge from image modality to point-cloud modality during training. Without hurting the latency during inference, OV-3DETIC makes the point-cloud detector capable of achieving open-vocabulary detection. Extensive experiments demonstrate that the proposed OV-3DETIC achieves at least 10.77 % mAP improvement (absolute value) and 9.56 % mAP improvement (absolute value) by a wide range of baselines on the SUN-RGBD dataset and ScanNet dataset, respectively. Besides, we conduct sufficient experiments to shed light on why the proposed OV-3DETIC works.
Enhancing and Dissecting Crowd Counting By Synthetic Data
Jan 22, 2022
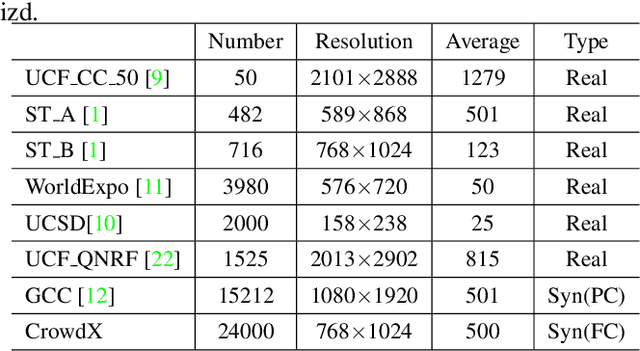

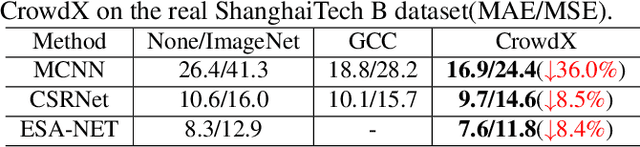
In this article, we propose a simulated crowd counting dataset CrowdX, which has a large scale, accurate labeling, parameterized realization, and high fidelity. The experimental results of using this dataset as data enhancement show that the performance of the proposed streamlined and efficient benchmark network ESA-Net can be improved by 8.4\%. The other two classic heterogeneous architectures MCNN and CSRNet pre-trained on CrowdX also show significant performance improvements. Considering many influencing factors determine performance, such as background, camera angle, human density, and resolution. Although these factors are important, there is still a lack of research on how they affect crowd counting. Thanks to the CrowdX dataset with rich annotation information, we conduct a large number of data-driven comparative experiments to analyze these factors. Our research provides a reference for a deeper understanding of the crowd counting problem and puts forward some useful suggestions in the actual deployment of the algorithm.