 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFaceRefiner: High-Fidelity Facial Texture Refinement with Differentiable Rendering-based Style Transfer
Jan 08, 2026Recent facial texture generation methods prefer to use deep networks to synthesize image content and then fill in the UV map, thus generating a compelling full texture from a single image. Nevertheless, the synthesized texture UV map usually comes from a space constructed by the training data or the 2D face generator, which limits the methods' generalization ability for in-the-wild input images. Consequently, their facial details, structures and identity may not be consistent with the input. In this paper, we address this issue by proposing a style transfer-based facial texture refinement method named FaceRefiner. FaceRefiner treats the 3D sampled texture as style and the output of a texture generation method as content. The photo-realistic style is then expected to be transferred from the style image to the content image. Different from current style transfer methods that only transfer high and middle level information to the result, our style transfer method integrates differentiable rendering to also transfer low level (or pixel level) information in the visible face regions. The main benefit of such multi-level information transfer is that, the details, structures and semantics in the input can thus be well preserved. The extensive experiments on Multi-PIE, CelebA and FFHQ datasets demonstrate that our refinement method can improve the texture quality and the face identity preserving ability, compared with state-of-the-arts.
RISE-T2V: Rephrasing and Injecting Semantics with LLM for Expansive Text-to-Video Generation
Nov 06, 2025Most text-to-video(T2V) diffusion models depend on pre-trained text encoders for semantic alignment, yet they often fail to maintain video quality when provided with concise prompts rather than well-designed ones. The primary issue lies in their limited textual semantics understanding. Moreover, these text encoders cannot rephrase prompts online to better align with user intentions, which limits both the scalability and usability of the models, To address these challenges, we introduce RISE-T2V, which uniquely integrates the processes of prompt rephrasing and semantic feature extraction into a single and seamless step instead of two separate steps. RISE-T2V is universal and can be applied to various pre-trained LLMs and video diffusion models(VDMs), significantly enhancing their capabilities for T2V tasks. We propose an innovative module called the Rephrasing Adapter, enabling diffusion models to utilize text hidden states during the next token prediction of the LLM as a condition for video generation. By employing a Rephrasing Adapter, the video generation model can implicitly rephrase basic prompts into more comprehensive representations that better match the user's intent. Furthermore, we leverage the powerful capabilities of LLMs to enable video generation models to accomplish a broader range of T2V tasks. Extensive experiments demonstrate that RISE-T2V is a versatile framework applicable to different video diffusion model architectures, significantly enhancing the ability of T2V models to generate high-quality videos that align with user intent. Visual results are available on the webpage at https://rise-t2v.github.io.
Predicting Turn-Taking and Backchannel in Human-Machine Conversations Using Linguistic, Acoustic, and Visual Signals
May 19, 2025This paper addresses the gap in predicting turn-taking and backchannel actions in human-machine conversations using multi-modal signals (linguistic, acoustic, and visual). To overcome the limitation of existing datasets, we propose an automatic data collection pipeline that allows us to collect and annotate over 210 hours of human conversation videos. From this, we construct a Multi-Modal Face-to-Face (MM-F2F) human conversation dataset, including over 1.5M words and corresponding turn-taking and backchannel annotations from approximately 20M frames. Additionally, we present an end-to-end framework that predicts the probability of turn-taking and backchannel actions from multi-modal signals. The proposed model emphasizes the interrelation between modalities and supports any combination of text, audio, and video inputs, making it adaptable to a variety of realistic scenarios. Our experiments show that our approach achieves state-of-the-art performance on turn-taking and backchannel prediction tasks, achieving a 10\% increase in F1-score on turn-taking and a 33\% increase on backchannel prediction. Our dataset and code are publicly available online to ease of subsequent research.
COLE: A Hierarchical Generation Framework for Graphic Design
Nov 28, 2023Graphic design, which has been evolving since the 15th century, plays a crucial role in advertising. The creation of high-quality designs demands creativity, innovation, and lateral thinking. This intricate task involves understanding the objective, crafting visual elements such as the background, decoration, font, color, and shape, formulating diverse professional layouts, and adhering to fundamental visual design principles. In this paper, we introduce COLE, a hierarchical generation framework designed to comprehensively address these challenges. This COLE system can transform a straightforward intention prompt into a high-quality graphic design, while also supporting flexible editing based on user input. Examples of such input might include directives like ``design a poster for Hisaishi's concert.'' The key insight is to dissect the complex task of text-to-design generation into a hierarchy of simpler sub-tasks, each addressed by specialized models working collaboratively. The results from these models are then consolidated to produce a cohesive final output. Our hierarchical task decomposition can streamline the complex process and significantly enhance generation reliability. Our COLE system consists of multiple fine-tuned Large Language Models (LLMs), Large Multimodal Models (LMMs), and Diffusion Models (DMs), each specifically tailored for a design-aware text or image generation task. Furthermore, we construct the DESIGNERINTENTION benchmark to highlight the superiority of our COLE over existing methods in generating high-quality graphic designs from user intent. We perceive our COLE as an important step towards addressing more complex visual design generation tasks in the future.
EMEF: Ensemble Multi-Exposure Image Fusion
May 22, 2023



Although remarkable progress has been made in recent years, current multi-exposure image fusion (MEF) research is still bounded by the lack of real ground truth, objective evaluation function, and robust fusion strategy. In this paper, we study the MEF problem from a new perspective. We don't utilize any synthesized ground truth, design any loss function, or develop any fusion strategy. Our proposed method EMEF takes advantage of the wisdom of multiple imperfect MEF contributors including both conventional and deep learning-based methods. Specifically, EMEF consists of two main stages: pre-train an imitator network and tune the imitator in the runtime. In the first stage, we make a unified network imitate different MEF targets in a style modulation way. In the second stage, we tune the imitator network by optimizing the style code, in order to find an optimal fusion result for each input pair. In the experiment, we construct EMEF from four state-of-the-art MEF methods and then make comparisons with the individuals and several other competitive methods on the latest released MEF benchmark dataset. The promising experimental results demonstrate that our ensemble framework can "get the best of all worlds". The code is available at https://github.com/medalwill/EMEF.
MusicFace: Music-driven Expressive Singing Face Synthesis
Mar 24, 2023It is still an interesting and challenging problem to synthesize a vivid and realistic singing face driven by music signal. In this paper, we present a method for this task with natural motions of the lip, facial expression, head pose, and eye states. Due to the coupling of the mixed information of human voice and background music in common signals of music audio, we design a decouple-and-fuse strategy to tackle the challenge. We first decompose the input music audio into human voice stream and background music stream. Due to the implicit and complicated correlation between the two-stream input signals and the dynamics of the facial expressions, head motions and eye states, we model their relationship with an attention scheme, where the effects of the two streams are fused seamlessly. Furthermore, to improve the expressiveness of the generated results, we propose to decompose head movements generation into speed generation and direction generation, and decompose eye states generation into the short-time eye blinking generation and the long-time eye closing generation to model them separately. We also build a novel SingingFace Dataset to support the training and evaluation of this task, and to facilitate future works on this topic. Extensive experiments and user study show that our proposed method is capable of synthesizing vivid singing face, which is better than state-of-the-art methods qualitatively and quantitatively.
MaskCLIP: Masked Self-Distillation Advances Contrastive Language-Image Pretraining
Aug 25, 2022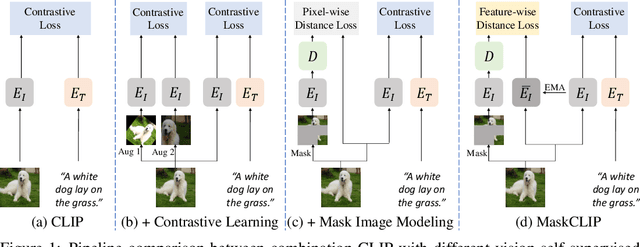
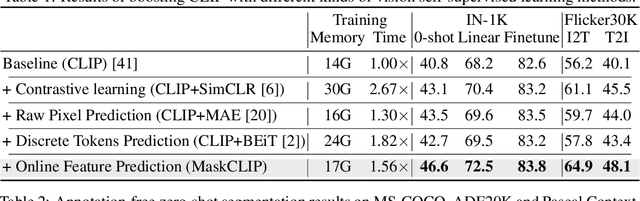
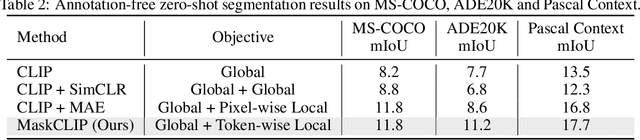
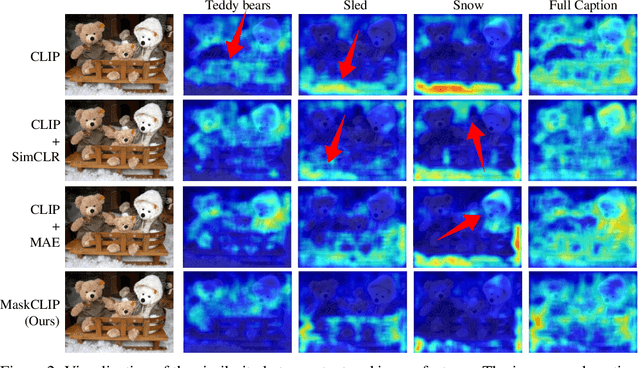
This paper presents a simple yet effective framework MaskCLIP, which incorporates a newly proposed masked self-distillation into contrastive language-image pretraining. The core idea of masked self-distillation is to distill representation from a full image to the representation predicted from a masked image. Such incorporation enjoys two vital benefits. First, masked self-distillation targets local patch representation learning, which is complementary to vision-language contrastive focusing on text-related representation.Second, masked self-distillation is also consistent with vision-language contrastive from the perspective of training objective as both utilize the visual encoder for feature aligning, and thus is able to learn local semantics getting indirect supervision from the language. We provide specially designed experiments with a comprehensive analysis to validate the two benefits. Empirically, we show that MaskCLIP, when applied to various challenging downstream tasks, achieves superior results in linear probing, finetuning as well as the zero-shot performance with the guidance of the language encoder.
I^2R-Net: Intra- and Inter-Human Relation Network for Multi-Person Pose Estimation
Jun 27, 2022
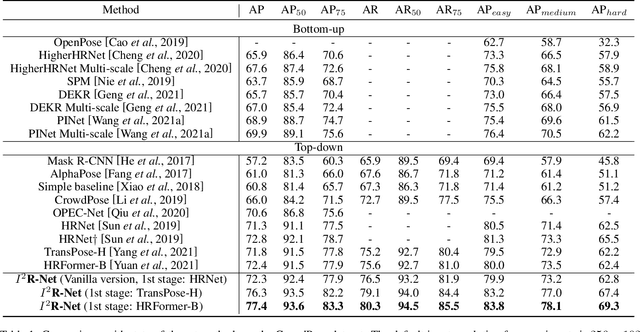
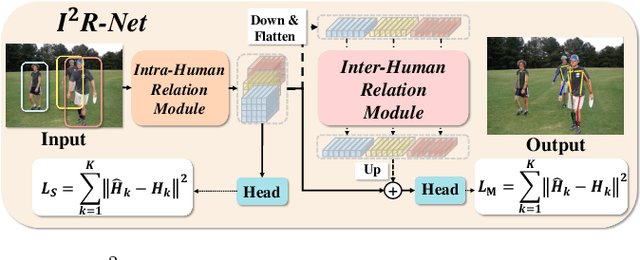
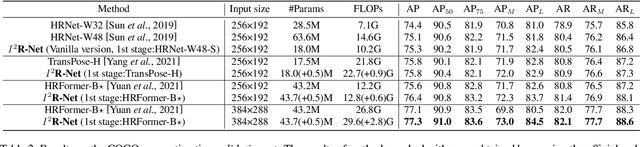
In this paper, we present the Intra- and Inter-Human Relation Networks (I^2R-Net) for Multi-Person Pose Estimation. It involves two basic modules. First, the Intra-Human Relation Module operates on a single person and aims to capture Intra-Human dependencies. Second, the Inter-Human Relation Module considers the relation between multiple instances and focuses on capturing Inter-Human interactions. The Inter-Human Relation Module can be designed very lightweight by reducing the resolution of feature map, yet learn useful relation information to significantly boost the performance of the Intra-Human Relation Module. Even without bells and whistles, our method can compete or outperform current competition winners. We conduct extensive experiments on COCO, CrowdPose, and OCHuman datasets. The results demonstrate that the proposed model surpasses all the state-of-the-art methods. Concretely, the proposed method achieves 77.4% AP on CrowPose dataset and 67.8% AP on OCHuman dataset respectively, outperforming existing methods by a large margin. Additionally, the ablation study and visualization analysis also prove the effectiveness of our model.
General Facial Representation Learning in a Visual-Linguistic Manner
Dec 06, 2021



How to learn a universal facial representation that boosts all face analysis tasks? This paper takes one step toward this goal. In this paper, we study the transfer performance of pre-trained models on face analysis tasks and introduce a framework, called FaRL, for general Facial Representation Learning in a visual-linguistic manner. On one hand, the framework involves a contrastive loss to learn high-level semantic meaning from image-text pairs. On the other hand, we propose exploring low-level information simultaneously to further enhance the face representation, by adding a masked image modeling. We perform pre-training on LAION-FACE, a dataset containing large amount of face image-text pairs, and evaluate the representation capability on multiple downstream tasks. We show that FaRL achieves better transfer performance compared with previous pre-trained models. We also verify its superiority in the low-data regime. More importantly, our model surpasses the state-of-the-art methods on face analysis tasks including face parsing and face alignment.
Exploring Temporal Coherence for More General Video Face Forgery Detection
Aug 15, 2021
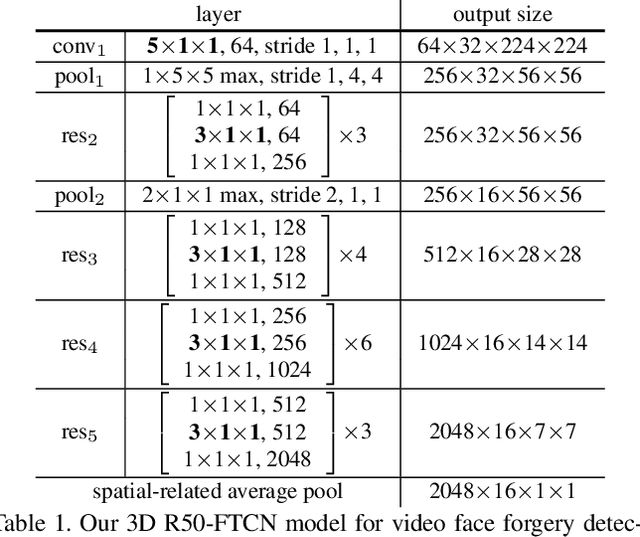


Although current face manipulation techniques achieve impressive performance regarding quality and controllability, they are struggling to generate temporal coherent face videos. In this work, we explore to take full advantage of the temporal coherence for video face forgery detection. To achieve this, we propose a novel end-to-end framework, which consists of two major stages. The first stage is a fully temporal convolution network (FTCN). The key insight of FTCN is to reduce the spatial convolution kernel size to 1, while maintaining the temporal convolution kernel size unchanged. We surprisingly find this special design can benefit the model for extracting the temporal features as well as improve the generalization capability. The second stage is a Temporal Transformer network, which aims to explore the long-term temporal coherence. The proposed framework is general and flexible, which can be directly trained from scratch without any pre-training models or external datasets. Extensive experiments show that our framework outperforms existing methods and remains effective when applied to detect new sorts of face forgery videos.