 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeUncertainty Estimation in the Real World: A Study on Music Emotion Recognition
Jan 20, 2025
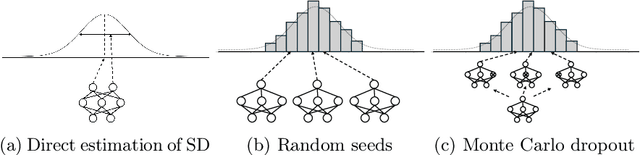
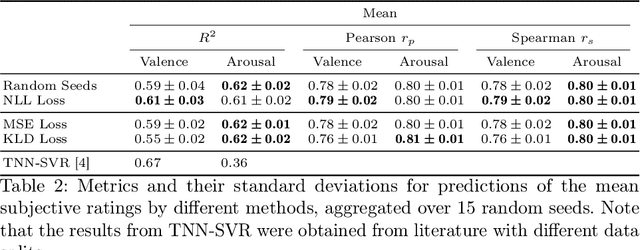
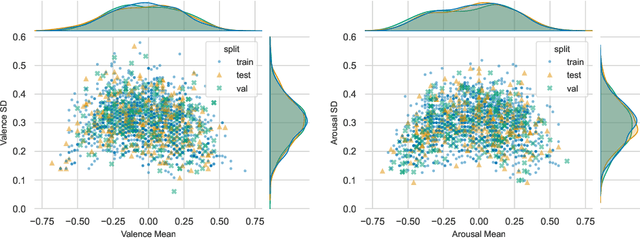
Any data annotation for subjective tasks shows potential variations between individuals. This is particularly true for annotations of emotional responses to musical stimuli. While older approaches to music emotion recognition systems frequently addressed this uncertainty problem through probabilistic modeling, modern systems based on neural networks tend to ignore the variability and focus only on predicting central tendencies of human subjective responses. In this work, we explore several methods for estimating not only the central tendencies of the subjective responses to a musical stimulus, but also for estimating the uncertainty associated with these responses. In particular, we investigate probabilistic loss functions and inference-time random sampling. Experimental results indicate that while the modeling of the central tendencies is achievable, modeling of the uncertainty in subjective responses proves significantly more challenging with currently available approaches even when empirical estimates of variations in the responses are available.
Understanding Pedestrian Movement Using Urban Sensing Technologies: The Promise of Audio-based Sensors
Jun 14, 2024While various sensors have been deployed to monitor vehicular flows, sensing pedestrian movement is still nascent. Yet walking is a significant mode of travel in many cities, especially those in Europe, Africa, and Asia. Understanding pedestrian volumes and flows is essential for designing safer and more attractive pedestrian infrastructure and for controlling periodic overcrowding. This study discusses a new approach to scale up urban sensing of people with the help of novel audio-based technology. It assesses the benefits and limitations of microphone-based sensors as compared to other forms of pedestrian sensing. A large-scale dataset called ASPED is presented, which includes high-quality audio recordings along with video recordings used for labeling the pedestrian count data. The baseline analyses highlight the promise of using audio sensors for pedestrian tracking, although algorithmic and technological improvements to make the sensors practically usable continue. This study also demonstrates how the data can be leveraged to predict pedestrian trajectories. Finally, it discusses the use cases and scenarios where audio-based pedestrian sensing can support better urban and transportation planning.
Embedding Compression for Teacher-to-Student Knowledge Transfer
Feb 09, 2024
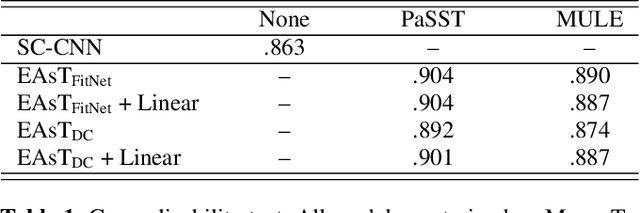
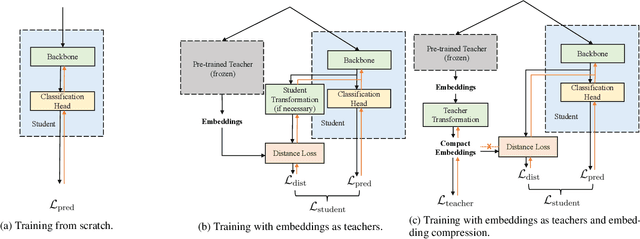
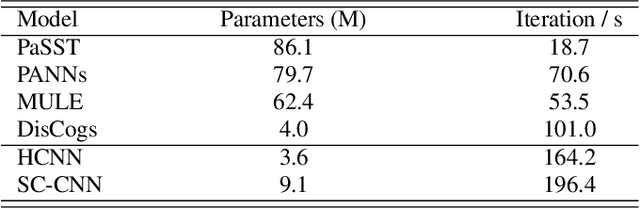
Common knowledge distillation methods require the teacher model and the student model to be trained on the same task. However, the usage of embeddings as teachers has also been proposed for different source tasks and target tasks. Prior work that uses embeddings as teachers ignores the fact that the teacher embeddings are likely to contain irrelevant knowledge for the target task. To address this problem, we propose to use an embedding compression module with a trainable teacher transformation to obtain a compact teacher embedding. Results show that adding the embedding compression module improves the classification performance, especially for unsupervised teacher embeddings. Moreover, student models trained with the guidance of embeddings show stronger generalizability.
A Generalized Bandsplit Neural Network for Cinematic Audio Source Separation
Sep 07, 2023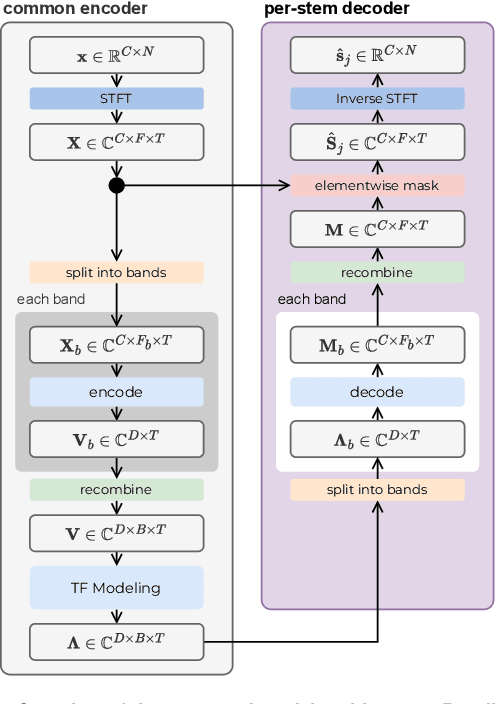
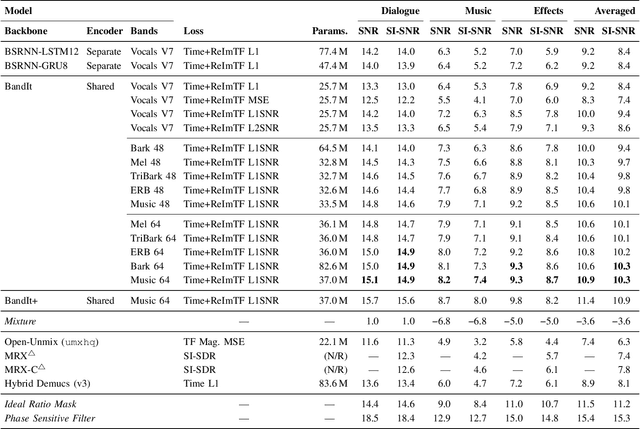
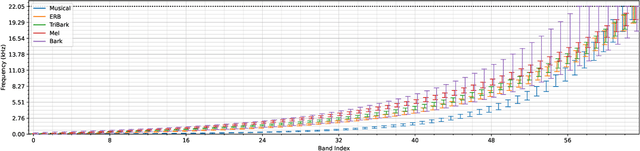

Cinematic audio source separation is a relatively new subtask of audio source separation, with the aim of extracting the dialogue stem, the music stem, and the effects stem from their mixture. In this work, we developed a model generalizing the Bandsplit RNN for any complete or overcomplete partitions of the frequency axis. Psycho-acoustically motivated frequency scales were used to inform the band definitions which are now defined with redundancy for more reliable feature extraction. A loss function motivated by the signal-to-noise ratio and the sparsity-promoting property of the 1-norm was proposed. We additionally exploit the information-sharing property of a common-encoder setup to reduce computational complexity during both training and inference, improve separation performance for hard-to-generalize classes of sounds, and allow flexibility during inference time with easily detachable decoders. Our best model sets the state of the art on the Divide and Remaster dataset with performance above the ideal ratio mask for the dialogue stem.
Audio Embeddings as Teachers for Music Classification
Jun 30, 2023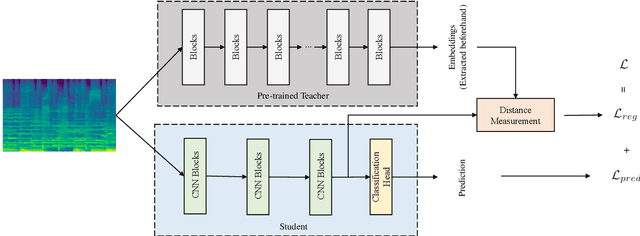
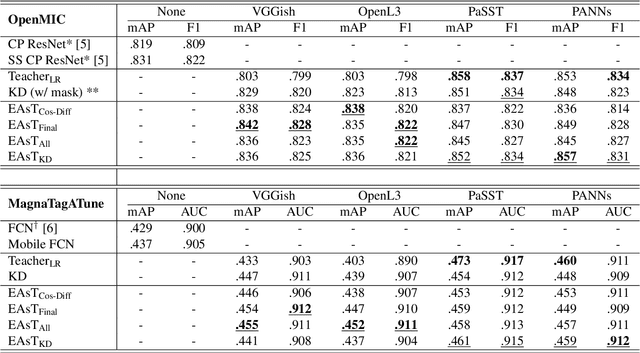
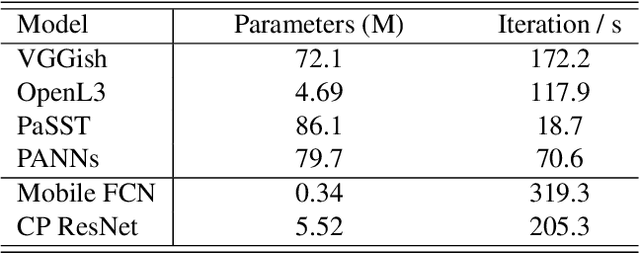
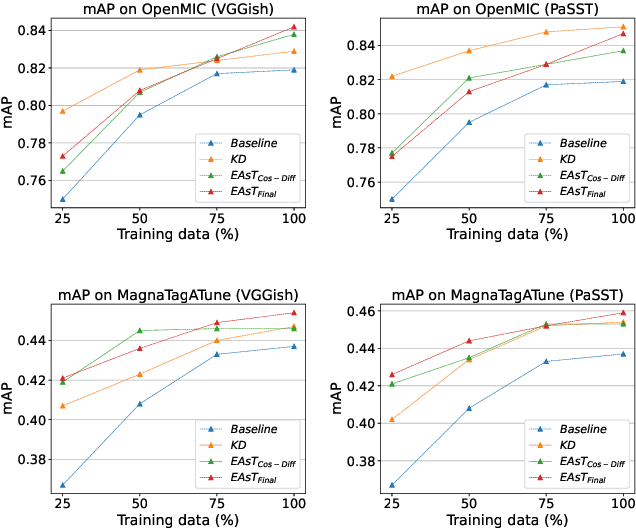
Music classification has been one of the most popular tasks in the field of music information retrieval. With the development of deep learning models, the last decade has seen impressive improvements in a wide range of classification tasks. However, the increasing model complexity makes both training and inference computationally expensive. In this paper, we integrate the ideas of transfer learning and feature-based knowledge distillation and systematically investigate using pre-trained audio embeddings as teachers to guide the training of low-complexity student networks. By regularizing the feature space of the student networks with the pre-trained embeddings, the knowledge in the teacher embeddings can be transferred to the students. We use various pre-trained audio embeddings and test the effectiveness of the method on the tasks of musical instrument classification and music auto-tagging. Results show that our method significantly improves the results in comparison to the identical model trained without the teacher's knowledge. This technique can also be combined with classical knowledge distillation approaches to further improve the model's performance.
MusicFace: Music-driven Expressive Singing Face Synthesis
Mar 24, 2023It is still an interesting and challenging problem to synthesize a vivid and realistic singing face driven by music signal. In this paper, we present a method for this task with natural motions of the lip, facial expression, head pose, and eye states. Due to the coupling of the mixed information of human voice and background music in common signals of music audio, we design a decouple-and-fuse strategy to tackle the challenge. We first decompose the input music audio into human voice stream and background music stream. Due to the implicit and complicated correlation between the two-stream input signals and the dynamics of the facial expressions, head motions and eye states, we model their relationship with an attention scheme, where the effects of the two streams are fused seamlessly. Furthermore, to improve the expressiveness of the generated results, we propose to decompose head movements generation into speed generation and direction generation, and decompose eye states generation into the short-time eye blinking generation and the long-time eye closing generation to model them separately. We also build a novel SingingFace Dataset to support the training and evaluation of this task, and to facilitate future works on this topic. Extensive experiments and user study show that our proposed method is capable of synthesizing vivid singing face, which is better than state-of-the-art methods qualitatively and quantitatively.
The DKU-Tencent System for the VoxCeleb Speaker Recognition Challenge 2022
Oct 11, 2022
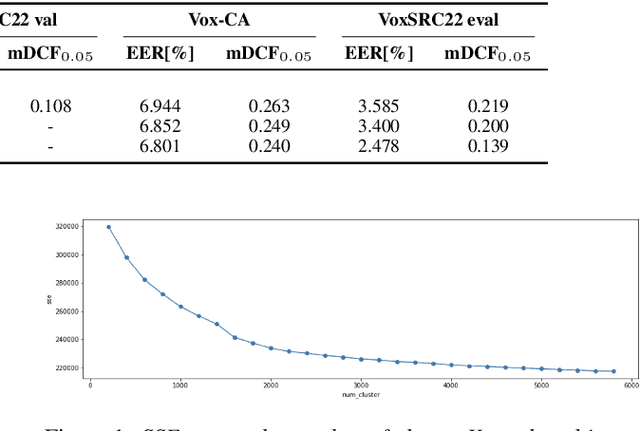
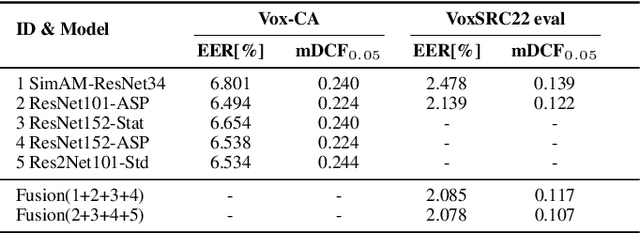
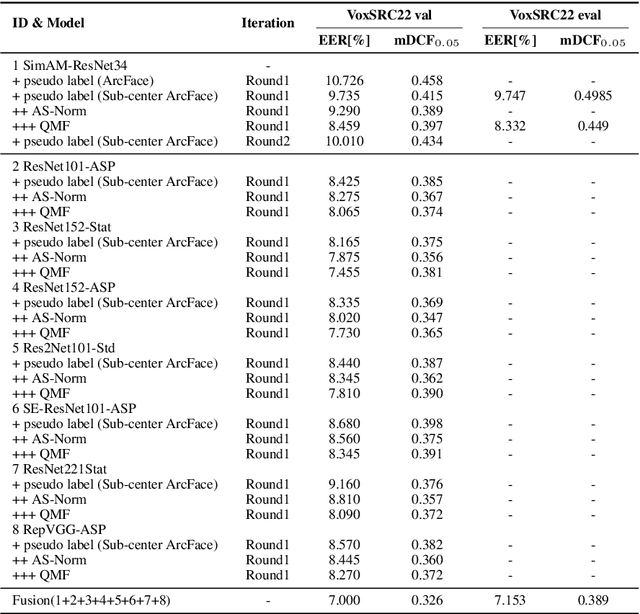
This paper is the system description of the DKU-Tencent System for the VoxCeleb Speaker Recognition Challenge 2022 (VoxSRC22). In this challenge, we focus on track1 and track3. For track1, multiple backbone networks are adopted to extract frame-level features. Since track1 focus on the cross-age scenarios, we adopt the cross-age trials and perform QMF to calibrate score. The magnitude-based quality measures achieve a large improvement. For track3, the semi-supervised domain adaptation task, the pseudo label method is adopted to make domain adaptation. Considering the noise labels in clustering, the ArcFace is replaced by Sub-center ArcFace. The final submission achieves 0.107 mDCF in task1 and 7.135% EER in task3.
I^2R-Net: Intra- and Inter-Human Relation Network for Multi-Person Pose Estimation
Jun 27, 2022
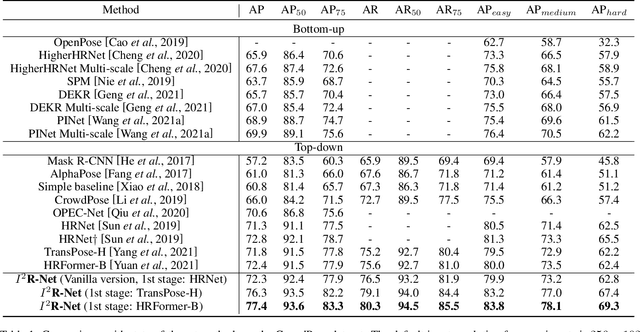
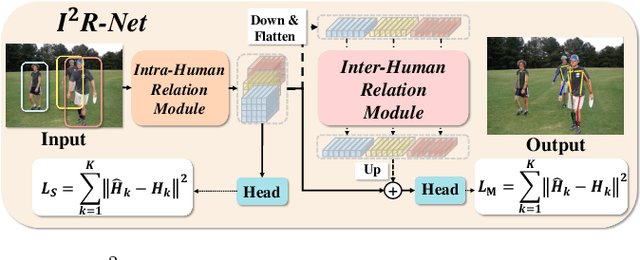
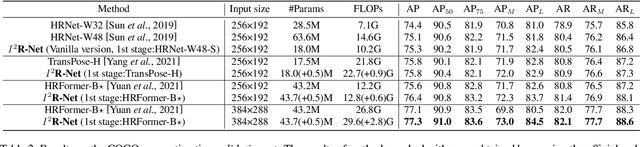
In this paper, we present the Intra- and Inter-Human Relation Networks (I^2R-Net) for Multi-Person Pose Estimation. It involves two basic modules. First, the Intra-Human Relation Module operates on a single person and aims to capture Intra-Human dependencies. Second, the Inter-Human Relation Module considers the relation between multiple instances and focuses on capturing Inter-Human interactions. The Inter-Human Relation Module can be designed very lightweight by reducing the resolution of feature map, yet learn useful relation information to significantly boost the performance of the Intra-Human Relation Module. Even without bells and whistles, our method can compete or outperform current competition winners. We conduct extensive experiments on COCO, CrowdPose, and OCHuman datasets. The results demonstrate that the proposed model surpasses all the state-of-the-art methods. Concretely, the proposed method achieves 77.4% AP on CrowPose dataset and 67.8% AP on OCHuman dataset respectively, outperforming existing methods by a large margin. Additionally, the ablation study and visualization analysis also prove the effectiveness of our model.
Rep Works in Speaker Verification
Oct 19, 2021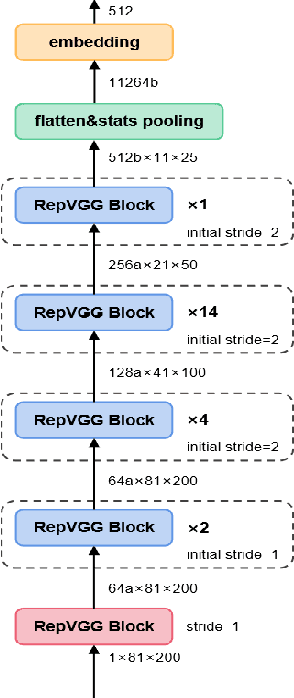
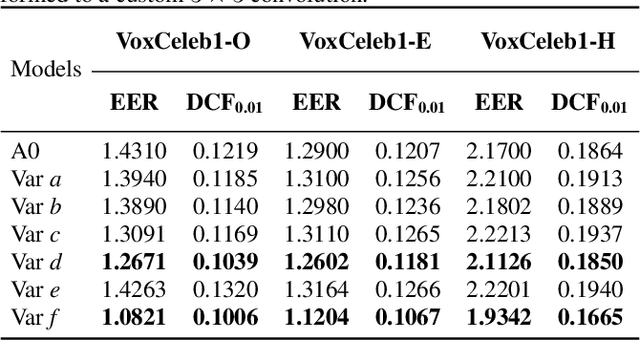
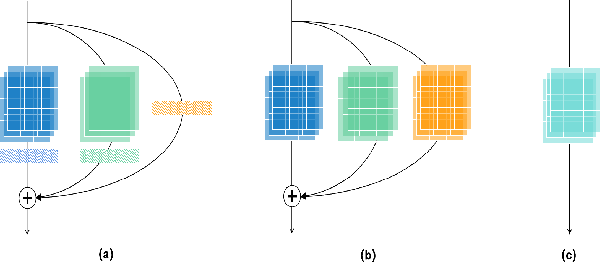
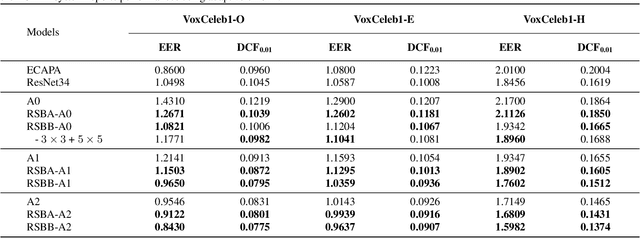
Multi-branch convolutional neural network architecture has raised lots of attention in speaker verification since the aggregation of multiple parallel branches can significantly improve performance. However, this design is not efficient enough during the inference time due to the increase of model parameters and extra operations. In this paper, we present a new multi-branch network architecture RepSPKNet that uses a re-parameterization technique. With this technique, our backbone model contains an efficient VGG-like inference state while its training state is a complicated multi-branch structure. We first introduce the specific structure of RepVGG into speaker verification and propose several variants of this structure. The performance is evaluated on VoxCeleb-based test sets. We demonstrate that both the branch diversity and the branch capacity play important roles in RepSPKNet designing. Our RepSPKNet achieves state-of-the-art performance with a 1.5982% EER and a 0.1374 minDCF on VoxCeleb1-H.
Multi-query multi-head attention pooling and Inter-topK penalty for speaker verification
Oct 12, 2021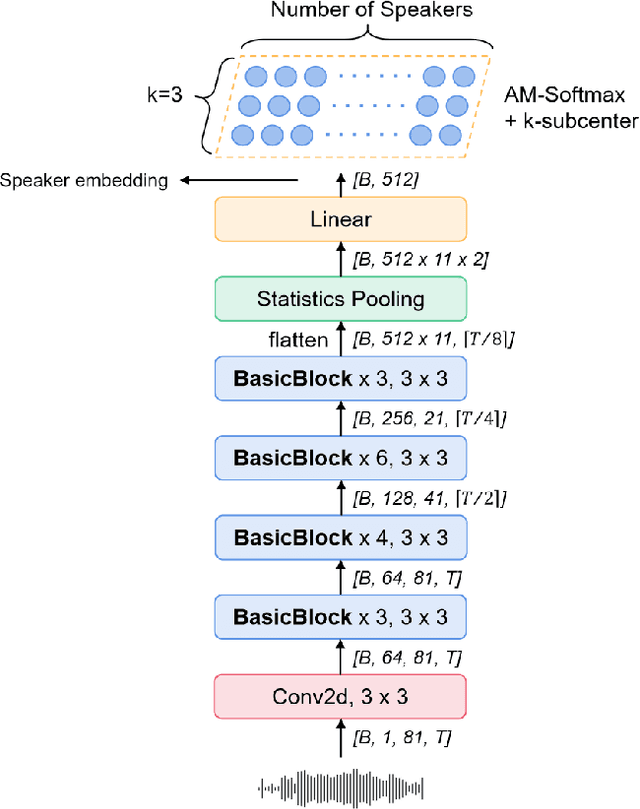
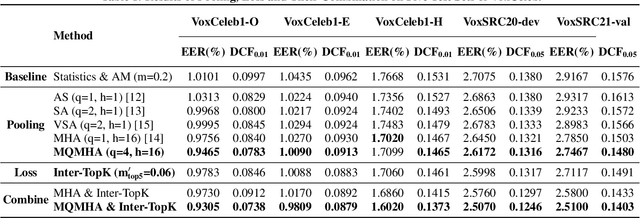
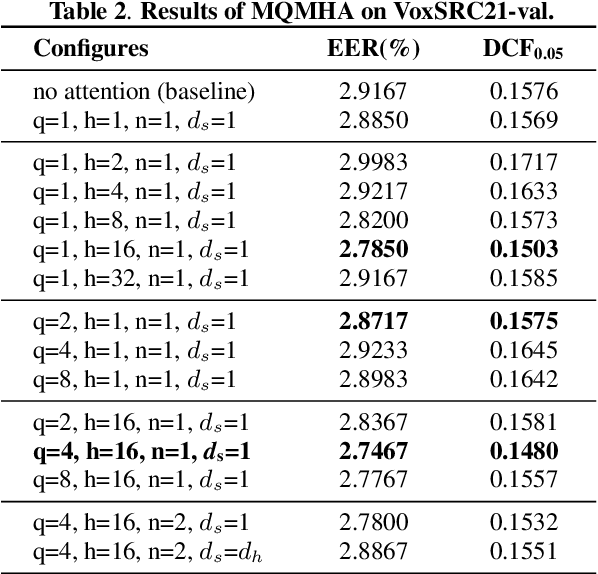
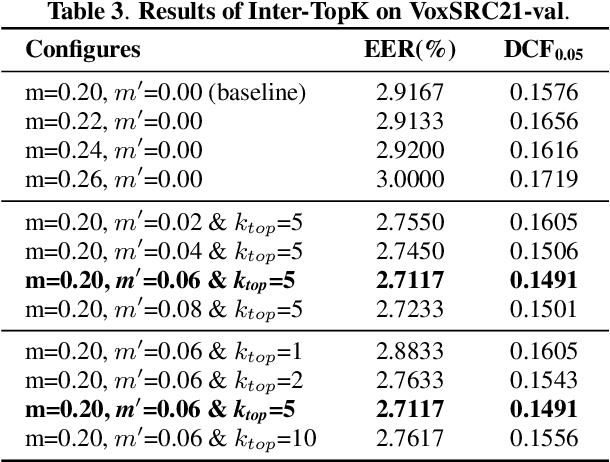
This paper describes the multi-query multi-head attention (MQMHA) pooling and inter-topK penalty methods which were first proposed in our submitted system description for VoxCeleb speaker recognition challenge (VoxSRC) 2021. Most multi-head attention pooling mechanisms either attend to the whole feature through multiple heads or attend to several split parts of the whole feature. Our proposed MQMHA combines both these two mechanisms and gain more diversified information. The margin-based softmax loss functions are commonly adopted to obtain discriminative speaker representations. To further enhance the inter-class discriminability, we propose a method that adds an extra inter-topK penalty on some confused speakers. By adopting both the MQMHA and inter-topK penalty, we achieved state-of-the-art performance in all of the public VoxCeleb test sets.